记录一些已经看过的题目。https://blog.csdn.net/v_JULY_v/article/details/78121924
14 L1和L2正则先验分别服从什么分布。机器学习 ML基础 易 (没太看懂)
@齐同学:面试中遇到的,L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布。
@AntZ: 先验就是优化的起跑线, 有先验的好处就是可以在较小的数据集中有良好的泛化性能,当然这是在先验分布是接近真实分布的情况下得到的了,从信息论的角度看,向系统加入了正确先验这个信息,肯定会提高系统的性能。
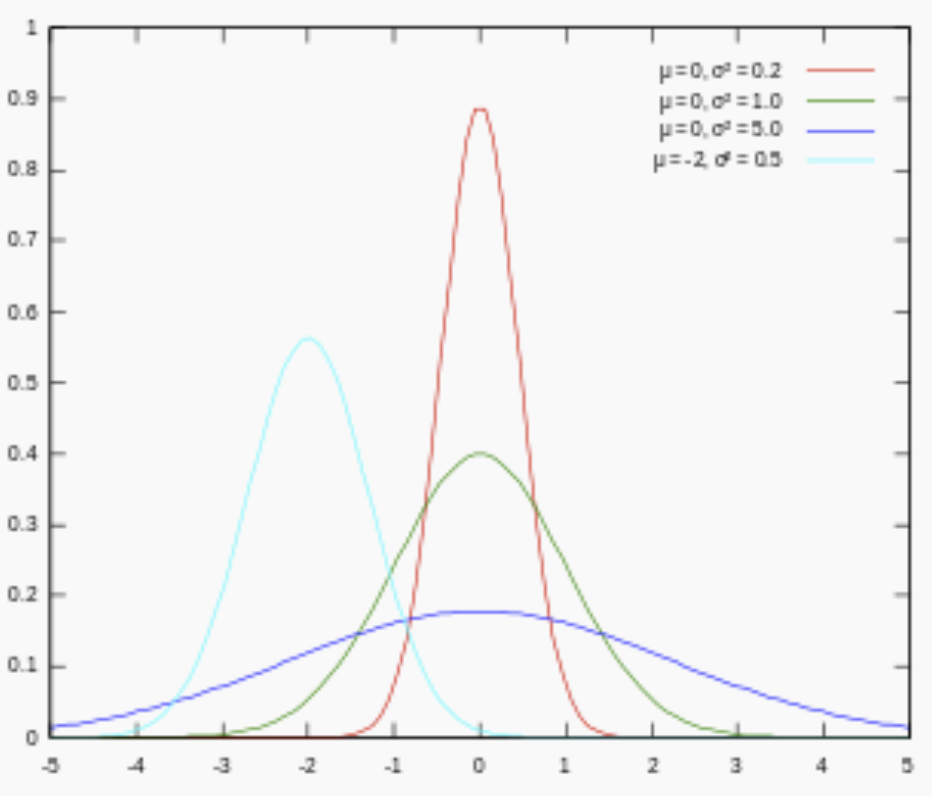
对参数引入高斯正态先验分布相当于L2正则化, 这个大家都熟悉:
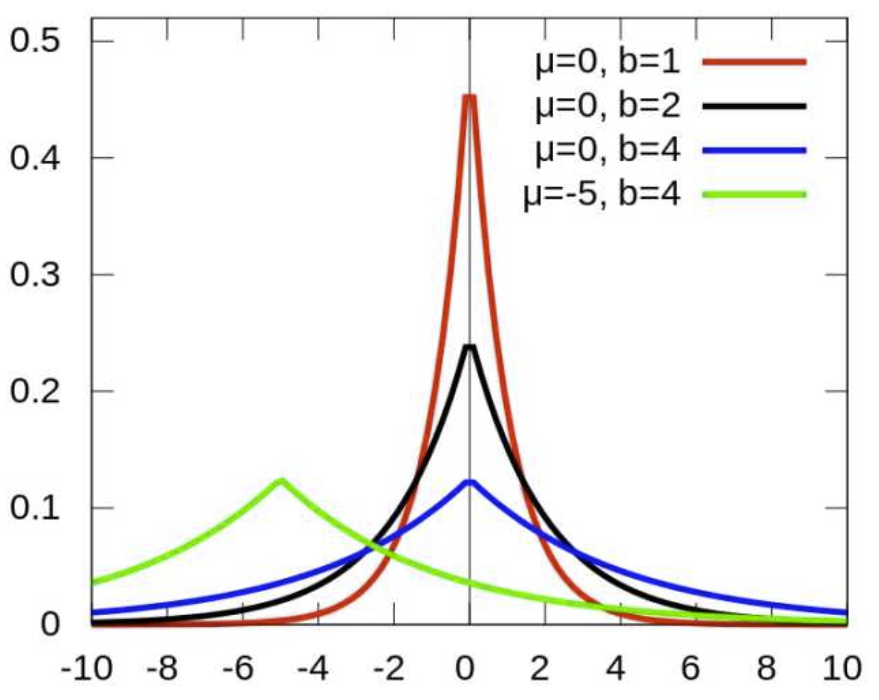
对参数引入拉普拉斯先验等价于 L1正则化, 如下图:
从上面两图可以看出, L2先验趋向零周围, L1先验趋向零本身。
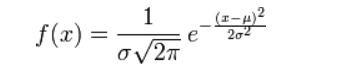
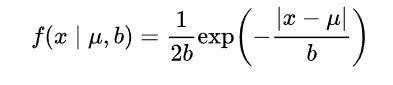
18 为什么朴素贝叶斯如此“朴素”?机器学习 ML模型 易
因为它假定所有的特征在数据集中的作用是同样重要和独立的。正如我们所知,这个假设在现实世界中是很不真实的,因此,说朴素贝叶斯真的很“朴素”。
@AntZ: 朴素贝叶斯模型(Naive Bayesian Model)的朴素(Naive)的含义是"很简单很天真"地假设样本特征彼此独立. 这个假设现实中基本上不存在, 但特征相关性很小的实际情况还是很多的, 所以这个模型仍然能够工作得很好。
21 KNN中的K如何选取的?机器学习 ML模型 易
关于什么是KNN,可以查看此文:《从K近邻算法、距离度量谈到KD树、SIFT+BBF算法》。KNN中的K值选取对K近邻算法的结果会产生重大影响。如李航博士的一书「统计学习方法」上所说:
- 如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
- K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的累,模型过于简单,忽略了训练实例中大量有用信息。
22 防止过拟合的方法。机器学习 ML基础 易
过拟合的原因是算法的学习能力过强;一些假设条件(如样本独立同分布)可能是不成立的;训练样本过少不能对整个空间进行分布估计。
处理方法:
- 早停止:如在训练中多次迭代后发现模型性能没有显著提高就停止训练
- 数据集扩增:原有数据增加、原有数据加随机噪声、重采样
- 正则化
- 交叉验证
- 特征选择/特征降维
- 创建一个验证集是最基本的防止过拟合的方法。我们最终训练得到的模型目标是要在验证集上面有好的表现,而不训练集。
- 正则化可以限制模型的复杂度
24 哪些机器学习算法不需要做归一化处理?机器学习 ML基础 易
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、rf。而像adaboost、svm、lr、KNN、KMeans之类的最优化问题就需要归一化。
@管博士:我理解归一化和标准化主要是为了使计算更方便 比如两个变量的量纲不同 可能一个的数值远大于另一个那么他们同时作为变量的时候 可能会造成数值计算的问题,比如说求矩阵的逆可能很不精确 或者梯度下降法的收敛比较困难,还有如果需要计算欧式距离的话可能 量纲也需要调整 所以我估计lr 和 knn 保准话一下应该有好处。至于其他的算法 我也觉得如果变量量纲差距很大的话 先标准化一下会有好处。
@寒小阳:一般我习惯说树形模型,这里说的概率模型可能是差不多的意思。
25 对于树形结构为什么不需要归一化?机器学习 ML基础 易
答:数值缩放,不影响分裂点位置。因为第一步都是按照特征值进行排序的,排序的顺序不变,那么所属的分支以及分裂点就不会有不同。对于线性模型,比如说LR,我有两个特征,一个是(0,1)的,一个是(0,10000)的,这样运用梯度下降时候,损失等高线是一个椭圆的形状,这样我想迭代到最优点,就需要很多次迭代,但是如果进行了归一化,那么等高线就是圆形的,那么SGD就会往原点迭代,需要的迭代次数较少。
另外,注意树模型是不能进行梯度下降的,因为树模型是阶跃的,阶跃点是不可导的,并且求导没意义,所以树模型(回归树)寻找最优点事通过寻找最优分裂点完成的。
26 数据归一化(或者标准化,注意归一化和标准化不同)的原因。机器学习 ML基础 易
@我愛大泡泡,来源:http://blog.csdn.net/woaidapaopao/article/details/77806273
要强调:能不归一化最好不归一化,之所以进行数据归一化是因为各维度的量纲不相同。而且需要看情况进行归一化。
- 有些模型在各维度进行了不均匀的伸缩后,最优解与原来不等价(如SVM)需要归一化。
- 有些模型伸缩有与原来等价,如:LR则不用归一化,但是实际中往往通过迭代求解模型参数,如果目标函数太扁(想象一下很扁的高斯模型)迭代算法会发生不收敛的情况,所以最坏进行数据归一化。
补充:其实本质是由于loss函数不同造成的,SVM用了欧拉距离,如果一个特征很大就会把其他的维度dominated。而LR可以通过权重调整使得损失函数不变。