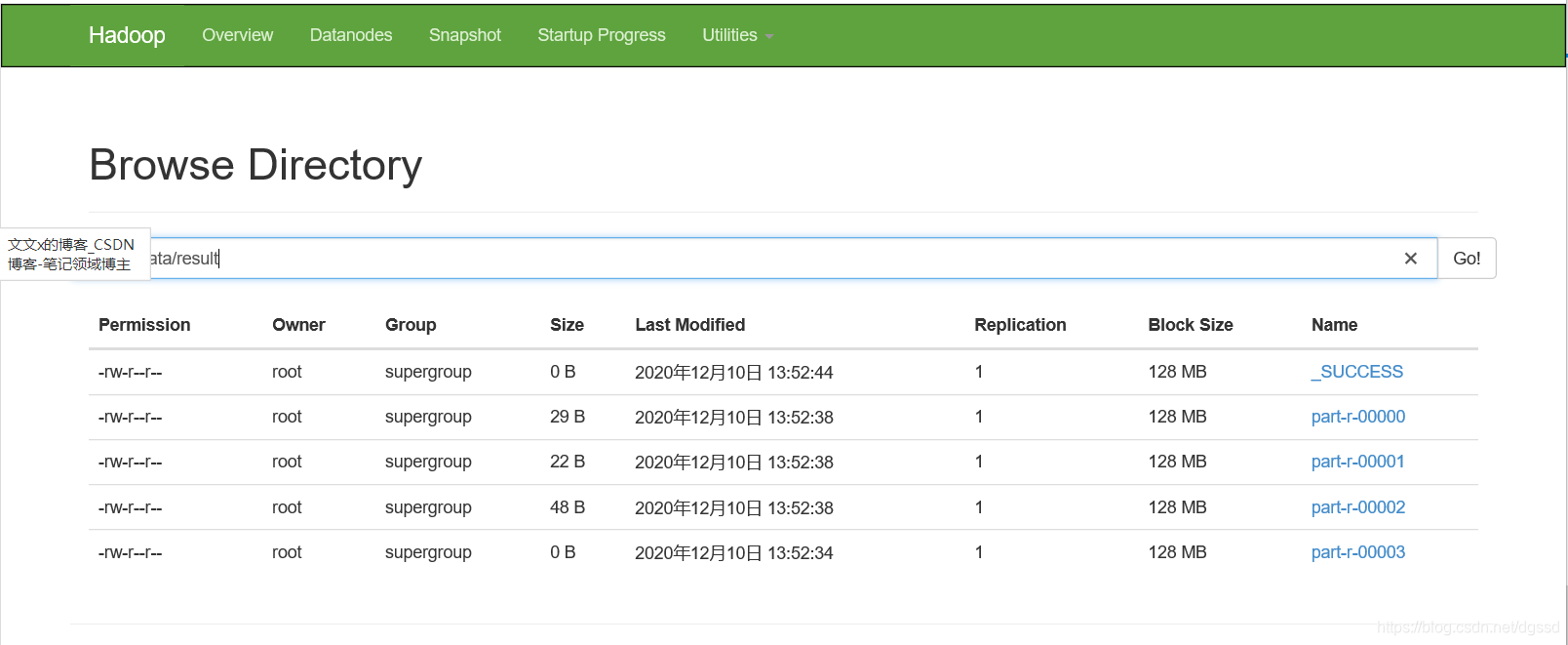
1.分析题目要求知道,对于一个用户手机流量文件进行统计,我们想要得到的结果肯定是**<key:手机号,value:[上传量 下载量 总合]>**
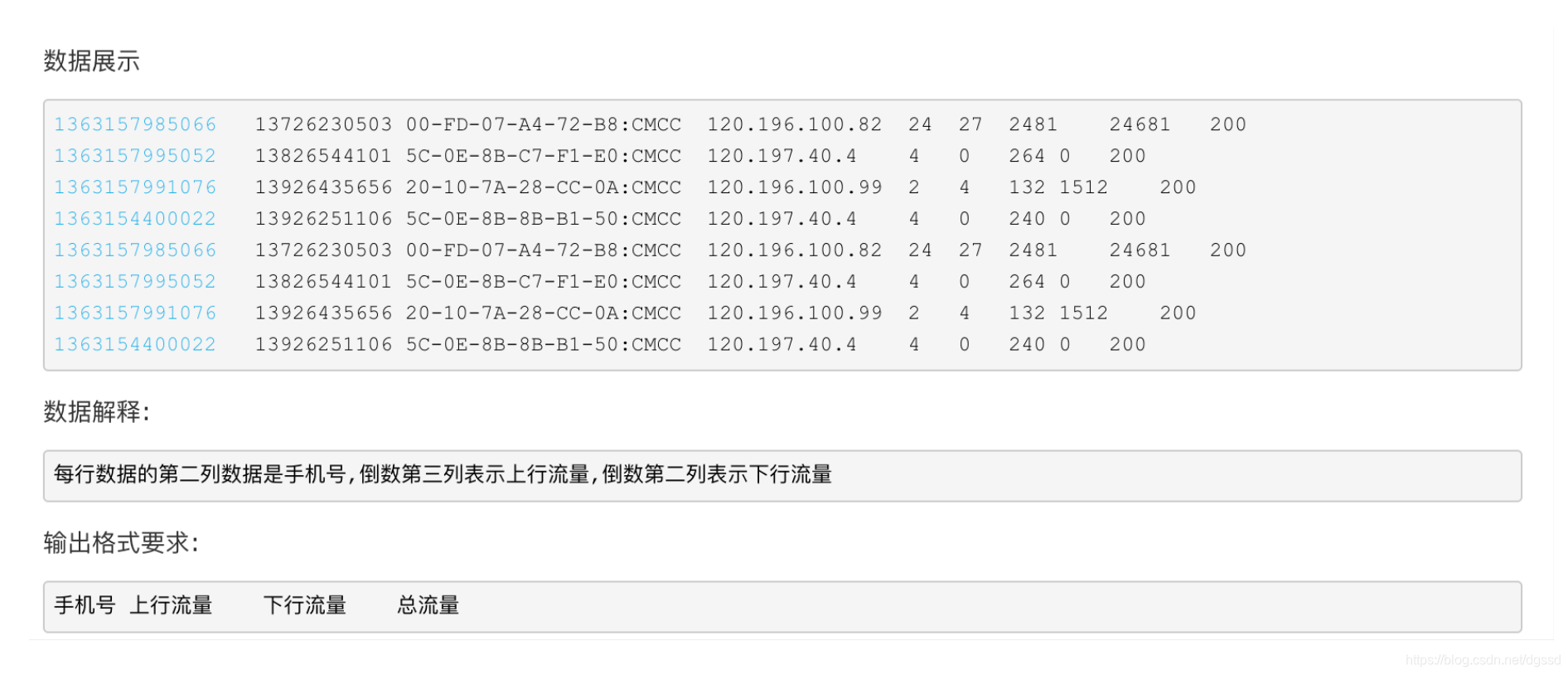
2.首先我们要准备数据文件,上传到HDFS,熟悉hdfs常用的shell命令
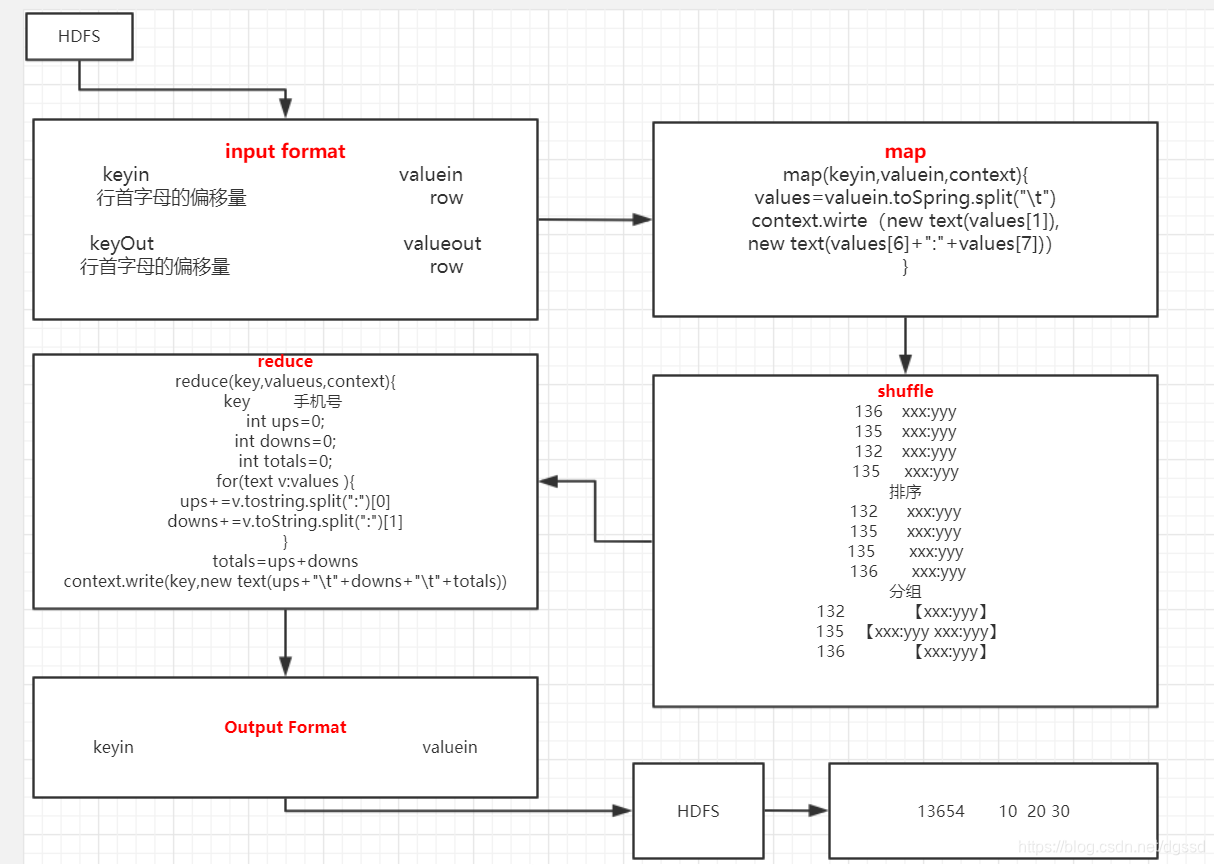
3.input Format阶段:我们必须从HDFS中读取文件,从HDFS中读取文件也是<key,value>型的一个结构。这里key值它是行首字母的偏移量,行首字母的偏移量理解就是一行占了多少个字符;value就是一行所有的值。
4.接着进入map阶段,map进行局部运算
5.每进行一次map运算。都会将结果to给shuffle,shuffle阶段就会对结果进行排序分组。
6.执行完所有的map,shuffle排序分组以后,将结果以<key, value>形式传给reduce,进行汇总运算。
7.手机流量统计job作业流程伪代码:
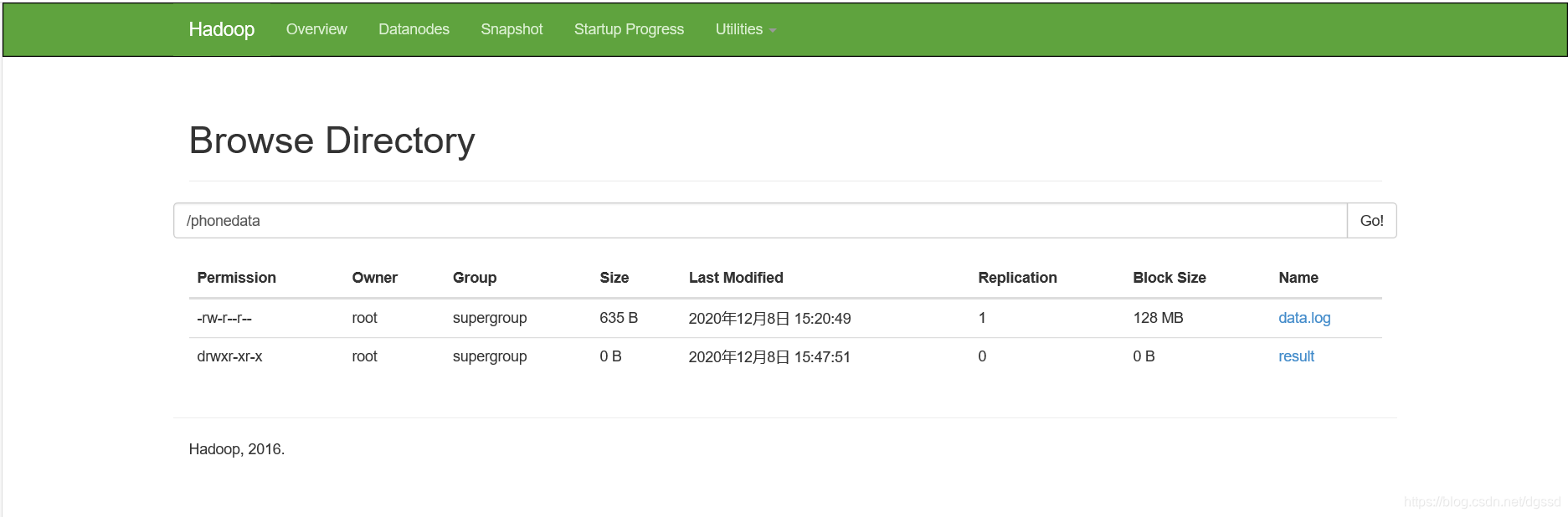
8.将数据文件上传到HDFS中
#在HDFS下创建目录
[root@Cluster00 ~]# hdfs dfs -mkdir /phonedata
#将本地文件上传到HDFS下的指定目录
[root@Cluster00 ~]# hdfs dfs -put data.log /phonedata
9.引入相关Maven依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hadoop-phonedata</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<hadoop.version>2.7.3</hadoop.version>
</properties>
<dependencies>
<!--hadoop公共依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--hadoop client 依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--map reduce-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<build>
<!--扩展maven的插件wagon ssh插件-->
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<plugins>
<!-- 在打包插件中指定main class 信息 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<outputDirectory>${basedir}/target</outputDirectory>
<archive>
<manifest>
<mainClass>com.wenxin.phonedata.PhoneDataJob</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<!--使用wagon ssh 插件-->
<!-- <plugin>-->
<!-- <groupId>org.codehaus.mojo</groupId>-->
<!-- <artifactId>wagon-maven-plugin</artifactId>-->
<!-- <version>1.0</version>-->
<!-- <configuration>-->
<!-- <fromFile>target/${project.build.finalName}.jar</fromFile>-->
<!-- <url>scp://root:[email protected]/root</url>-->
<!-- <!–自动执行对应脚本–>-->
<!-- <commands>-->
<!-- <!– 通过sh 执行shell脚本文件 –>-->
<!-- <command>nohup /root/hadoop-2.7.3/bin/hadoop jar ${project.build.finalName}.jar > /root/mapreduce.out 2>&1 & </command>-->
<!-- </commands>-->
<!-- <displayCommandOutputs>true</displayCommandOutputs>-->
<!-- </configuration>-->
<!-- </plugin>-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>7</source>
<target>7</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
10.MapReduce开发源代码
package com.wenxin.phonedata;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
//job作业
public class PhoneDataJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
//执行job作业任务类的对象是谁
ToolRunner.run(new PhoneDataJob(),args);
}
//执行job作业
public int run(String[] strings) throws Exception {
//创建job作业对象
Job job = Job.getInstance(getConf());
job.setJarByClass(PhoneDataJob.class);
//1.设置inputFormat
job.setInputFormatClass(TextInputFormat.class);
//支持设置一个hdfs系统目录 job作业在执行时会将这个目录中所有文件参与本次job作业计算
TextInputFormat.addInputPath(job,new Path("/phonedata/data.log"));
//2.设置map
job.setMapperClass(PhoneDataMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PhoneWritable.class);
//3.设置shuffle 自动处理
job.setNumReduceTasks(4);//设置reduce数量
job.setPartitionerClass(PhoneCodePartitioner.class); //自定义分区
job.setCombinerClass(PhoneDataReduce.class); //开启合并 map端输出的数据预先执行一次reduce 从而减少map端局部数据大小
//4.设置reduce
job.setReducerClass(PhoneDataReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(PhoneWritable.class);
//5.设置output format
job.setOutputFormatClass(TextOutputFormat.class);
Path res = new Path("/phonedata/result");
FileSystem fileSystem = FileSystem.get(getConf());
if(fileSystem.exists(res))fileSystem.delete(res,true);
TextOutputFormat.setOutputPath(job, res); //保证output format输出结果目录必须不存在
//6.提交job作业
//job.submit();
boolean status = job.waitForCompletion(true);
System.out.println("phone data status = " + status);
return 0;
}
//map
public static class PhoneDataMap extends Mapper<LongWritable, Text,Text,PhoneWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("PhoneDataMapGroup", "PhoneDataMap");
counter.increment(1);//自增1
String[] values = value.toString().split("\t");
String phoneCode = values[1];
String ups = values[6];
String downs = values[7];
PhoneWritable phoneWritable = new PhoneWritable();
phoneWritable.setUploads(Integer.valueOf(ups));
phoneWritable.setDownloads(Integer.valueOf(downs));
phoneWritable.setTotals(0);
context.write(new Text(phoneCode),phoneWritable);
}
}
//reduce
public static class PhoneDataReduce extends Reducer<Text,PhoneWritable,Text,PhoneWritable>{
@Override
protected void reduce(Text key, Iterable<PhoneWritable> values, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("PhoneDataReduceGroup", "PhoneDataReduce");
counter.increment(1);//自增1
int ups = 0;
int downs =0;
for (PhoneWritable value : values) {
ups += value.getUploads();
downs+=value.getDownloads();
}
PhoneWritable phoneWritable = new PhoneWritable(ups,downs,(ups+downs));
context.write(key,phoneWritable);
}
}
}
11.将项目打包(.jar的形式)上传到hadoop

#两个命令选择使用一个即可,运行上传的jar包
[root@Cluster00 ~]# hadoop jar hadoop-phonedata-1.0-SNAPSHOT.jar
[root@Cluster00 ~]# yarn jar hadoop-phonedata-1.0-SNAPSHOT.jar
10.查看结果
结果保存在patr-r-0000文件夹下(目录可以自己定义)
[root@Cluster00 ~]# hdfs dfs -cat /phonedata/result/*