先记录一些学习过程中看到的比较重要的点,最后再来进行大总结
可参考博客:
1.系统的讲述随机森林:http://www.cnblogs.com/maybe2030/p/4585705.html#_label2
涉及:
随机森林分类效果(错误率)与两个因素有关? 树之间的相关性与每棵树的准确度
为什么要随机抽样训练集?
为什么要有放回地抽样?
2.系统的讲述GBDT:https://www.cnblogs.com/pinard/p/6140514.html
涉及:公式推导,正则等
3.系统的讲述Xgboost:
https://blog.csdn.net/guoxinian/article/details/79243307
https://www.cnblogs.com/zhouxiaohui888/p/6008368.html
最全调参攻略:https://blog.csdn.net/szm21c11u68n04vdclmj/article/details/78516866
涉及:公式推导,如何快速寻找最优分割点,如何并行,如何处理稀疏特征(包含缺失值额特征)
4.GBDT>Xgboost>LightGBM : https://www.cnblogs.com/infaraway/p/7890558.html
涉及:leafwise levelwise
博大精深!!
1.xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
答案来源:https://www.jianshu.com/p/005a4e6ac775
也就是说,当我们训练一个模型时,偏差和方差都得照顾到,漏掉一个都不行。
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差(variance) ,因为采用了相互独立的基分类器多了以后,h的值自然就会靠近.所以对于每个基分类器来说,目标就是如何降低这个偏差(bias),所以我们会采用深度很深甚至不剪枝的决策树。
对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
2.RF是如何评估特征重要性的?
答案来源:http://www.cnblogs.com/justcxtoworld/p/3447231.html
在随机森林中某个特征X的重要性的计算方法如下:
(1)对于随机森林中的每一颗决策树,使用相应的OOB(袋外数据)数据来计算它的袋外数据误差,记为errOOB1.
(2) 随机地对袋外数据OOB所有样本的特征X加入噪声干扰(就可以随机的改变样本在特征X处的值),再次计算它的袋外数据误差,记为errOOB2.
(3)假设随机森林中有Ntree棵树,那么对于特征X的重要性=∑(errOOB2-errOOB1)/Ntree,之所以可以用这个表达式来作为相应特征的重要性的度量值是因为:若给某个特征随机加入噪声之后,袋外的准确率大幅度降低,则说明这个特征对于样本的分类结果影响很大,也就是说它的重要程度比较高。
可以认为这个特征重要性的衡量是考虑了特征之间的相互作用;RF的特征筛选并没有对特征进行组合加工或者其他变换(这点不如逻辑回归)
3.GBDT如何用于分类?
答案来源【GBDT面试总结(上)】:https://www.cnblogs.com/ModifyRong/p/7744987.html
【建议大家看原作者的总结,还给出了鸢尾花的例子,默默感谢一波~】
首先明确一点,gbdt 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的。
如果选用的弱分类器是分类树,类别相减是没有意义的。上一轮输出的是样本 x 属于 A类,本一轮训练输出的是样本 x 属于 B类。 A 和 B 很多时候甚至都没有比较的意义,A 类- B类是没有意义的。

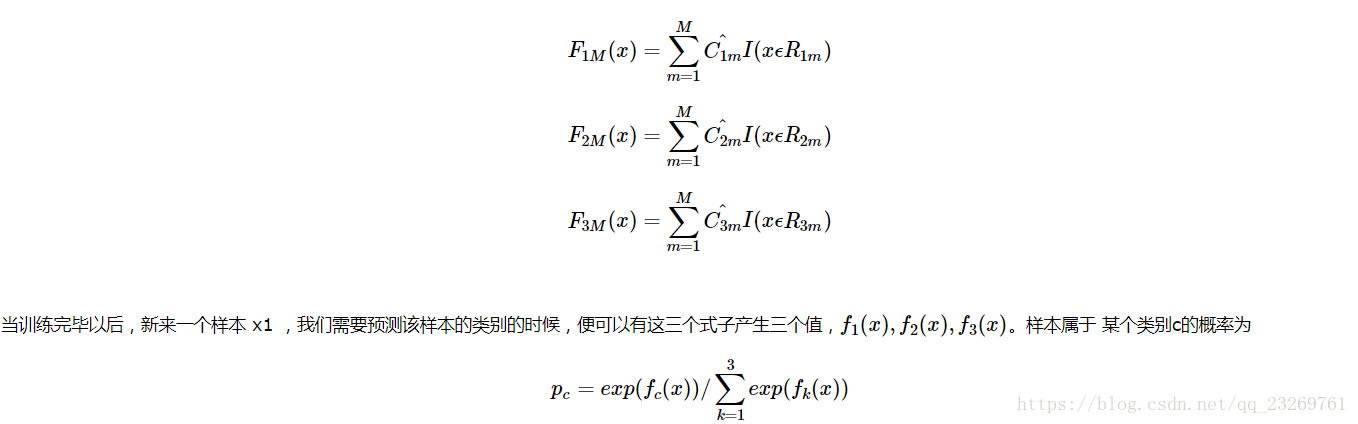
4.GBDT是如何衡量特征的重要性的?
答案来源:https://www.cnblogs.com/notwice/p/8546436.html
XGBoost的特征重要性是如何得到的?某个特征的重要性(feature score),等于它被选中为树节点分裂特征的次数的和,比如特征A在第一次迭代中(即第一棵树)被选中了1次去分裂树节点,在第二次迭代被选中2次…..那么最终特征A的feature score就是 1+2+….
答案来源:https://blog.csdn.net/yangxudong/article/details/53899260
计算所有的非叶子节点在分裂时加权不纯度的减少,减少得越多说明特征越重要。
不纯度的减少实际上就是该节点此次分裂的收益,因此我们也可以这样理解,节点分裂时收益越大,该节点对应的特征的重要度越高。

5.GBDT与XGB区别
答案来源:https://www.cnblogs.com/notwice/p/8546436.html
1. 传统GBDT以CART作为基分类器,xgboost还支持线性分类器(gblinear),这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)
2. 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导
3. xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性
4. Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
5. 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性
6. 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
7. xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
8. 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点.
9. 在XGBoost里,对于稀疏性的离散特征,在寻找split point的时候,不会对该特征为missing的样本进行遍历统计,只对该列特征值为non-missing的样本上对应的特征值进行遍历,通过这个工程trick来减少了为稀疏离散特征寻找split point的时间开销。在逻辑实现上,为了保证完备性,会分别处理将missing该特征值的样本分配到左叶子结点和右叶子结点的两种情形。
6.随机森林袋外数据比例为什么是1/3?

7.RF,XGboost如何处理缺失值?
https://blog.csdn.net/qq_19446965/article/details/81637199
原是论文中关于缺失值的处理将其看与稀疏矩阵的处理看作一样。在寻找split point的时候,不会对该特征为missing的样本进行遍历统计,只对该列特征值为non-missing的样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找split point的时间开销。在逻辑实现上,为了保证完备性,会分别处理将missing该特征值的样本分配到左叶子结点和右叶子结点的两种情形,计算增益后选择增益大的方向进行分裂即可。可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率。如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子树。