题目描述:
给定一个乱序的单链表的头节点,对该链表中的节点进行排序
要求时间复杂度为O(nlgn),空间复杂度为O(1)
分析:
由于题目要求时间复杂度我O(nlgn),因此选择排序和插入排序可以排除。
在排序算法中,时间复杂度为O(nlgn)的主要有:归并排序、快速排序、堆排序。
其中堆排序的空间复杂度为(n),也不符合要求,因此也可以排除。
归并排序在对数组进行排序时,需要一个临时数组来存储所有元素,空间复杂度为O(n)。但是利用归并算法对单链表进行排序时,可以通过next指针来记录元素的相对位置,因此时间复杂度也为O(1)。
因此可以考虑用快排和归并来实现单链表的排序。
快速排序:
快速排序的主要思想是:
1)选定一个基准元素
2)经过一趟排序,将所有元素分成两部分
3)分别对两部分重复上述操作,直到所有元素都已排序成功
因为单链表只能从链表头节点向后遍历,没有prev指针,因此必须选择头节点作为基准元素。这样第二步操作的时间复杂度就为O(n)。由于之后都是分别对两部分完成上述操作,因此会将链表划分为lgn个段,因此时间复杂度为O(nlgn)
示意图如下:

代码:
void swap(int *a,int *b){
int t=*a;
*a=*b;
*b=t;
}
ListNode *partion(ListNode *pBegin,ListNode *pEnd){
if(pBegin==pEnd||pBegin->next==pEnd) return pBegin;
int key=pBegin->val; //选择pBegin作为基准元素
ListNode *p=pBegin,*q=pBegin;
while(q!=pEnd){ //从pBegin开始向后进行一次遍历
if(q->val<key){
p=p->next;
swap(&p->val,&q->val);
}
q=q->next;
}
swap(&p->val,&pBegin->val);
return p;
}
void quick_sort(ListNode *pBegin,ListNode *pEnd){
if(pBegin==pEnd||pBegin->next==pEnd) return;
ListNode *mid=partion(pBegin,pEnd);
quick_sort(pBegin,mid);
quick_sort(mid->next,pEnd);
}
ListNode* sortList(ListNode* head) {
if(head==NULL||head->next==NULL) return head;
quick_sort(head,NULL);
return head;
} 归并排序:
归并排序的也是基于分治的思想,但是与快排不同的是归并是先划分,然后从底层开始向上合并。
归并排序的主要思想是将两个已经排好序的分段合并成一个有序的分段。除了找到中间节点的操作必须遍历链表外,其它操作与数组的归并排序基本相同。
代码:
ListNode* merge_sort(ListNode* head) {
if(head == NULL || head->next == NULL)
return head;
ListNode* head1 = head;
ListNode* head2 = getMid(head); //获取中间节点,将链表分为两段
head1 = merge_sort(head1); //分别对两段链表进行排序
head2 = merge_sort(head2);
return merge(head1, head2); //将两段有序链表合并
}
ListNode* merge(ListNode* head1, ListNode* head2) //合并两个有序链表
{
ListNode* newhead = new ListNode(-1);
ListNode* newtail = newhead;
while(head1 && head2)
{
if(head1->val <= head2->val)
{
newtail->next = head1;
head1 = head1->next;
}
else
{
newtail->next = head2;
head2 = head2->next;
}
newtail = newtail->next;
newtail->next = NULL;
}
if(head1) newtail->next = head1;
if(head2) newtail->next = head2;
return newhead->next; //链表头节点
}
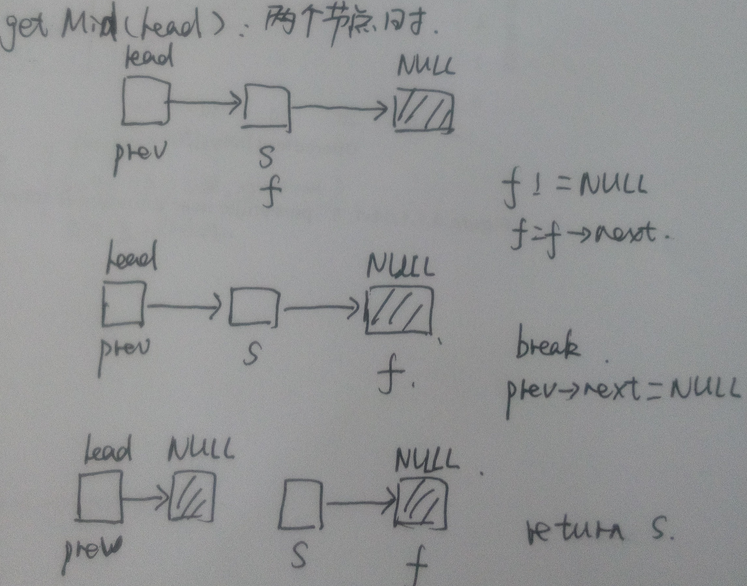
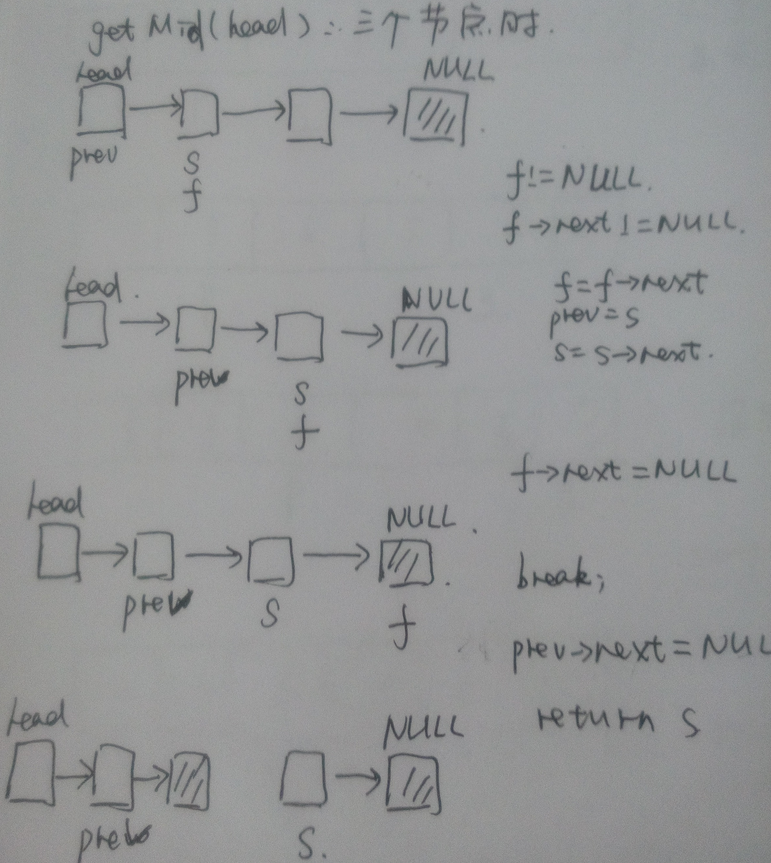
ListNode* getMid(ListNode* head) //获取中间节点并分段
{
ListNode* fast = head->next;
ListNode* slow = head->next;
ListNode* prev = head;
while(true)
{
if(fast == NULL) break;
fast = fast->next;
if(fast == NULL) break;
fast = fast->next;
prev = slow;
slow = slow->next;
}
prev->next = NULL; //将链表分为两段
return slow;
} 因此归并排序的关键在于将单链表变为两个排序好的分段。
getMid 示意图如下: