我们本次爬取湖州市统计局网站各个月份的工业运行数据。http://tjj.huzhou.gov.cn,我们需要爬取的网页索引页http://tjj.huzhou.gov.cn/tjsj/ydsj/index.html,需要具体需要数据所在相应页面。
1、准备工作
1.python基础
2.安装pyspider
3.可以忍受在网页写代码
4.编成达人请移步文章底部
2、编写爬虫
1.启动pyspider
pyspider all2.如果是本地环境浏览器访问localhost:5000我们可以看到如下页面
点击create创建项目,输入项目名以及我们要爬取网页索引页的地址

点击create创建项目,点击进入页面中的run进入下方界面,左侧为webUI自带任务监视器,右侧为代码编辑器。


class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://tjj.huzhou.gov.cn/tjsj/ydsj/index.html', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}- def on_start(self)是脚本的入口。点击run按钮时将调用它。
- self.crawl(url, callback=self.index_page)*这是最重要的API。它将添加一个要被爬取的新任务。
- def index_page(self, response)得到一个Response*对象。response.doc*是一个pyquery对象,我们可以通过它来拿到我们需要的数据。
- def detail_page(self, response)返回一个dict对象作为结果。我们需要在这个方法中编写代码处理最终爬取到的数据,结果将resultdb默认捕获。我们可以重写on_result(self, result)方法来自行管理结果。
点击调试器上的run,我们可以看到follwos出现了一个1,点击它我们可以看到我们在创建项目是URL上填写的地址。

点击链接右侧的小箭头,我们应该会进入具体我们需要爬取数据所在页面的目录页,我们会看到网站给我门返回了一个403 Forbiden,惊了! why?

这是由于这个网站的安全机制,没关系,我们只需要设置一个代理去模拟浏览器即可,指定self.crawl方法中指定user_agent参数。
agent='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/51.0.2704.63 Safari/537.36'
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://tjj.huzhou.gov.cn/tjsj/ydsj/index.html',user_agent=self.agent, callback=self.index_page)重新运行项目(注意我们需要点击调试器的返回上一步按钮回到之前的方法去运行)这时我们可以看到给我们返回了很多条请求地址但是我们会发现这里并没有我们需要的url。点开web我们会发现,并没有显示我们需要的数据,惊了 why?

我们可以看到原本应该显示各个月份数据的目录为空,这是由于这部分时由JS渲染的。这是我们只需指定self.craw的fetch_type参数为js,前提是你已经安装了phantomjs,要是没装pyspider也没辙。
self.crawl('http://tjj.huzhou.gov.cn/tjsj/ydsj/index.html', user_agent=self.agent,callback=self.index_page,fetch_type='js')重新运行我们可以看到这时我们拿到了所有的url,但是这其中有很多是没用的url,这是我们只需修改index_page中选择器response.doc()的筛选条件即可,这时我们就筛选出了我们需要的url。
def index_page(self, response):
for each in response.doc('a[href^="http://tjj.huzhou.gov.cn/xxgk/tjxx/tjsj"]').items():
self.crawl(each.attr.href, callback=self.detail_page, user_agent=self.agent) 
做到这步我们发现一个问题,网站上各个月份的数据很多,前端显示做了分页。通常来说我们只需获取下一页的链接并且在index_page方法中回调自身即可实现翻页,但是当我们点击下一页时,我们发现这个网站点下一页时是ajax局部更新的,我们无法获取下一页的链接,惊了!这可怎么办。
这时我们终于想起F12大法好,我们在目录页面http://tjj.huzhou.gov.cn/tjsj/ydsj/index.html,点击F12,依次点击Nework-->XHR,以及网页上的下一页按钮我们可以看到刷出了XHR文件。

点开XHR文件,我们可以看到请求后台的请求URL,以及最下方请求所带的参数。

我们来看看它的参数,pageno没用,channeild不知道是个什么,嗯pagesize就决定是你了。

我们在浏览器打开这个请求,带上参数pagesize=300,channelid=12746。果然得到了所有数据。

好了现在我们将on_start中的url更改为我们拿到的url,指定为POST方法,带上参数。
self.crawl('http://tjj.huzhou.gov.cn/hzgov/openapi/info/ajaxpagelist.do', callback=self.index_page,user_agent=self.agent,
method='POST',data={'channelid': 23746, 'pagesize':50})
# 参数 pagesize指定当前页显示多少条数据,只爬取最近50个页面现在请求得的到的将不再是页面而是JavaScript Object Notation数据,所以index_page方法中的代码也需要作相应得更改,分析相应json格式拿到url。
def index_page(self, response):
for each in response.json['infolist']:
self.crawl(each['url'], callback=self.detail_page, user_agent=self.agent,
)好了现在我们可以轻松的拿到我们要爬取得所有页面了。之后就是爬取详情页面我们需要得数据了。
我们只需在detail_page方法中通过response.doc().text()API并在doc()中传入相应selector即可拿到我们所需要得数据。
通常情况下我们可以通过webUI自带的工具拿到数据,方法如下。
点击调试器得web->enable css selector helper ,选中需要拿的数据,点击右上方小箭头即可拿到选择器。
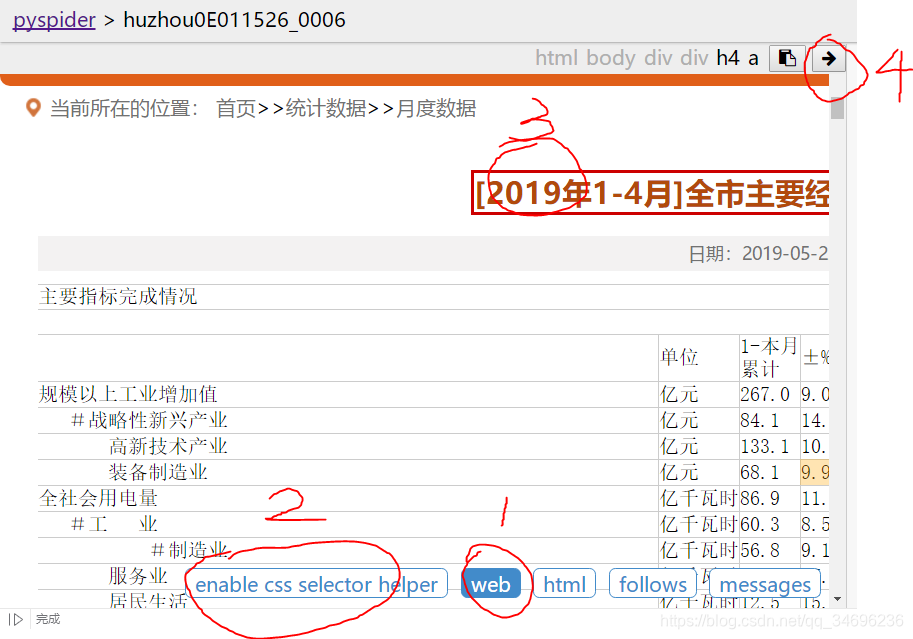
但 。。。。。啊?????惊了!why?

这个时候我们需要到浏览器中打开F12,选择element找到相应数据,右键点击选择copy selector即可。
value = response.doc('body > div.hz_bg1 > div.hz_xl_main > div > table > tbody > tr:nth-child(13) > td:nth-child(1)').text()之后我们只需在return返回相应变量即可在控制台看到我们的数据。
return {
"url": url,
"title": response.doc('title').text(),
"value":value
}好了至此我们已经可以拿到我们需要的数据了
三、存入Mysql数据库
我们只需初始化数据库连接,然后写一个数据库操作方法并在detail_page方法中调用即可
#连接数据库
def __init__(self):
self.db = pymysql.connect('localhost', 'root', '952866', 'huzouspider', charset='utf8')
def add_Mysql(self, value, date, release_date, url):
try:
cursor = self.db.cursor()
sql = 'insert into ie011531(value, date, release_date, url, area) values ("%s","%s","%s","%s","湖州")' % (value, date, release_date, url)
print(sql)
cursor.execute(sql)
print(cursor.lastrowid)
self.db.commit()
except Exception as e:
print(e)
self.db.rollback()# 在detail_page中调用
self.add_Mysql(value,date,release_date,url)四、说明
注解说明
修改代码中def on_start(self):方法上@ every注解配置定时任务,单位为分钟例如@every(minutes=31 * 24 * 60)为每31天重新执行一次爬取。在def index_page:方法上配置请求过期时间单位为秒,例如@config(age=31 * 24 * 60 * 60)为请求的过期时间为31天,在重新爬取时会判断该当前请求是否过期,若该条请求过期则重新爬取该页面,反之忽略该条请求,在on_statr方法中指定itag参数,这个参数指向目录页面某个值,这个值应当选取一个当这个目录页面发生变化时会变的值,若目录页这个值未发生变化那么就意味着目录页未发生变化pyspider则不重新执行爬取。@config(priority=2)指定爬取优先级
self.crawl主要参数说明:
callback:执行完当前方法后的回调函数。
fetch_type:指定fetch的类型
user_agent:设置代理
headers:指定请求头
Itag:指定页面标记,用于判断页面是否发生变化,不发生变化时不重新进行爬取。
prams:发送请求时添加到URL上的参数列表
data:发请求时附带的请求body
dashboard控制面板
Group:该项目的分组
Status:该项目状态
Rate:请求发送速度单位为 个/秒,数值越大爬取速度越大
Burst:数值越大爬取速度越大
Progress:最近时间内请求情况
五、完整代码
from pyspider.libs.base_handler import *
import pymysql
import json
class Handler(BaseHandler):
crawl_config = {
}
#连接数据库
def __init__(self):
self.db = pymysql.connect('localhost', 'root', '952866', 'huzouspider', charset='utf8')
def add_Mysql(self, value, date, release_date, url):
try:
cursor = self.db.cursor()
sql = 'insert into ie011531(value, date, release_date, url, area) values ("%s","%s","%s","%s","湖州")' % (value, date, release_date, url)
print(sql)
cursor.execute(sql)
print(cursor.lastrowid)
self.db.commit()
except Exception as e:
print(e)
self.db.rollback()
# 代理模拟浏览器
agent='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/51.0.2704.63 Safari/537.36'
# 每31*24*60分钟爬取一次
@every(minutes=31 * 24 * 60)
def on_start(self):
self.crawl('http://tjj.huzhou.gov.cn/hzgov/openapi/info/ajaxpagelist.do', callback=self.index_page,user_agent=self.agent,
method='POST',data={'channelid': 23746, 'pagesize':50})
# 参数 pagesize指定当前页显示多少条数据,只爬取最近50个条数据
# request过期时间10年
@config(age=10 * 12 * 30 * 24 * 60 * 60)
def index_page(self, response):
# print(response.json['infolist'])
for each in response.json['infolist']:
# print(each)
self.crawl(each['url'], callback=self.detail_page, user_agent=self.agent,
)
# itag指定增量爬取条件,当itag结果变化时才进行重新爬取
# 翻页 获取下一页内容
#next = response.doc('.next').attr.onclick
#self.crawl(next,callback=self.index_page,fetch_type="js")
@config(priority=2)
def detail_page(self, response):
# 指标名称
policy_id = str("IE011526-0006")
# 来源
url = response.url
# 页面创建日期用于判断
dates = int(url[35:43])
print(dates)
# 发布日期
release_date = str(dates)
# 格式化月份
date = response.doc('h4 > a').text()[1:10]
if date[0]!='2':
date = response.doc('.title1').text()[0:9]
if date[8] == '月':
date = date[0:4]+'-'+date[7]+'-'+'01'
else:
date = date[0:4]+'-'+date[7:9]+'-'+'01'
print(date)
# 标题
title = response.doc('title').text()
# 上下册
wd = title[len(title)-3:len(title)-1]
print(wd)
# 规则
selecter = ''
if wd == '上册':
index = response.doc('body > div.hz_bg1 > div.hz_xl_main > div > table > tbody > tr:nth-child(13) > td:nth-child(1)').text()
print(index)
if dates >20170301:
if index == '商品房销售面积':
# 20181019
selecter = 'body > div.hz_bg1 > div.hz_xl_main > div > table > tbody > tr:nth-child(79) > td:nth-child(3)'
elif index == '固定资产投资':
# 20190522
selecter = 'body > div.hz_bg1 > div.hz_xl_main > div > table > tbody > tr:nth-child(83) > td:nth-child(3)'
elif index == '':
index = response.doc('body > div.hz_bg1 > div.hz_xl_main > div > div > div > table > tbody > tr:nth-child(13) > td:nth-child(1)').text()
print(index)
if index == '商品房销售面积':
# 20180322
selecter = 'body > div.hz_bg1 > div.hz_xl_main > div > div > div > table > tbody > tr:nth-child(81) > td:nth-child(3)'
elif index == '固定资产投资':
# 20171017
selecter = 'body > div.hz_bg1 > div.hz_xl_main > div > div > div > table > tbody > tr:nth-child(85) > td:nth-child(3)'
# 2017 6 月之前格式
if 20120101<=dates<20170301:
selecter = 'body > div.hz_bg1 > div.hz_xl_main > div > div > div > table > tbody > tr:nth-child(88) > td:nth-child(3) > p'
# print(selecter)
# 计算机、通信和其他电子设备制造业-行业工业增加值增速
value = response.doc(selecter).text()
self.add_Mysql(value,date,release_date,url)
else :
value = '下册中无该指标'
return {
"url": url,
"title": response.doc('title').text(),
"value":value,
"release_date":release_date,
"date":date ,
"policy_id":policy_id,
}