前言
(作者原创,未经允许不得转载。)
最近在研究人工智能芯片架构,反复分析了谷歌公开的TPU ( Tensor Processing Unit) 专利,从中获得些许感悟,记录下来,以备之后查看,也方便广大知友查阅。
特此感谢谷歌的分享。
其实人工智能从06年深度学习的出现,就踏上了再次崛起之路。如果说,IMGNET的举办是快速推进深度学习的发展,让深度学习在图像识别领域大火特火。那么,alphaGO的横空出世,则正式将深度学习带入千万平常百姓家。
深度学习模型,采用人工神经元,形成多层的神经网络结构,经过大量数据及迭代次数的训练,形成具有一定识别功能的模型。
因为需要海量的训练数据及大量的迭代次数,需要大量的计算力。这个计算力,可以粗略看作单位时间内能做多少次浮点乘加运算。
目前的处理器,比如CPU,GPU,其计算力已经能够满足大部分的常规应用。但是,深度学习的出现,使得原本计算力看似充盈的CPU捉襟见肘,只剩GPU独挑大梁。但是,GPU目前几乎由NVIDIA独家垄断,售价高昂,且GPU并不是专门针对深度学习而设计的ASIC (Application Specific Integrated Circuit, 专用芯片),其能效还有巨大的提升空间。
于是,设计一种深度学习专用的ASIC,成为了必然。
谷歌掌握世界上最大的搜索引擎,积累了大量的数据,估计是世界上最早处理大量运算的公司之一,并且谷歌拥有目前全球领先的深度学习团队DEEPMIND(alphaGO的发明者),所以自然而然较早地预见到了当前计算力的不足。
于是,勇开先河的谷歌开始自己研发深度学习ASIC芯片:TPU(Tensor Processing Unit,即张量处理单元)。
既然是ASIC,就有必要先了解下目标问题的需求。
目前的深度学习模型,几乎都是基于多层神经网络,包括输入层,隐含层和输出层。其中隐含层又可分为卷积层,池化层,全连接层等不同结构,或多个不同结构的组合。
现在深度学习应用最广泛的当属图像识别,而实现图像识别的最重要的就是卷积层。卷积计算,就是一系列数据的乘累加。其他的诸如池化层,全连接层等,都可以化作乘加运算去实现。所以,若能高效实现大量的乘累加计算,就能明显加速深度学习。
谷歌的TPU就是去高效计算大量的乘累加运算。
本着学习借鉴的态度去查阅TPU的资料,然后在相关文档/博客中陆续知道了谷歌TPU公开的几个专利和文章。
专利,比如:
(1)NEURAL NETWORK PROCESSOR
(2)COMPUTING CONVOLUTIONS USING A NEURAL NETWORK PROCESSOR
(3)BATCHING PROCESSING IN A NEURAL NETWORK PROCESSOR
(4)PREFETCHING WEIGHTS FOR USE IN A NEURAL NETWORK PROCESSOR
(5)VECTOR COMPUTATION UNIT IN A NEURAL NETWORK PROCESSOR
(6)ROTATING DATA FOR NEURAL NETWORK COMPUTATIONS
文章,比如:
(1)In-Datacenter Performance Analysis of a Tensor Processing Unit
其中第一个专利(NEURAL NETWORK PROCESSOR)是核心,其余几个专利都是在详细介绍具体细节用到的专利技术。
下文分析TPU的结构设计,都是参考上面的几个专利。有兴趣的朋友可以谷歌学术或百度学术下载查看。如果还有其他专利和文章,请知道的朋友知会一声,一起学习进步。
1.TPU总体结构
首先,根据谷歌公布的TPU文章(In-Datacenter Performance Analysis of a Tensor Processing Unit),从整体上认识TPU的结构及功能。
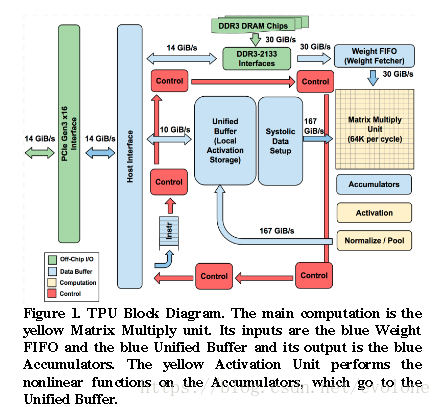
上图是文章(In-Datacenter Performance Analysis of a Tensor Processing Unit)中提供的TPU的模块图。
整个TPU的核心是由乘加器组合形成的256×256的运算器阵列:乘法矩阵(图中右侧黄色正方形代表的模块)。
为什么这么说呢?
因为TPU中其他模块,都是围绕乘法矩阵在工作,或者给乘法矩阵提供输入数据(比如,待处理的像素数据和滤波器的权值),或者接收乘法矩阵的输出。
乘法矩阵的具体功能暂且不表,先认识一下TPU内部的其他的模块。
乘法矩阵周围的上下左三个方向的浅蓝色模块,功能各不相同:乘法矩阵上方是用作滤波器权值输入的fifo,乘法矩阵左侧是输入像素数据的buffer,乘法阵列下方是接收输出乘加结果的累加器。存储滤波器权值的fifo,接收来自DDR3_DRAM接口(图片上方的绿色模块,绿色模块代表片外芯片)的权值数据。累加器将多个channel的像素的乘加结果累加计算得到当前执行计算的神经网络层的输出像素点,经过激活函数处理,然后再根据模型需要,选择是否进行池化/标准化等操作,然后将处理后的数据存储入乘法矩阵左侧的输入像素buffer。
另外,第一层神经网络的输入像素数据是来自外界的原始图像,所以TPU采用PCIE总线(图中左侧的绿色矩形)将数据传输到buffer。
当然,TPU内部这么多模块能正常工作,自然需要一整套的控制系统,图中红色模块所示。
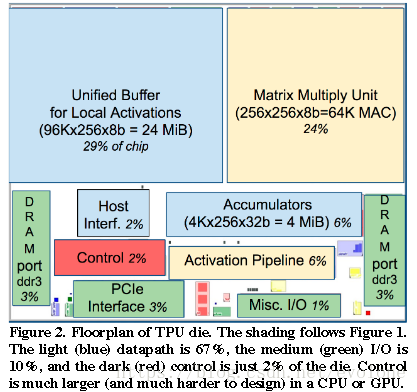
上图是文章(In-Datacenter Performance Analysis of a Tensor Processing Unit)中提供的TPU芯片的模块图,反映了各模块占用的芯片面积。可以看出,TPU中有大量的片内存储用于保存乘法矩阵的输入像素数据,占用29%的面积。另外,乘法矩阵同样占用大量面积,达到24%。
在专利中也有TPU的整体结构图。
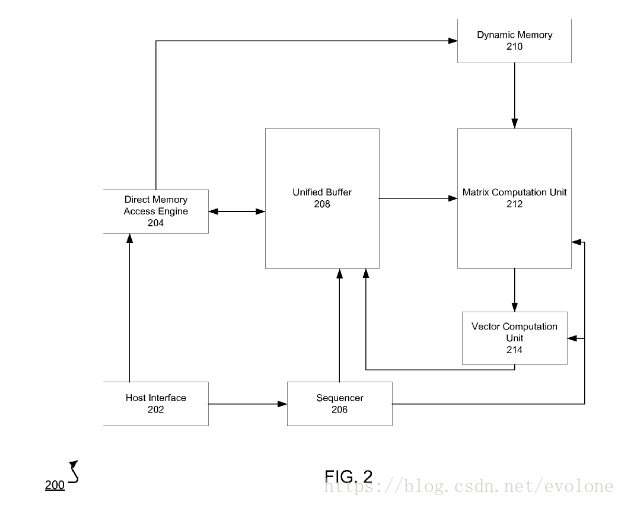
上图是专利(NEURAL NETWORK PROCESSOR)中的TPU整体结构图,其实与上面文章中的结构图大同小异,就不多费唇舌了。
2.TPU的核心结构:乘法矩阵
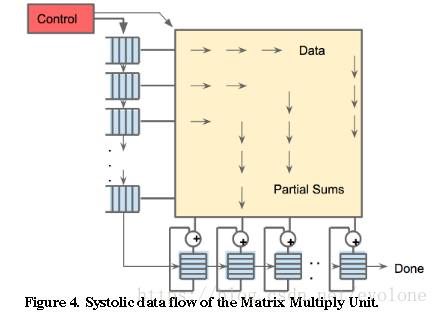
上图是文章(In-Datacenter Performance Analysis of a Tensor Processing Unit)中提供的乘法矩阵概念图。
虽然很粗糙,但还是可以窥探一二。可以看出,输入的像素数据从乘法矩阵左侧进入,并从左向右传播,重复利用输入的像素数据,经过乘加单元形成的部分和,沿着从上到下的方向传输,在乘法矩阵下方输出部分和,然后经过累加器累加形成最终的结果。
谷歌采用的乘法矩阵结构,本质上是脉动矩阵。
脉动矩阵的概念提出很多年来,因为需要应用于比较规律的场景,所以一直没有特别突出的实际应用。现在,深度学习的火热,引入了大量的规律的乘加运算,特别适合采用脉动矩阵进行高效的乘累加运算,计算神经网络算法中的卷积或全连接等运算。
文章中的乘法矩阵结构图比较粗糙,但是在专利中就比较具体了。
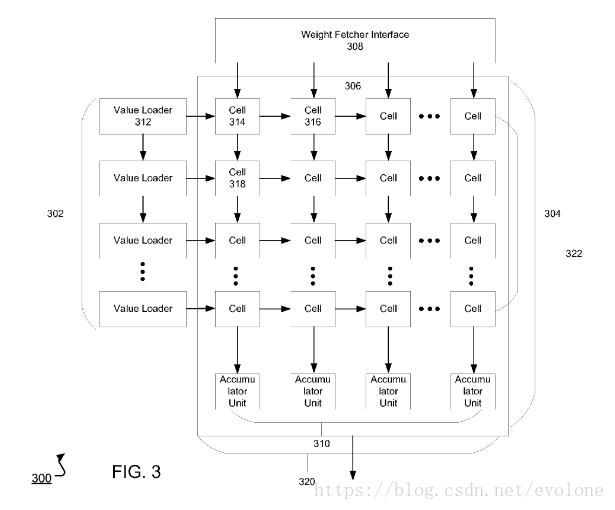
上图是专利(NEURAL NETWORK PROCESSOR)中提供的乘法矩阵结构图。
可以清晰看到,乘法矩阵采用的是脉动矩阵,图中的每一个CELL就是一个乘加单元,乘法矩阵的左侧每一行的像素输入会按照行的方向从左到右传播,乘加单元形成的部分和会沿着列的方向从上到下传播。每一列乘法器的最后的输出都给到一个累加器。
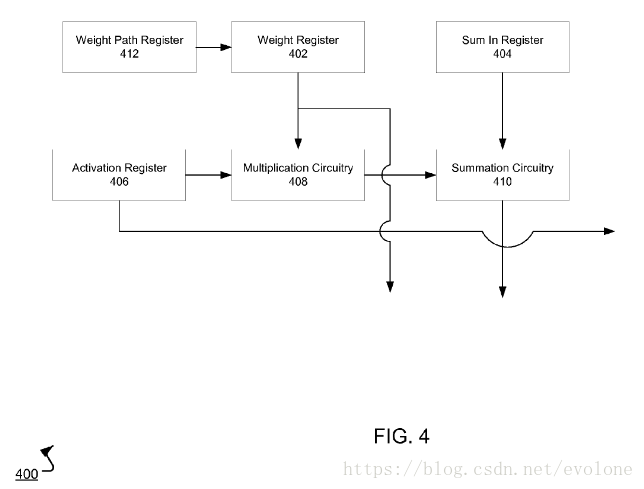
上图是专利(BATCHING PROCESSING IN A NEURAL NETWORK PROCESSOR)中的cell结构图:每一个cell都包含了一个乘法器和一个加法加法器,以及部分寄存器。
每个cell,执行的功能是A×B+C。其中,A代表从左侧输入的像素数据,B代表从上方cell得到的滤波器权值,C代表从上方cell得到的输出部分和。
可以清晰看到,从左侧传来的像素输入数据,会传递到右侧的相邻cell。滤波器权值会传递给下方的cell。从上方cell得到的部分和,作为当前cell的加数C。当前cell输出的部分和,会传递给下方的相邻cell当作加数C。
3.TPU乘法矩阵工作原理
下面来看看这个脉动矩阵是怎么工作的。
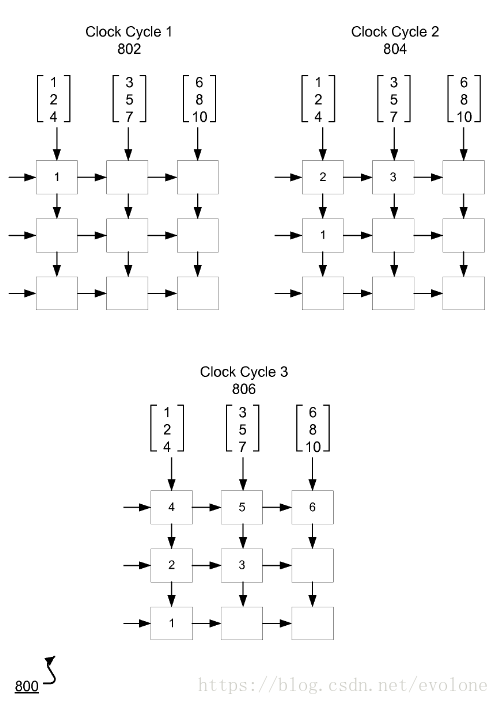
将深度学习用于图像识别,输入的原始数据就是图像,若是黑白的图像,那么数据只有一个channel;若是彩色的RGB图像,那么一张图片有三个channel组成,分别代表红(Red),绿(Green),蓝(Blue)。其实,黑白的图像是彩色RGB图像的一个特例,就是当彩色RGB三个channel的数据一模一样时,就成了黑白图像。
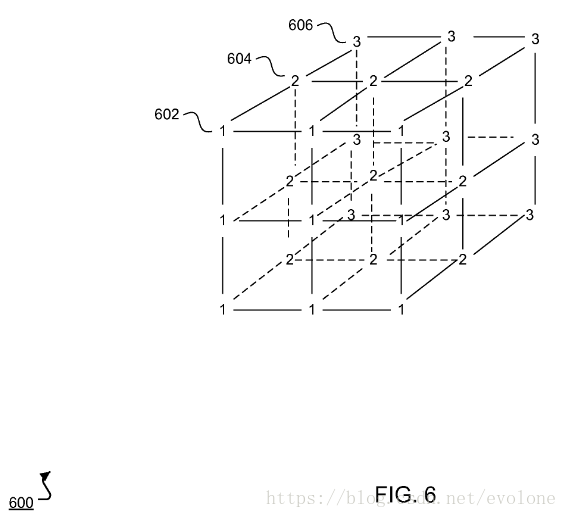
上图所示为RGB三个channel的数据,假设602层的所有“1”代表红色channel的图像数据,同理,604层的所有“2”代表绿色channel的图像数据,606层的所有“3”代表蓝色channel的图像数据.
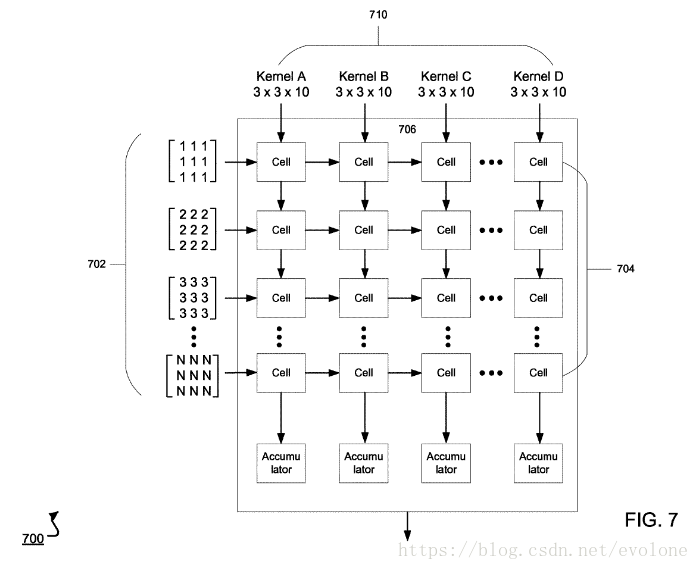
上图所示,如何将多个channel的图像数据与多个filter的权重准确喂给脉动矩阵。
请看左侧的702,同一个channel的图像数据,将二维的图像数据转化为一位的向量(vertor),然后每个元素依次从脉动矩阵的左侧进入同一个的cell,并传递给相邻右边的cell。脉动矩阵的所有行的左侧传入的是同一张图像的不同channel的数据。多少channel,就输入多少行,如果channel数少于矩阵的行数,那么空缺剩下的矩阵行的输入数据补零。
再看顶部的710,同一个filter的权重,将二维的权重转化为一维的向量(vector),然后每个元素依次从脉动矩阵的顶部进入同一个cell。多少个filter,就输入多少列,如果filter数少于矩阵的列数,那么空缺的矩阵列不用管,在下方接收累加器(Accumulator)的输出时,不接收空缺多余列的输出即可。
输入数据有多少个channel,对应的filter也会有多少个channel。
所以,filter的每个channel的权重会与输入图像的对应channel的元素对应相乘,再将所有channel对应相乘的结果,最后在底部的累加器累加,就能得到卷积的结果。
注意:只能对应channel相乘,不对应的不能相乘。
下面举例说明:
比如,图像有三个channel:R,G,B;假设只有一个filter A,那么,filter A同样有三个channel:X,Y,Z。
那么,卷积的结果是:
Sum = R×X+G×Y+B×Z (正确的)
而不是:
Sum = R×X+R×Y+R×Z+G×X+G×Y+G×Z+B×X+B×Y+B×Z (错误的)
注意:这里B×Z,代表对应channel的对应元素相乘再累加。
4.TPU乘法矩阵中的猫腻
看了上一节对乘法矩阵结构的分析,熟悉熟悉脉动矩阵的原理,再结合专利中明确说明的输入数据及输出数据,是不是感觉TPU乘法矩阵内部运算方法已然了然于胸,不禁产生一种TPU也就不过如此的轻蔑??
如果你这么想了,那么,要么是大牛,一眼看穿TPU乘法矩阵中的猫腻,要么是凡人,被谷歌的专利给赤裸裸地欺骗了。
很不幸,我也是凡人。唉……
下面,用模拟实际计算卷积的过程,再探谷歌TPU的乘法矩阵。
上一节,已然分析过,乘法矩阵的每一行输入的是像素点,每一列输入的是滤波器的权值。
像素点的值会从当前cell传递给相邻右边的cell。
滤波器的权值从当前cell传递给相邻下方的cell。
当前cell乘加得到的部分和,传递给相邻下方的cell。
但是,回想一下脉动矩阵的知识。
脉动矩阵中的乘加单元,执行A×B+C,必然只能传递ABC中的两个数,另外一个数要固定住。假设A代表输入的像素点,B代表滤波器权值,C代表相邻上方cell传递的部分和。可以肯定的是,输入像素点A必然在沿着行的方向从左往右传,部分和C必然沿着列的方向从上向下传。
然而,从专利来看,貌似滤波器权值B同样可以沿着列的方向从上往下传。
上图是专利中介绍的滤波器权值传递过程。
输入的图像数据,确定往左边传递,而cell产生的中间结果确定往下传递,那么为了能正确计算卷积,权值必须固定住。因为,脉动矩阵的原理,就是,输入的图像数据,权值,中间结果,只能三个中固定一个,另外两个分别沿着矩阵的两个方向(行和列)传递。
那么上图关于权值传递的示意,怎么解释?
而且,同一个channel的图像数据,只能进入同一行的cell,那么对应cell中的权值也需要变化,所以,单纯借鉴传统脉动矩阵的固定filter权值的方式,也无法解释通。
坑。
天坑。
谷歌是怎么做到的?
一种最直接的想法,就是每周期从一列的最上层的cell获得的权重值不只一个,而是一次获取了该列所有行的cell在对应周期需要的对应的权重值,然后每次每行用掉一个权重值,剩下的继续往下传递,指导最后一个权重值传递到最后一行的cell。
可能有点绕,下面举个例子。
谷歌的TPU的脉动矩阵中cell的规模是256×256,也就是说每一行有256个cell,总共有256行。
以第一列为例,解释上方关于权重值传递的猜测。
假设只有一列cell。
第一个cell,在周期0,得到256个权重值(来自filter的256个channel),每一个权重值是filter的对应0~255channel的第一个位置的值,假设是位置0。
然后channel[0]的权重值,在周期0,被第一列cell用掉,剩下的255个权重值,下一周期会传递到该列第二行的cell,然后channel[1]的权重值,在周期1,被第二列的cell用掉,剩下的254个权重值,下一个周期会……以此类推。
思路很简单,但是缺点也很明显,这样会需要占用很大的带宽,而且浪费很多资源。明显不够聪明。
想必聪明的谷歌不至于会选择这样简单粗暴的法子。
那,哪里想错了?
重新捋一捋思路。
首先,像素数据从脉动矩阵左侧输入,沿着脉动矩阵的行的方向,从左往右传递,每个周期向相邻右侧的cell传递,这个是肯定的。如果不是这样,那么也就无从谈起如何重复利用输入数据,减少带宽了。
其次,乘加器累加的结果,明确是从脉动矩阵的下侧的cell中输出的。也就是说,乘加单元运算得到的结果(部分和),必然是沿着脉动矩阵的列的方向,从上往下传递的。如果不这样,无法从中间的cell得到乘加的结果。
所以,脉动矩阵的cell中固定存放的必然是filter的权重。
但是,对于某个cell来说,乘加器中用于乘法的权重值,会随着输入的变化而采用对应的权重值。也就是说,权重值也会变化。
但是,随着采样窗口的移动,输入的确不断变化,但是对应的filter的权重值却只需要一套,不断重复即可。
是不是发现了什么?
哈哈!
5.TPU乘法矩阵之外的左侧输入模块
乘法矩阵左侧的输入模块,主要功能是给乘法矩阵提供对应的输入数据。需要采集放置不同channel数据。
并且需要完成对数据的预处理,比如计算到神经网络的中间层,上一层的输出会作为下一层的输入,但是需要对应补零,这样的操作,也要在左侧的输入模块中进行控制。
一般会在这里添加fifo作为输入数据的接口,方便控制。
6.TPU乘法矩阵之外的下侧激活/池化模块
乘法矩阵下侧,链接的是深度学习算法中乘累加计算结束后,紧接着的累加/激活/池化等功能模块。
累加,假设filter的尺寸是r x r,当输入的channel比较多时,比如超过了256达到512,那么TPU的乘法矩阵一次是无法计算完成的,那么就总共需要计算N(N等于:512除以256,并向上取整)次,这个时候,乘法矩阵下方的输出就需要连续累加N x r x r次输出结果。还好这个地方,每列每周期只输出一个结果,所以直接加一个累加器就可以了,非常节省硬件资源。
激活,目前常用relu激活。还有经典的sigmod,tanh等。relu激活,只需要检测数据的符号位,如果是正数,保留原值,如果是负数,直接取零。其实,本质上就是一个二选一。sigmod/tanh,这些是常规的算术运算,需要使用计算资源去实际计算。
池化,常用最大值池化。还有均值池化等。其中,最大值池化,最好实现,就是不断比较两个数,保留大的即可,然后下一个数到来,继续比较。最后剩下一个,就是想要的最大值。均值池化,稍微麻烦点,将需要计算的所有数都累加,然后除以r x r。
这些功能的实现技巧都比较成熟常见。