背景:FPGA2017的最佳论文为深鉴科技的ESE,把稀疏网络的FPGA实现给出了丰富的参考意义。
目的:详细解析ESE Efficient speech recognition engine with sparse LSTM on FPGA论文。
论文地址:https://arxiv.org/abs/1612.00694
目录
3.3 wegiht与activation 的quantization
一、摘要
1.1 motivation
LSTM(long short term memory)被广泛应用于语音识别领域
但为了获得更好的识别效果,LSTM模型通常过大,这会导致:
- 存储消耗
- 运算消耗
- 对于数据中心的较大的TCO(Const of ownership)
1.2 贡献点
- 剪枝与量化应用于LSTM,剪枝时用到了负载平衡(load balance),将LSTM带来了大量的压缩20x(剪枝10x,量化2x)
- 提出了一个sheduler,用于编码和分组相应的复杂的压缩的LSTM,分配给PE(Processing Element处理单元)
- 设计相应的ESE硬件模块,可以直接应用于sparse LSTM
1.3 实现
- 实现在Xilinx XCKU060 FPGA上,200MHz时钟
- ESE在sparse LSTM取得了282 GOPS处理速率,相当于非稀疏的2.52 TOPS的处理速率。
- 在语音识别的数据集上ESE取得了比core i7 5930和titan X GPU快43x的3x的速度提升
- 比CPU和GPU能耗降低40x和11.5x
1.4 实现流程

传统的方法是将相应的神经网络直接部署于嵌入式设备上,导致运行速度慢,并且能耗高。
training ——inference
本文采用的方法,先用sheduler进行软件端的压缩,然后进行硬件端的部署从而获得了更好的速度与能效。
training——comprssion——accelerated inference

算法端压缩,用shdeuling的方法将其压缩,并且用稀疏矩阵用CSC的方法进行存储。然后硬件端用FPGA加速。
二、背景 LSTM
2.1 模型概览

如上图 figure 3,包含了两个单元 front-End, Back-End单元。
- Front-End: 前端从语音信号之中提取特征
- Back-End:后端处理相应提取出的特征并且完成从speech到word的转化。
Back-end包含了:
- AM:acoustic model(声学模型)
- LM:language model(语言模型)
- decoder
这里LSTM主要用于acoustic model
2.2 模型实现
通过front-end前端提取出的特征被用于AM:acoustic model(声学模型)
然后通过解码器运用AM和LM来运用MAP(maximum a posteriori probability最大化后验概率),从而预测相应的语音:

其中:
- X表示提取出的特征,是一个向量X=X1X2X3...Xn
- 目标是words,W=W1W2W3...Wn
- 最大化的是后验概率P(W|X)
因为特征X已经固定,所以上面的方程可以写为:

上面这两个P(X|W)和P(W)分别是由AM声学模块和LM语言模块得出。
2.3 LSTM
实现过程中,LSTM架构被广泛应用于大规模的语言识别模型。LSTM也是语音识别模块之中最耗费存储和耗费运算的部分。
LSTM的数据流如下图所示:

- LSTM是RNN的一种,输入的时刻T取决于在T-1时刻的输出,
- 与传统RNN的不同在于,LSTM在recurrent hidden layer中多了一个特殊的记忆模块memory block
- 在memory block之中包含着当前网络的状态(temperal state of network)
- memroy block包含着许多个单元,input gate,output gate,forget gate
例如上图之中:
- input gate i 控制着流入记忆单元的数据
- output gate o控制着流入到剩余网络之中的输出
- forget gate f scales the internel state of the cell before adding it as input to the cell, which can adaptlvely forget the cell's memory. 遗忘门会在输入其input之前scales 当前cell的状态,从而达到遗忘的目的。
LSTM的一系列输入为x=(x1:x2:x3:...:xT), 获得一系列输出 y=(y1:y2:y3:...:yT):

其中,
- O中间一个点表示 element wise multiplication
- W 表示权值矩阵,Wic,Wfc,Woc都是peephole connections的diagonal weight
- b表示偏置bias vector
- sigema 表示logistic sigmoid 函数
- i,f,o,c, m表示input gate,forget gate,output gate,cell activation vectory,cell output activation vector。他们都具有同样的size
- g与h表示cell input与cell output 的激活函数。
三、模型压缩
模型压缩部分与deep compression高度相关:
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman coding 论文详解:
https://blog.csdn.net/weixin_36474809/article/details/80643784
3.1 剪枝
权重绝对值小于某个值,就剪掉这个权重:此部分详细参考Deep compression

在Kaldi speech recognition数据集上进行相应的剪枝操作,关于剪掉的比例与精度损失parameters pruned away and phone error rate (PER)如图6所示:

剪枝掉93%的数据依然有很好的准确率。在TIMIT数据集上,我们的权值运用了90%的稀疏率。
3.2 基于负载平衡的剪枝
为了更好的执行稀疏矩阵的并行化,我们实施相应的基于负载平衡的剪枝方法。
关于负载平衡的问题,在EIE之中有讨论:

则根据木桶短板效应,并行化之后最慢的PE是所有PE的时间的时长。

基于负载平衡的剪枝就是解决解决这个问题的,在剪枝的过程中,我们将权重的稀疏性定义为10%,然后避免其中的子矩阵低于5%或者大于15%,这样,有利于不同PE之间的负载平衡。
3.3 wegiht与activation 的quantization
我们进一步的压缩32bit的浮点数到12bit定点,然后运用线性的量化来实现于weight和activation
在权值量化的部分,权值分布的dynamic range在每层LSTM之中会被预先分析,以免数据溢出。

权值在不同比特数下的量化。我们用查表和Linear interpolation来实现相应的激活函数,例如sigmoid或者tanh,然后分析相应的dynamic range。然后我们探索用于维持精度的最小的量化的比特数。12bit数之下可以达到没有精度损失。

对于激活函数中的sigmoid或者tanh,采样的分布分别为从[-64 64]和[128 128], 输出为16bit with 15bit的十进制数
TIMIT展示在table 4之中

四、编码与编译
LSTM的运算包括稀疏矩阵的相乘,element wise的multiplication,与memory reference。我们设计一个数据流来实现确定相应的硬件工作。
数据根据所在的行被分成n个block,n是PE的硬件加速模块的一个channel,刚开始的n个行被放入n个不同的PE之中,n+1行被放入第一个PE之中,入错循环。这样可以保证矩阵的第一部分会被第一时间读入,也会在后面的运算之中迅速实现。
(这里可以参考EIE之中,讲的更详尽一些,摘录过来)

这是一个稀疏矩阵相乘的过程,输入向量a,乘以矩阵W,输出矩阵为b,然后经过了ReLU。
用于实现相乘累加的单元称为PE,相同颜色的相乘累加在同一个PE中实现。例如上面绿色的都是PE0的责任。则PE0只需要存下来权值的位置和权值的值。所以上面绿色的权值在PE0中的存储为下面这样:

通过CSC存储,我们可以很快看出virtual weight的值。(CSC不懂见上一节推导)。行标与元素的行一致,列标可以恢复出元素在列中的位置。
向量a可以并行的传入每个PE之中,0元素则不并行入PE,非零元素则同时进入每一个PE。若PE之中对应的权重为0,则不更新b的值,若PE之中对应的权重非零,则更新b的值。
因为DDR上的对齐问题,所以作者采用16 bit的数据。量化后的权重
下图为csc来存储稀疏矩阵的实现。关于CSC具体可以参考deep compression中的关于CSC的部分。

稀疏矩阵的存储
稀疏权值矩阵的存储:比如我们这个稀疏的矩阵里面,n×n的矩阵,里面大多数的值是零值,然后我们通过相应的存储稀疏矩阵的方式对这个矩阵进行存储。首先把所有的非零值存为AA,假设所有的非零值的元素的个数为a,然后把每一行第一个非零元素对应在AA的位置存为JA,最后一个数是所有非零元素的个数+1,所以JA中的元素就是行数n+1,然后把AA中每一个元素在原始矩阵中的列存为IC。所以我们把一个原始的n×n的稀疏矩阵存为2a+n+1个数字。

剪枝之前的矩阵是非稀疏的矩阵,例如一个n*n的矩阵,经过剪枝的过程之后,这个n*n的矩阵就变为一个n*n的稀疏矩阵,其中很多零值。可以采用CSR或者CSC的方法对这个矩阵进行存储从而减少相应的存储量。
例如CSC的存储稀疏矩阵的方法
第一行AA存储所有的非零元素,
第二行JA存储所有系数矩阵中每行第一个非零元素在AA的位置,例如第一个元素是4.0,在AA中位置是第一个,第二行第一个元素是4.0,在AA中位置是第四个。通过JA可以将AA中所有元素对应的行恢复出来。
第三行JC是所有元素对应的列标。
这样,一个稀疏的矩阵通过三行就能存下来,达到了很好的存储压缩。由N*N变为了2a+N+1个元素
相对位置的参数:在压缩完参数之后,我们存了权值和权值对应的参数。之前的参数存的是绝对的参数,我们现在存相对的参数,就是两个参数的差值,比如我们用三个特存相对的参数,只要两个元素的距离小于8,都能把参数存为3个比特的,如果两个参数的距离大于这个值,我们就在第8个位置设置一个0值。
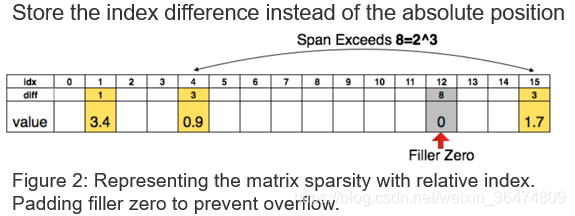
通过CSC得到了压缩的矩阵,可以通过差分存储进一步压缩存储数量。例如我们想用三比特的值来存储相应的Index。
3bit可以容忍的间距为8
- 当间距小于8时:用3比特的值就可以恢复出相应的位置
- 当间距大于8时:在第8个位置插入0值,然后用3bit的与插入的0值的差分位置恢复出相应的位置
- 间距大于8的倍数时:每隔8个位置插入0值,与最后一个0值的3bit的差分位置恢复出位置
五、硬件实现
5.1 硬件实现的难点
- 压缩后的运算是不规则的卷积运算,与正常的卷积不同,压缩后的网络实现是稀疏的卷积,并且量化之后相应的权值和参数需要通过byte对齐。我们将4bit的指针与12bit的权值分成一组存入2个byte(2byte=16bit)
- 稀疏之后需要实现负载平衡。
数据序列与负载平衡
上图之中的连接PE与CCU之间的序列。如果CCU直接将数据广播入PE,则根据木桶短板效应,最慢的PE是所有PE的时间的时长。
- 普通的处理器难以实现压缩后的LSTM的并行。
FPGA实现的难点
- 定制的解码电路需要从稀疏的权值矩阵之中恢复出原始的权值矩阵,但是其中的参数是相对的参数(压缩的过程中为了达到更好的压缩,所以采用相对参数作为指针,不懂的可以回看Deep compression之中的压缩的部分)。所以需要通过累加来恢复出绝对地址,我们用4bit来实现相对地址偏移,如果相对地址偏移大于16,则最大的加入一个补零。(这部分也是Deep compression的量化部分的内容。)
- 数据的表示必须很小心的对齐,例如调用外部的DDR存储接口的时候。并且不同的bit精度之间的运算在硬件之上是难以实施的。不同层之间需要bit shift的转换。
- 控制器(sheduler)需要被精心设计,因为LSTM的数据流实现非常复杂并且权值之间有很多不同。有些需要被同时执行,有些需要按顺序执行。
- 硬件的设计必须满足LSTM的多通道实现,这样才能并行的实现LSTM。
5.2 系统实现概览

此图展现了一个ESE系统的概览,实现由三部分组成,1 FPGA的加速器,2 CPU上的软件程序,3 FPGA板子上的外部存储
软件端
由CPU和相应的内存组成,通过PCI-Express总线与FPGA通信。初始化阶段向FPGA传输LSTM模型的参数。会向FPGA传输语音信号和从FPGA获得已经得到的结果。
外部存储
外部存储存储着所有参数和voice vector。因为BRAM的数量限制,所以LSTM不能够全部的放入BRAM之上。所以加速器需要通过内存控制器(MEM controller)来通过MIG(Memroy interface generator)实现内存的接入。
FPGA芯片
FPGA芯片上实现了相应的ESE加速器,ESE 控制器, PCIE 控制器,内存控制器,与片上buffer。
ESE加速器包含PE单元,用于实现LSTM网络中的大部分功能。

- 片上buffer用于输入和取出PE需要的数据
- ESE控制器用于控制FPGA上面电路的运行,控制和shedule相应的PCIE/MEM 控制器。
- DRAM内存器用于存入和写出FPGA加速器的信号
5.3 ESE控制器(sheduler)
最耗费的是稀疏矩阵相乘的单元。我们将LSTM之中的稀疏矩阵相乘的公式写为Table 5的实现模式。

上面为相应的矩阵相乘的公式。
LSTM要实现复杂的数据流。图11就是显示一个sheduler需要实现的部分。


此部分涉及较多硬件内容,我后续补充解析。
5.4 ESE channel architecture

ESE的结构与EIE非常类似,可以参考下EIE做个类比:
https://blog.csdn.net/weixin_36474809/article/details/85326634
上面这张是架构图,图中具体的结构实现不同的功能,下面解释每个模块的作用:
ActQueue
activation vector queue激活队列
关于负载平衡的问题,韩松在EIE之中详细的讲过。
所以我们在每个PE之前设置一个队列,用于存储,这样PE之间不同同步,只用处理各自队列上的值。
- 只要队列未满,CCU就向PE的队列广播数据
- 只要队列之中有值,PE就处理队列之中的值
这样,PE之间就能最大限度的处理数据。一定程度上解决了负载平衡的问题。
SpmatRead
稀疏矩阵读取单元,sparse matrix read,分为指针读取单元和稀疏矩阵读取单元,用于编码权重矩阵的存储和输出。
SpMV
SparseMatrix-vectorMultiplication,稀疏矩阵相乘单元,
ElemMul
元素级别的乘法单元。每个通道上设置16个远东是级别的乘法器。
Adder Tree
用于累加结果和偏置bias
Sigmoid/Tanh
非线性的激活函数。
5.5 存储系统

运用4GB的DDR3作为DRAM来实现为片外的存储。在上图之中分别交DDR_1和DDR_2

六、实验
6.1 平台及设置
ESE实现于XCKU060的FPGA上,时钟设置为200MHz。外部存储采用 4GB的DDR3.
运用TIMIT数据集来测评相应的效果,这个数据集包含了630个人的美国英语的8个主要的方言。用1000小时的音频训练,100小时验证,10小时测试。
实验的baseline设置为用 i7-5930k CPU和Pascal Titan X GPU和MKL BLAS/cuBLAS的CPU/GPU的系数矩阵相乘。
运用MKL SPARSE/ cuSPARSE 与CPU/GPU作为稀疏矩阵相乘的实现。
6.2 资源利用
table 6展示了ESE运用32通道设计的资源占用。其实现为32个通道,并行32块PE,在XCKU060的FPGA上。
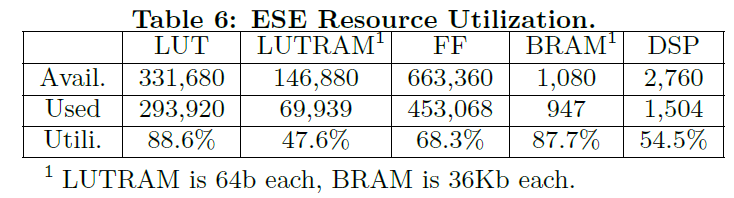
根据实验得出的最好的并行的PE个数为32

FIFO深度
FIFO就是激活队列的问题,韩松已经在很多文章中探讨过。

6.3 准确率,速度与能效



七、个人总结
本篇文章贡献点与EIE类似。都是在稀疏的基础上压缩模型,运用稀疏相乘实现于硬件之上。
但是有两个创新点值得我们参考:
- 之前的普通的DNN或者CNN现在变为了LSTM,而LSTM的架构为RNN架构,所以与CNN或者DNN的架构非常不同。这是本文在模型方面的创新。可以看出作者在LSTM模型上做的调整。
- 之前的EIE用的是ASIC的方法,而这篇文章用的的FPGA,FPGA周期和成本都比ASIC好很多,并且给出了我们稀疏网络实现的参考。