阿里天池比赛报告
比赛题目:
在商场内精确的定位用户当前所在店铺,当用户在商场环境中打开手机的时候,存在定位信号不准、环境信息不全、店铺信息缺失、不同店铺空间距离太近等等挑战。出题方提供了2017年8月大概100家商场的详细数据,包括用户定位行为和商店等数据(已脱敏),要求通过对数据的分析处理来对下一个月做出预测。
已知信息,表一二:


应用工具:
Python语言、numpy库、pandas库
数据分析:
拿到这么多数据时,首先想到的是mall的数量,竟然已经知道每家shop都在那个mall中,那么就做第一个分类,将各个shop按mall分组(mall数量:75,shop数量:8477, 一个mall中包含[46,220]shop),共97组。
数据中比较明显的特征是经纬度,经纬度可以做一个shop中mall的粗略定位,于是做出位置的散点图:
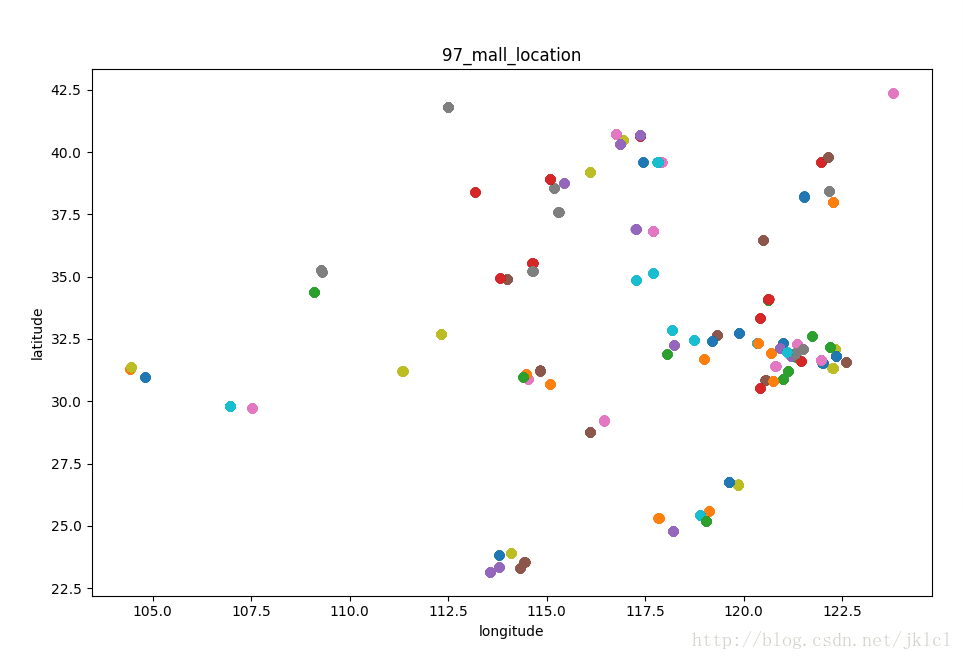
挑选多组来看,还是可以用的,点与点之间的距离相对是比较离散的,也存在特别密集的地方,如果经纬度再精确一点,就可以直接拿经纬度来进行准确定位了,但是目前的数据效果并不明显,而且还降低了准确率,原因是1、位置不是很准确;2、存在不同楼层的情况。
除此之外WiFi也是一个比较惹人注意的一个特征,一个用户的WiFi信息包含1-10条(90%是10条),
WiFi信息包含WiFi名、WiFi强度、是否连接WiFi,容易想到的是将这些信息整合起来,一个shop对应许多WiFi,将WiFi作为一个特征,如果测试集中的用户检测到的WiFi和哪家shop越相似(wifi对应数量和强度差值大小),那么我们更有把握说此用户在哪家shop中,由此来想就有了比较明确的方向,至于里边的数据处理,放在后边分析,目前有了比较重要的特征。

shop的人均消费指数这一特征,没什么用,至少我还不知道怎么用,至于那些大牛们他们应该也自己的见解。
shop的类型一直是我打算入手的一部分,但是看了大牛们的聊天,类型的使用并没有是通过时间反映出来的,主要来区分早午晚餐、夜店、白天非饭点经营店铺(衣鞋、首饰等),那么每天的时间点变成了一个间接的分类对象,初次之外
一家shop出现wifi数量[1, 3330]个(包含个人热点的干扰)
解题思想:
1、读取文件:pandas库中的Dataframe是对二维数据进行处理的有用工具,在较多数据分析中有应用,无论是matplotlib还是其他的库都支持直接操作,pandas.read_csv(file_name)读取表格成Dataframe格式,获取有用的数据特征。
2、分文件储存:97家mall,97个文件逐个将所有的mall的信息放到不同的mall文件中,共97个文件,文件内容:mall:{shop_id; time; wifi}(暂时用的的信息,之后还会放入有用的特征)。
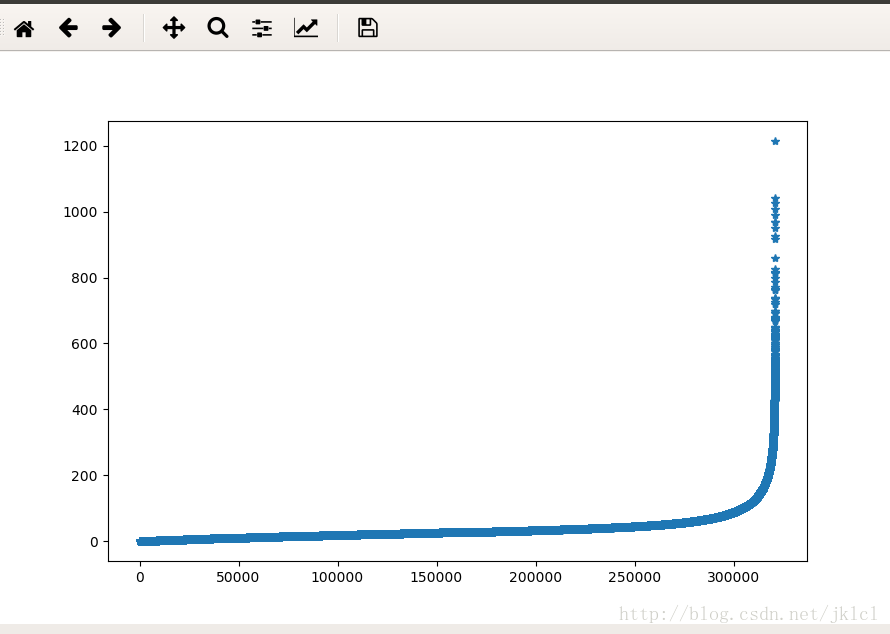
3、算法实现1:已知每家shop可以检测到的所有WiFi以及WiFi强度(一个WiFi出现多次,取平均),拿到测试集,一个user所处地点能检查到的所有的WiFi信息,作比对,wifi出现次数最多,并且wifi强度越相近,我们可以认为在这家商铺。训练结果在85左右,于是提交的一次,84分,可以看出wifi算是比较重要的特征之一,如何强化这个特征,提高WiFi的利用率呢?在之前的数据分析中可以看到,算法实现1存在很严重的问题:首先在一家shop中同一wifi出息的次数没有做很好的处理,举个例子来说吧,例如W_12335在S_1578中出现了1次,强度是-85,W_12336在S_1578中出现了50次,平均强度是-77,明显W_12335是个移动热点,而W_12336是固定的wifi,所以这两个WiFi就不能同等对待;其次对于强度平均值来说,也是一个错误的处理,数据分析中一个Wifi在一家shop中的强度方差会出现5%的大于200,甚至有到达1200的,那么这就有问题了。
4、算法实现2:加权打分,wifi出现次数 c1,强度经过剔除影响方差的异常数据后为s1,user的wifi强度s2,user和shop对应wifi数量c2,[1/c1,abs(s1-s2)/100]*W1+1/c2*W2得到分数,
分数最小的确定shop,W1,W2需要用训练集训练,过程比较慢,效果提高不是很明显。
5、算法实现3:算法模型,看了一些大神的操作,决定还是用模型来跑一下,剔除移动热点,一个mall一个模型,wifi作为众多的特征,又上了时间戳,时间戳主要是用来区分早、中、晚、工作日、双休五个特征,通过降维和数据归一化,跑了随机森林的模型,训练效果挺不错的,但是忙着准备考试,还没提交就结束比赛了,很遗憾没有进复赛。
存在问题与总结:
问题1、偏向使用某一特征,一开始咬住WiFi这一特征来做处理,虽然可以达到84以上,但是再怎么做优化也到不了90,虽然也对经纬度做了分析,但是对时间戳等几个特征的分析几乎没有。
解决方法:不主观的认为某一特征有没有用,将特征分下去做逐个分析,尽量挖掘每一个特征和结果的关系。
问题2、拿到特征后对特征分析不够详细,本次比赛对WiFi的处理,盲目的直接使用模型,盲目的同等对待每一个点,盲目的根据自己的感觉写打分函数。
解决方法:加强交流,将自己的分析结果分享出来,多让别人找问题;对于使用的算法或模型,写出使用的原因,分析自己使用的合理性、准确性。
问题3、时间复杂性,跑程序占用太多时间
解决方法:熟悉hadoop分布式,提高效率