版权声明: https://blog.csdn.net/qq_38697681/article/details/80886955
由于在论文实验过程中一直使用的是python语言完成的论文实验,所以在论文需要使用机器学习方法时就考虑使用了scikit-learn。
scikit-learn是一款很好的Python机器学习库,它包含以下的特点:
(1)简单高效的数据挖掘和数据分析工具;
(2)可供大家使用,可在各种环境中重复使用;
(3)建立在NumPy, SciPy和matplotlib上;
(4)开放源码,可商业使用;
scikit-learn官方英文使用文档地址:http://scikit-learn.org/stable/index.html
scikit-learn中文文档地址:http://sklearn.apachecn.org/cn/0.19.0/index.html
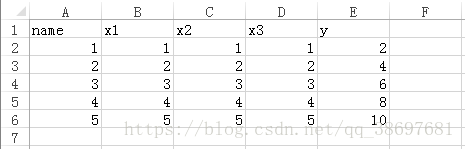
在本文中将把我在论文实验过程中使用几种机器学习方法源码贴出来方便调用,但每种机器学习方法的原理就不赘述了,可以参考官方给出的文档。这几种方法使用的测试数据均为如下所示:
一、贝叶斯岭回归
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn import preprocessing
from sklearn.naive_bayes import GaussianNB
from sklearn import linear_model
from sklearn import metrics
def Bayes(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
reg=linear_model.BayesianRidge()
reg_=reg.fit(X_train, y_train)
y_pred = reg.predict(X_test)
return (X_test,y_pred)
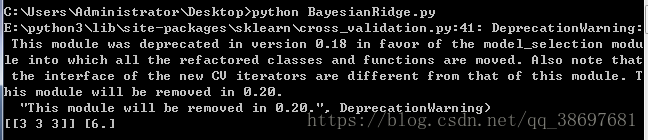
x,y=Bayes("./test.xls")
print (x,y)运行代码,可以看到结果如下所示:
二、Logistic回归
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.svm import l1_min_c
from sklearn import metrics
def Logist(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
cls = LogisticRegression(C=1.0,tol=1e-6)
rbf=cls.fit(X_train, y_train)
y_pred = cls.predict(X_test)
return (X_test,y_pred)
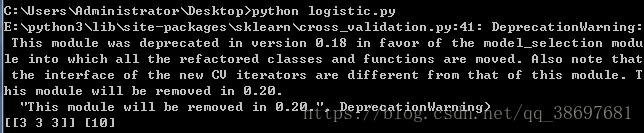
x,y=Logist("./test.xls")
print(x,y)运行代码,可以看到结果如下所示:
三、多层感知器
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn import preprocessing
from sklearn.linear_model import Perceptron
from sklearn import metrics
def Percep(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
per=Perceptron()
rbf=per.fit(X_train, y_train)
y_pred = per.predict(X_test)
return (X_test,y_pred)
#X=preprocessing.scale(X)
#y=preprocessing.scale(y)
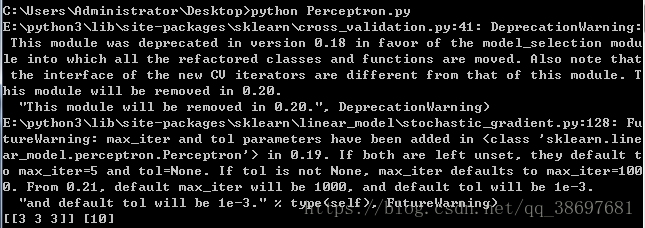
x,y=Percep("./test.xls")
print(x,y)运行代码,可以看到结果如下所示:
四、支持向量机回归
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import svm
from sklearn import metrics
from sklearn import preprocessing
def SVM(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
#X=preprocessing.scale(X)
#y=preprocessing.scale(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
rbf_svc = svm.SVR(kernel='rbf') #此处使用的是径向基内核
rbf_svc.tol=1
rbf=rbf_svc.fit(X_train, y_train)
y_pred = rbf_svc.predict(X_test)
return (X_test,y_pred)
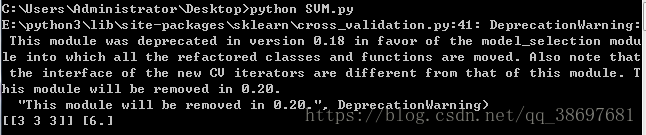
x,y=SVM("./test.xls")
print(x,y)运行代码,可以看到结果如下所示:
五、决策树回归
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn import preprocessing
from sklearn import tree
def Tree(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
#X=preprocessing.scale(X)
#y=preprocessing.scale(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
clf = tree.DecisionTreeRegressor()
rbf=clf.fit(X_train, y_train)
y_pred = rbf.predict(X_test)
return (X_test,y_pred)
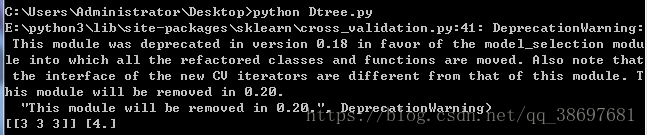
x,y=Tree("./test.xls")
print(x,y)运行代码,可以看到结果如下所示:
六、最近邻回归
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
from sklearn.cross_validation import train_test_split
from sklearn import metrics
from sklearn import preprocessing
from sklearn import neighbors
from sklearn import metrics
from sklearn.model_selection import cross_val_predict
def KNN(path):
data = pd.read_excel(path)
data.dropna(inplace=True)
array=data.values
X=array[:,1:len(data.columns)-1]
y=array[:,len(data.columns)-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
knn = neighbors.KNeighborsRegressor(1, weights="uniform") //修改第一个参数的值可以变为KNN_N近邻
knn=knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
return(X_test,y_pred)
x,y=KNN("./test.xls")
print(x,y)运行代码,可以看到结果如下所示:

本文中的源代码下载地址:https://github.com/XiaoYaoNet/Machine-Learning