1. 决策树定义(决策树的构建算法主要有ID3、C4.5、CART三种,其中ID3和C4.5是分类树,CART是分类回归树)
理解树,就需要理解几个关键词:根节点、父节点、子节点和叶子节点。
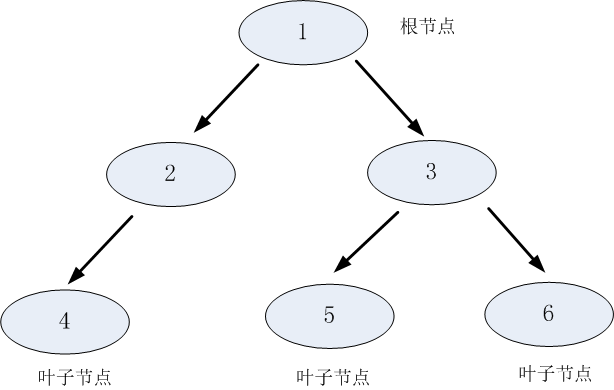
决策树利用如上图所示的树结构进行决策,每一个非叶子节点是一个判断条件,每一个叶子节点是结论。
实质上就是在用特征维度对样本空间进行划分。假设树为二叉树,通过不断将特征进行分裂。比如当前树结点是基于第j个特征值进行分裂的,设该特征值小于s的样本划分为左子树,大于s的样本划分为右子树。
2. 决策树的构建
两步:分裂与剪枝
分裂:
1)数据分割:
分裂属性的数据类型分为离散型和连续性两种情况。
离散型的数据——按照属性值进行分裂,每个属性值对应一个分裂节点;
连续性的数据——是对数据按照该属性进行排序,再将数据分成若干区间,如[0,10]、[10,20]、[20,30]…,一个区间对应一个节点,若数据的属性值落入某一区间则该数据就属于其对应的节点。
2)分裂属性的选择:贪婪思想(即选择可以得到最优分裂结果的属性进行分裂。)
每次尝试对自己已有叶子加一个分割,遍历所有分割,选择变化量最大的作为最合适的分割。(因为希望每一次分裂之后子节点的数据尽量”纯”,所以下图选择属性2 分裂)
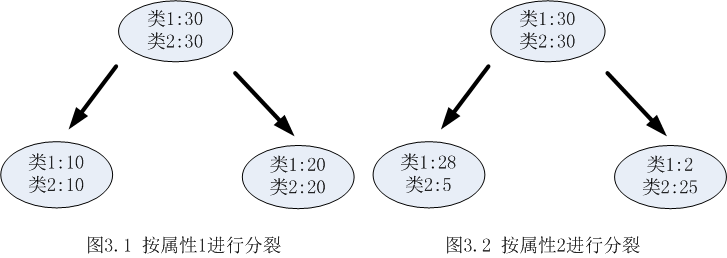
决策树使用信息增益或者信息增益率作为选择属性的依据。
信息增益解说:https://blog.csdn.net/guo1988kui/article/details/78427409

举个栗子:满足什么情况才去玩高尔夫,假设用Day做分裂属性,显然,每一天都可以将样本分开,也就是形成了一颗叶子数量为10,深度只有两层的树,用公式算出来的信息增益很大,实际来看显然这种属性的分割(宽度)没意义。所以有了信息增益率来约束节点数据量不要过小。
基尼值计算公式如下:
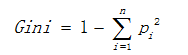
其中Pi表示类i的数量占比。当两类数量相等时,基尼值等于0.5 ;当节点数据属于同一类时,基尼值等于0 。基尼值越大,数据越不纯。
3)停止分裂的条件
(1)最小节点数
当节点的数据量小于一定数量时,停止分裂。因为数据量较少时,再做分裂容易强化噪声数据的作用,过拟合。
(2)熵或者基尼值小于阀值。
当熵或者基尼值过小时,表示数据的纯度比较大,不需要继续分裂。
(3)决策树的深度达到指定的条件
(4)所有特征已经使用完毕,不能继续进行分裂。
剪枝:剪枝是指将一颗子树的子节点全部删掉。https://www.cnblogs.com/yonghao/p/5064996.html
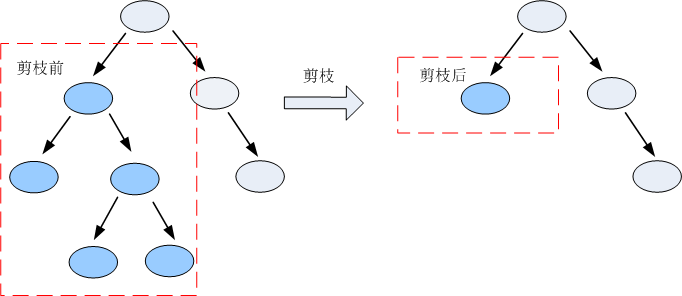
目的:降低决策树的复杂度,降低过拟合出现的概率。
如何剪枝:CCP—代价复杂度剪枝(CART树)
选择节点表面误差率增益值最小的非叶子节点,删除该非叶子节点的左右子节点,若有多个非叶子节点的表面误差率增益值相同小,则选择非叶子节点中子节点数最多的非叶子节点进行剪枝。
表面误差率增益值的计算公式:

3. ID3、C4.5、CART优缺点比较
ID3:
(1)采用信息增益进行分裂,分裂的精确度可能没有采用信息增益率进行分裂高。(根据一个属性无限分裂,增宽度不增深度。)
(2)不能处理连续型数据,只能通过离散化将连续性数据转化为离散型数据。
(3)不能处理缺省值。
(4)没有对决策树进行剪枝处理,很可能会出现过拟合的问题。
C4.5:
(1)C4.5是添加信息增益率选择分裂的属性,解决了ID3选择属性时的偏向性问题;
(2)C4.5能够对连续数据进行处理,采用一刀切的方式将连续型的数据切成两份,在选择切割点的时候使用信息增益作为择优的条件;理论上来讲,N条数据就有N-1个切割点,为了选取最优的切割垫,要计算按每一次切割的信息增益,计算量是比较大的,那么有没有简化的方法呢?有,在相邻两个属于不同类的位置尝试加分割点,相同的则跳过。
(3)C4.5可以剪枝,采用悲观剪枝的策略,一定程度上降低了过拟合的影响。
CART(分类回归树):
(1)CART既能是分类树,又能是回归树;上述两个只是分类树。
(2)当CART是分类树时,选择能够最小化分裂后节点GINI值的分裂属性;当CART是回归树时,采选择能够最小化两个节点样本方差的分裂属性。
(3)CART是一棵二叉树。每一次分裂只会产生两个节点。 对于连续性的数据,直接采用与C4.5相似的处理方法
4. XGboost
1)公式推导:https://www.cnblogs.com/zhouxiaohui888/p/6008368.html
注:红色箭头指向的l即为损失函数;红色方框为正则项,包括L1、L2;红色圆圈为常数项。 对损失函数采用二阶泰勒展开。

2)看下Xgboost的一些重点
(1)w是最优化求出来的,不是啥平均值或规则指定的,这个算是一个思路上的新颖吧;
(2)正则化防止过拟合的技术,上述看到了,直接loss function里面就有;
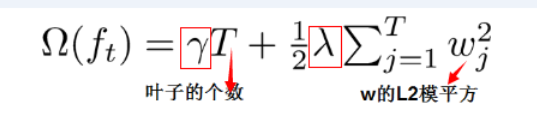
(3)支持自定义loss function,能泰勒展开(能求一阶导和二阶导)就行。(变为二次函数方便求最低值。)
(4)支持并行化,这是xgboost的闪光点,直接的效果是训练速度快!!!!
3)Xgboost和深度学习的关系:
不同的机器学习模型适用于不同类型的任务。深度神经网络通过对时空位置建模,能够很好地捕获图像、语音、文本等高维数据;而基于树模型的XGBoost则能很好地处理表格数据,同时还拥有一些深度神经网络所没有的特性(如:模型的可解释性、输入数据的不变性、更易于调参等)。