前文:之前写了一篇高可用HA的namenode运行机制,那么今天我们来配置一下HA的环境,想详细看一下HA原理的可以在上一篇文章中查看,首先需要声明的是我的主机名是sparkKing-master,两个从节点是sparkKing-salve,sparkKing-salve02,所以这里请大家看到这几个词的时候,不要怀疑自己看到了个什么玩意儿,就是我当初傻了吧唧,为了装13起名的。好,现在开始配置!!!
注意:在此之前zookeeper要配置好
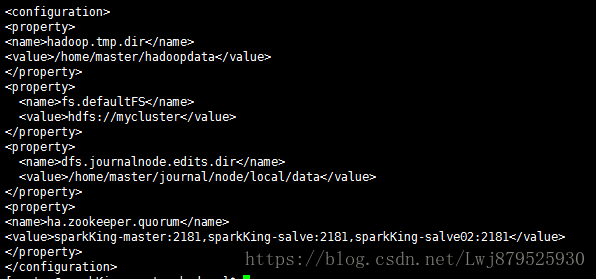
1.首先我们修改core-site.xml文件:
(1)指定hdfs的nameservice为mycluster:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
注意:这里的mycluster是自己起的名字,大家可以任意取名,但是下面要注意名字相同,到需要大家注意的时候我会提醒大家。
(2)指定hadoop临时目录
<property>
<name>hadoop.tmp.dir</name>
<value>/home/master/hadoopdata</value>
</property>
注意:这个文件是保存元数据的,之后会把这个文件夹发送给另一个namenode所在的机器。
(3)指定zookeeper地址:
<property>
<name>ha.zookeeper.quorum</name>
<value>sparkKing-master:2181,sparkKing-salve:2181,sparkKing-salve02:2181</value>
</property>
(4)指定journalnode临时目录存放地址
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/master/journal/node/local/data</value>
</property>
这个位置要自己创建
然后给大家看一下我配置的图:
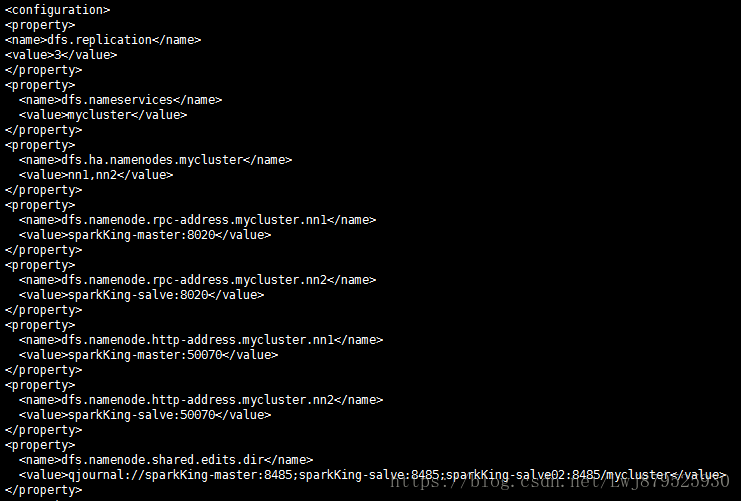
2.配置hdfs-site.xml
(1)指定hdfs的nameserverice为mycluster,这里需要和core-site.xml文件中保持一致
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
(2)mycluster下面有两个namenode,分别是nn1,nn2
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
(3)配置nn1,nn2的RPC通信地址:
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>sparkKing-master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>sparkKing-salve:8020</value>
</property>
(4)配置nn1,nn2的http通信地址:
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>sparkKing-master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>sparkKing-salve:50070</value>
</property>
(5)指定namenode的edits元数据在JournalNode上的的存放位置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://sparkKing-master:8485;sparkKing-salve:8485;sparkKing-salve02:8485/mycluster</value>
</property>
(6)指定Journalnode在本地磁盘存放数据的位置
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/master/journaldata/</value>
</property>
注意:这个目录也需要自己创建
(7)开启namenode失败自动切换:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
(8)配置失败自动切换实现方式:
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
(9)配置隔离机制方法,多个机制用换行分割,即每个机器暂用一行:
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
(10)使用sshfence隔离机制时需要ssh免密登录:
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/master/.ssh/id_rsa</value>
</property>
给大家配图:
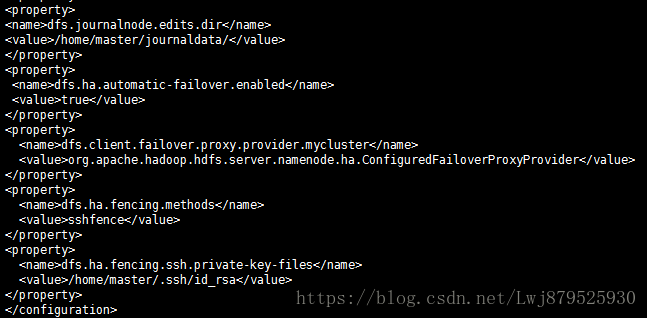
3.运行:
注意:严格按照下面的目录!
(1)分别在三台机器上启动zookeeper集群,命令是zkServer.sh start;
(2)分别在三台机器上手动启动journalnode,命令是hadoop-daemon.sh start journalnode;
(3)格式化namenode,命令是hdfs namenode -initializeSharedEdits;
(4)将元数据发送给将要接管namenode的机器,我这里就发送给了sparkKing-salve这台机器;
(5)格式化zkfc,命令是hdfs zkfc -formatZK;
(6)启动HDFS,命令是statr-all.sh;
做完这些之后,就可以进行检测。检测的方法是:在50070网站上查看现在namenode状态:

这里的状态是active,另一台机器的50070是standby状态,将active状态的namenode用kill杀死,查看standby namenode的状态是否会转换成active 状态,是就成功了。