ESE
这篇论文,将之前介绍的韩松的Deep Compression技术在FPGA上具体实现。
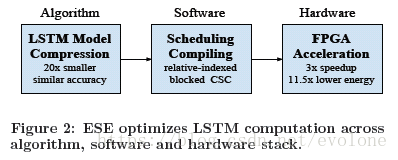
为了达到更高的效率,论文的设计从三个层次提高计算效率:算法优化,编译高效的调度程序,硬件加速。如Figure 2所示。
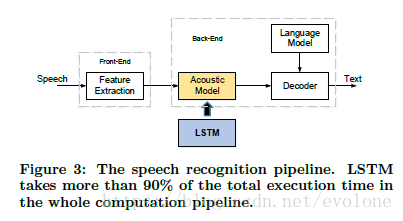
论文设计的语音识别系统中,最占用运算资源和存储资源的是LSTM算法。故论文着重优化LSTM算法的计算。
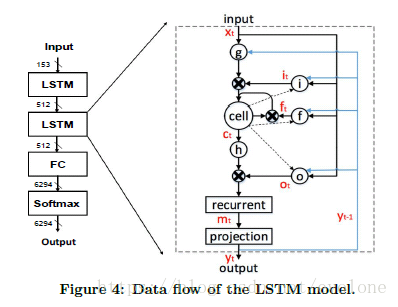
LSTM算法的数据流如图Figure 4所示。的确比较复杂。其中涉及到许多的矩阵计算以及两个向量对应元素相乘的计算。
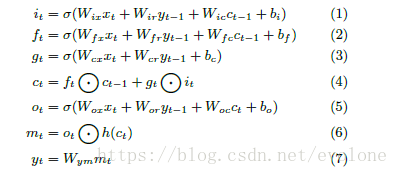
因为网络模型中的参数矩阵,本来就比较稀疏,再经过稀疏处理,就更加稀疏了,往往有超过90%的元素变成了0,这就给压缩存储带来了可能,并且能够减少总的乘法计算次数,减少计算时间。
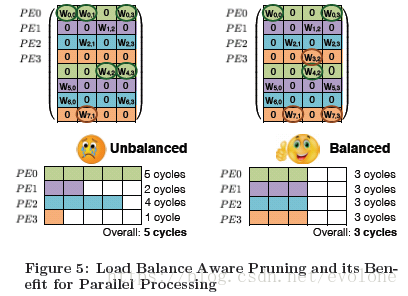
因为参数矩阵变得稀疏,而这种稀疏性往往分布是不均匀的,这样,就会给矩阵计算带来不规则性,造成计算密度不平衡。常规的硬件加速结构对稀疏矩阵的计算,并没有明显的优化,一定程度削弱了通过稀疏化带来的性能增强。如果能够在剪枝的时候,兼顾平衡矩阵稀疏的平衡,那么就可以在此提升计算效率。
如图Figure 5 所示。
在计算机编程中,对稀疏矩阵,一般采用三元法进行存储。
本文采用类似的方法存储稀疏矩阵的非0有效系数,只是仅仅考虑同一行元素之间的相对位置关系,不同行之间按照行的顺序依次存储,整体来看,是把矩阵形式的权重参数拆分成以行为单位的向量形式。
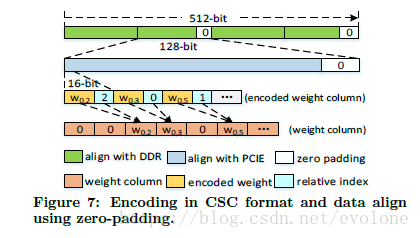
并且,因为系数量整体较大,所以在DDR中存储,并通过PCIE传输到计算单元,而DDR一次传输 512bits数据,PCIE一次传输128 bits数据,在考虑到是byte-aligned的存储方式,所以最终本文将权重weights量化压缩成了12 bits的定点数,采用4 bits编码表示相邻两个非零权重参数的相对距离,凑成16 bits。并且在数据不足的地方补零。
如图Figure 7所示。
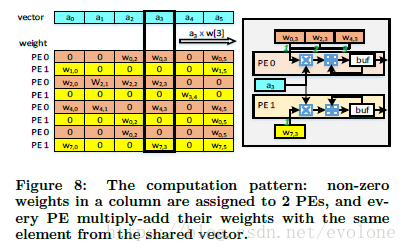
说实话,看了这篇论文之后,理解最模糊的就是下面这个图Figure 8了。一直没有理解这里描述的用意。
先把我自己的理解以及疑惑写在这里,希望有知道的大神能够指点一二。
按照论文中的描述,输入向量a有6个元素{a0, a1, a2, a3, a4, a5},对应的权重矩阵是一个8X6的稀疏矩阵W.
执行矩阵乘法,W X a = b。
那么,整个运算过程可以看作:
W[8,6] X a[6,1] = b[8,1]
其中,a[6,1]表示a是6行1列的矩阵。
整体来看,就是a的某个元素(比如a3)与W的对应列(比如W[*, 3])的所有非0元素都要相乘,也就是文中图上标注的a3 X W[3]。
虽然整个计算来看,的确是要计算a3 X W[3],但是因为W[3]的非零元素在W中分属不同的行,而计算结果应该是W的每一行分别与a的对应元素相乘累加形成一个结果,最终W X a形成一个向量b,所以这些计算是在不同时刻计算的,而且计算结果应该分属不同行。
疑惑:
但是第一眼看到Figure 8 ,我就直接认为是PE0直接计算了三个权重与a3的乘法运算,PE1计算了一个权重与a3的乘法运算。从而一直无法想通这样做的用意。
这样的好处是,这几个计算,都会采用同一个参数a3。
这样的坏处是,一个PE一个周期只能计算一次乘法,所以如果有多个乘法,就需要排队计算,而且,这些乘法的计算结果之间并无直接关系,需要存储起来,之后按照行将计算结果累加。
如果真是这样的设计,那么两个PE执行了a3 X W[3]后,计算结果之间是毫无关系的,需要存储在act buffer中。这样需要一定空间的芯片内存储资源。另外因为计算结果分属不同的行,所以还必须有控制逻辑去准确调度计算结果的存储及读取,这个往往更难。
真这么做,感觉得不偿失。
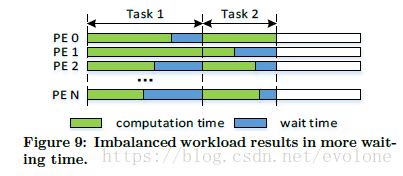
因为权重矩阵的稀疏性,造成每个PE上的计算负载不平衡,又因为这些PE会共享输入向量,所以,必须等都计算完成,才能切换到下一个输入向量,这就会造成计算任务少的PE会有比较长的等待时间,如图Figure 9所示。
下面介绍整个硬件加速系统,如图Figure 10(a)所示。
这是CPU+FPGA的混合结构。
因为计算用到的数据量大,需要额外的存储芯片。
CPU中运行控制程序。
FPGA中运行硬件加速器ESE。
CPU通过PCIE与FPGA交换数据。
外部存储芯片通过MEM Controller 与FPGA交换数据。
可以看出,FPGA中的ESE加速器,主体结构是由多个Channel组成,每个Channel由多个PE组成。ESE加速器的输入输出都有buffer来缓存数据。整体上看,结构设计与谷歌的TPU有些类似。
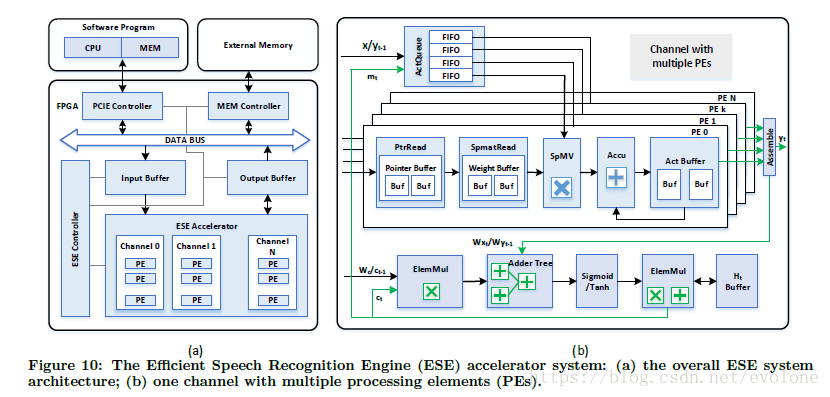
设计的核心在于每个Channel中的设计,如图Figure 10(b)所示。
图中的SpMV就是核心模块,其他模块可按照配合SpMV的先后顺序做介绍。另外,ElemMul(每个元素对应相乘)与激活函数都不是关键路径,所以这里就不再重点介绍。
SpMV有两个输入,一个是输入数据,这个由上方的ActQueue提供,另外一个是权重参数,这个由SpmatRead及PtrRead提供。
ActQueue,内部有n(n为单个Channel中PE的个数)个16 bits 宽的FIFO,深度1~16,这个由实际试验求得,原则是不影响延迟的情况下选择最短的深度。每个FIFO中存放的是与一行权重参数中非零元素对应相乘的输入数据,专门输入同一个PE。
猜测:
ActQueue每次取来一个Vector a,每个PE根据各自的SpmatRead及PtrRead中提供的某一行中非零权重元素的位置,对应获取Vector a中的元素aj,并存入对应的FIFO(或许会出现同一个元素aj在某个FIFO中出现多次的情况,这样就必须要求ActQueue中的Vector a的单个元素必须支持同时最大n个FIFO的同时读取)。这样PE中的SpMV就只管计算非零的乘法。而因为FIFO的存在,可以避免PE之间负载不均衡导致的等待时间。
PtrRead中的指针按照2个一组存放,一个头指针pj,一个尾指针pj+1,两个指针联合起来指明一行(W[j , *])权重参数中非零参数的开始位置和非零参数的数目。
SpmatRead用pj和pj+1去查询行W[j , *]中的非零元素。
SpMV计算得到乘法结果,送到Accu中累加,中间结果存储到Act Buffer,等一整行的非零元素的乘法结果都累加起来之后,将所有PE的计算结果收集起来,要么作为最终的输出结果y,要么作为中间结果,送到Adder Tree,做加法,比如加上bias。然后将结果送入激活函数处理,之后传入ElemMul中处理。
可以看出,整个PE内部的设计,是完全为了贴合LSTM计算。
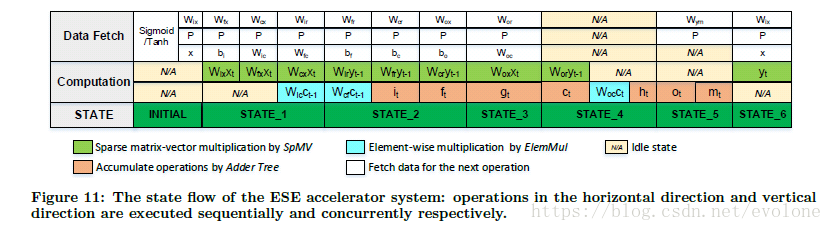
Figure 11详细划分了LSTM算法的计算过程,包括计算类型和计算先后顺序。
按照表格的行方向,从左往右,是时间先后顺序,由于有先后依赖关系,这会对计算调度形成要求。
按照表格的列方向,同一列,表示可以同时并行计算,但是如果存在计算资源冲突,那么还是无法真正并行计算。
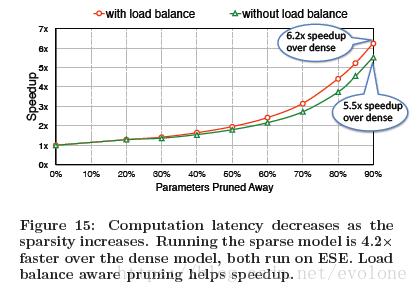
说了这么多,最后来看看实际效果,见图Figure 15.
整体来说,因为稀疏性,最终可大幅度删减90%权重参数,而并不明显影响模型精度,而此时,跟原始稠密的计算相比,速度提升了5.5倍,如果加入本文提出的load balance技术,那么可以进一步加速到6.2倍。
总的说来,效果还是很明显的。