第七章----->最后
数据的准备:加载、清理、转换、重塑
合并数据集
pandas对象中的数据可以通过内置的方式进行合并
数据库风格的dataframe合并
合并(merge)或连接(join)
索引上的合并
可以传入
left_index=True或
right_index=True来说明索引应该被用作连接键
DataFrame还有一个
join(默认是左连接,但是可以指定连接的方式)实例方法,它可以更为方便的实现按索引合并,还可以用于合并带有相同或相似索引的DataFrame对象,不管他们之间有没有重叠的列,
轴向连接
合并重叠数据 使用Series的combine_first方法,DataFrame又有这个方法
重塑和轴向旋转
使用stack()方法和unstack()方法进行数据的重塑,
使用DataFrame的pivot方法可以实现
长格式到宽格式的转化。
数据转换
重复数据的移除,通过DataFrame的duplicated方法判断,通过drop_duplicates()方法移除,默认判断全部列,保留第一个出现的值。
利用函数或映射进行数据转换,使用map()实现
替换值
用replace方法实现
重命名轴索引
DataFrame的轴标签也有map()方法,DataFrame还有一个使用的方法是rename()方法
离散化和面元划分
使用pandas的cut函数和qcut函数
检测和过滤异常值:使用条件判断,和重新定义值得方法
排列和随机采样:用numpy.random.permutation函数生成一个随机序列,用take函数对数组进行重新排列
计算指标/哑变量
通过pandas一个get_dummies函数实现,
实用技巧:结合get_dummies和诸如cut之类的离散化函数。
字符串操作
字符串对象方法
对于字符串方法index和find的区别:如果找不到字符串,index将会引发一个异常,而不会返回一个-1
正则表达式
为匹配的分组加上一个名称可以得到一个好用的带有分组名称的字典,
将待分段的各个部分用圆括号包起来,可以得到一个元组列表
第九章 数据聚合与分组运算
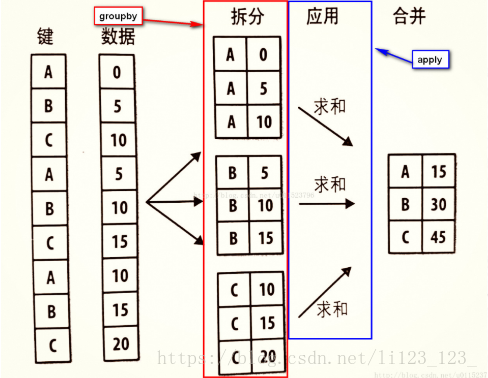
使用groupby()方法可以实现分组,得到一个groupby对象,
groupby默认是在
axis=0(第一个轴)上进行分组,可以通过设置在其他任何轴上进行分组。
可以对分组进行迭代,可以只选取其中一个或一组列
可以通过字典或Series进行分组。如下图
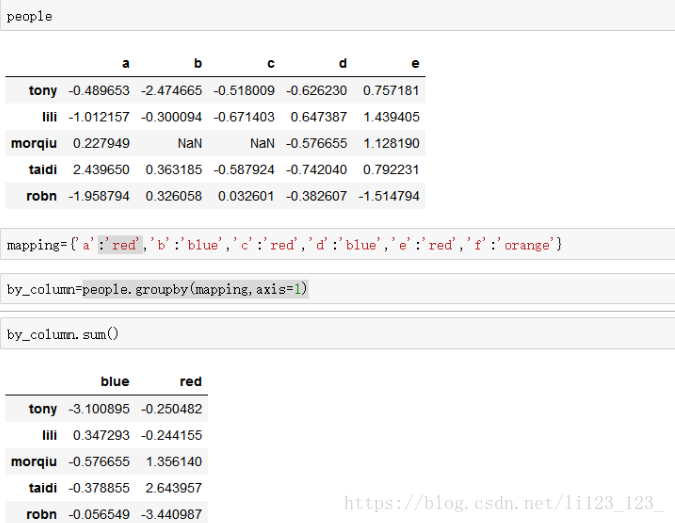
通过函数分组也可以。
可以根据索引级别进行分组,
数据的聚合
如果要使用自己的聚合函数,只需要将其传入aggregate或agg方法即可
也可以给agg传入一个由(name,function)元组组成的列表,则元组的第一个元素就会被用作DataFrame的列名(可以将这种二元元组列表看做一个有序映射)。
要想对不同的列应用不同的函数,可以向agg传入一个从列名映射到函数的字典。
分组级运算和转换
transform将一个函数应用到各个分组,然后将结果放置到适合的位置上,
pandas中的两个重要函数的结合使用,groupby与apply的结合使用,
分组加权平均数和相关系数分别用
category函数和
corrwith实现
透视表和交叉表,
pivote_table的默认聚合类型是计算分组平均数。
如果传入
margins= True 将会添加分项小计。
要使用其他聚合函数时,将其传给
aggfunc即可。
交叉表:crosstab
计算分组频率的特殊透视表
时间序列
日期和时间数据类型及工具
data : 存储日历日期
time :存储时间为:时,分,秒,毫秒
datatime : 存储日期和时间
timedelta 表示两个datetime值之间的差(日,秒,毫秒)
字符串和datetime的相互转换
可以第三方包dateutil中的parser.parser方法解析常见的日期格式
dateutil可以解析几乎所有人类能理解的日期格式。(不包括中文)
时间序列基础
pandas最基本的时间序列类型是以时间戳为索引的Series。
通过日期进行切片,可以用不存在于该时间序列中的时间戳对其进行切片,切片产生的是源时间的视图。
带有重复索引的时间序列,
可以通过groupby进行聚合,
日期的范围频率和移动
生成日期范围
pandas.data_range可以用于生成指定长度的DatetimeIndex
频率和日期偏移量
WOM日期(week of month)是一个非常实用的频率类。
移动(超前或滞后)数据
shift方法可用于执行单纯的前移或后移操作,保证索引不变。也可以通过传入freq参数来使索引变化,而数据不丢失。
通过偏移量对日期进行位移
可以通过锚点偏移量的
rollforward和
rollback方法,可显示的将日期向前或向后“滚动”,可以巧妙的结合groupby使用。
时区处理
本地化和转换
Timestamp对象,不同时区之间的运算,最终结果就会是UTC,
时期及其算数运算。如果两个Period对象拥有相同的频率,则他们的差就是他们之间的单位数量。
时期的频率转换
Period和PeriodIndex对象都可以通过其asfreq方法被转换成别的频率。
按季度计算的时间频率
将Timestamp转换为Period
通过to_period方法,可以将时间戳索引的Series和DataFrame对象转化为以日期索引。
to_timestamp是相反的过程
也可以通过数组创建PeriodIndex
重采样和频率转换,
pandas对象都有一个resample方法,他是各种频率转换工作的主力函数
重采样是通过传入参数(例如closed、label,loffset等)可以获取到目标序列,
OHLC采样
金融领域一种无处不在的时间序列聚合方式(open 开盘,close 收盘)
通过groupby进行重采样,
升采样和插值
通过时期进行采样
时间序列绘图
移动窗口函数**************
指数加权函数**********
二元移动窗口函数******************************
频率不同的时间序列运算时:
Period索引的两个不同的时间序列之间的运算必须进行显示的转换。
时间和最当前数据选取
Python的datetime.time对象索引即可抽选出时间点上的值。实际是用的实例方法at_time
将
Timestamp传入
asof方法,就能得到这些时间点处(或其之前最近)的有效值,
拼接多个数据源是用pd.concat即可实现数据的拼接
用一个时间序列对当前时间序列的缺失值“打补丁”:combine_first可以引入合并之前的数据,还有一个类似的方法时updata方法,如果想只填充空洞则必须传入参数:overwrite=False
通过机制直接设置列会简单些。
numpy的高级应用
数组的重塑
可以用reshape实现将一个矩阵排列为一个新矩阵,用ravel(不会产生源数据的副本)和flatten(总是返回数据的副本)实现拆开或扁平化,
C和Fortran顺序
c/行优先
Fortran/列优先顺序
数组的合并和拆分:
numpy.concatenate可以按指定轴将一个有数组组成的序列连接到一起。
也可以通过方便的方法,vstack和hstack方法实现。
split用于将一个数组沿指定的轴拆分为多个数组。
堆叠辅助类:r_和c_
重复元素操作:tile(像瓷砖一样铺开原数据)和repeat(将各个元素重复一定次数)
花式索引的等价函数:take和put
广播
沿其他轴向的广播。
通过广播设置数组的值。
ufunc高级应用
方法:
reduce(x) 通过连续执行原始运算的方式对值进行聚合
accumulate(x) 聚合值,保留所有局部聚合结果
reduceat(x,bins) “局部简约”(也就是groupby)。约简数据的各个切片以产生聚合型数组
outer(x,y) 对x和y中的每对元素应用原始运算。结果数组的形状为x.shape + y.shape
自定义ufunc
有两个工具可以将自定义函数像ufunc那样使用,
np.frompyfunc(add_elements,2,1) #参数分别是:一个函数和两个分别表示输入输出参数数量的整数
还有一个是numpy.vectorize。它的类型推断能力要比frompyfunc智能。
结构化和记录式数组
可以像C语言中的结构体一样存储不同类型的数和表格型的数据。
嵌套dtype和多维字段
是一个很强大的功能。pandas并不支持这个功能,但是它的分层索引机制和这个差不多。
关于排序的话题
ndarray的sort实例方法也是就地排序,numpy.sort会为原数组创建一个已排序的副本,
但是排序都没有提供设置降序的方法,但可以用有关列表的一个小技巧:values[::-1]可以返回一个反序的列表。对nadarray也是如此。
间接排序
用argsort方法和numpy.lexsort方法实现该功能。
lexsort对键的应用顺序是从最后一个传入的算起的。
其他排序算法
np的三种排序算法中,mergesort(合并排序)是唯一的稳定排序,
数组排序算法:
‘quicksort’ 不稳定
‘mergesort’ 稳定
‘heapsort’ 不稳定
numpy.searchsorted:在有序数组中查找元素