前言
昨天实现了草榴的爬取 nodejs 做一个简单的爬虫爬草榴,今天对代码做了一部分修改,增加了可以指定开始页和结束页,并且给所有文件都单独创建了文件夹。那么问题来了,说好的爬 街拍图片 呢?毕竟爬完草榴的东西并不适合展示,所以,今天又尝试了一下爬今日头条的街拍图片。Talk is cheap,show me the code,废话不多说,直接进入正题。
准备工作
看过昨天的文章的话可以跳过准备工作和创建工程,直接进入今日头条街拍图片代码。
依旧是下载nodejs,真的觉得自己什么都说了,就差配置环境变量了。不过现在应该下载完直接添加环境变量了吧,或者自己到网上搜一下,一大堆。
创建工程
- 首先,在你想要放资源的地方创建文件夹,比如我在 E 盘里面创建了一个 myStudyNodejs 的文件夹。
- 在 DOS 里面进入你创建的文件夹 如图
- 进入 e 盘:E:
- 进入文件夹:cd myStudyNodejs(你创建的文件夹的名字)
注意全是英文符号
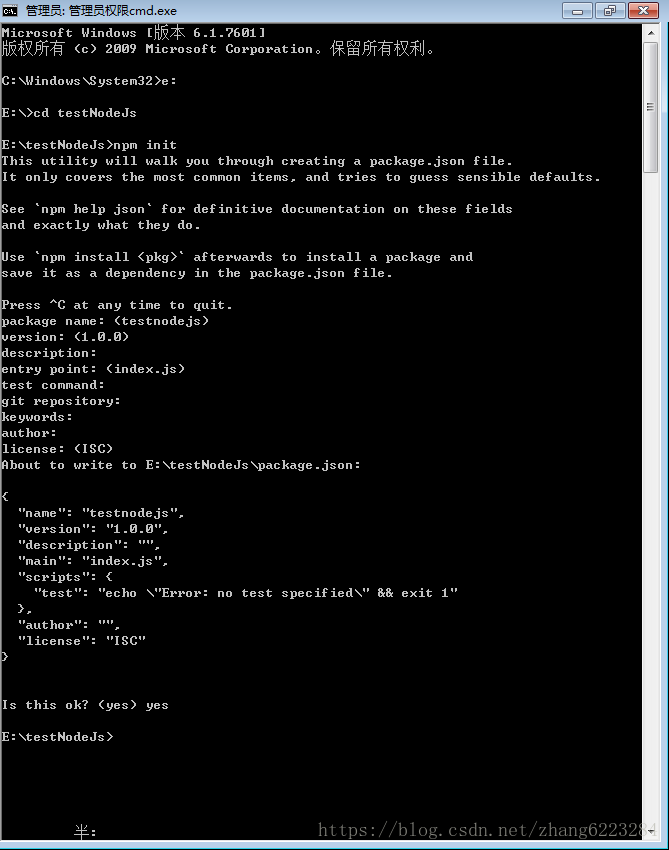
- 初始化项目,在你创建的文件夹下面运行 npm init 初始化项目。一路回车,最后输个 yes 就行。
- 运行完以后,会在文件夹里面生成一个 package.json 的文件,里面包含了项目的一些基本信息。
- 安装所需要的包
npm install request -save 注意因为头条是动态网页,所以无法用 cheerio 来分析网页,所以只需要这一个包就足够了 - 创建文件
- 创建一个 image 文件夹用于保存图片数据。
- 创建一个 js 文件用来写程序。比如 study.js。(创建一个记事本文件将 .txt 改为 .js)
说明 –save 的目的是将项目对该包的依赖写入到 package.json 文件中。
今日头条爬虫代码
爬取今日头条过程中遇到的最大问题就是今日头条界面是动态生成的,图片链接存储在 script 标签中,所以不能用 cheerio 模块来解析,只能通过正则表达式进行匹配。
首先在今日头条界面搜索街拍,因为文章和图集里面的链接区别比较大,所以我们点击图集,只爬图片。
按 F12 打开开发者工具,在 network 里面找到 XHR(需要重新刷新才会出现资源)。
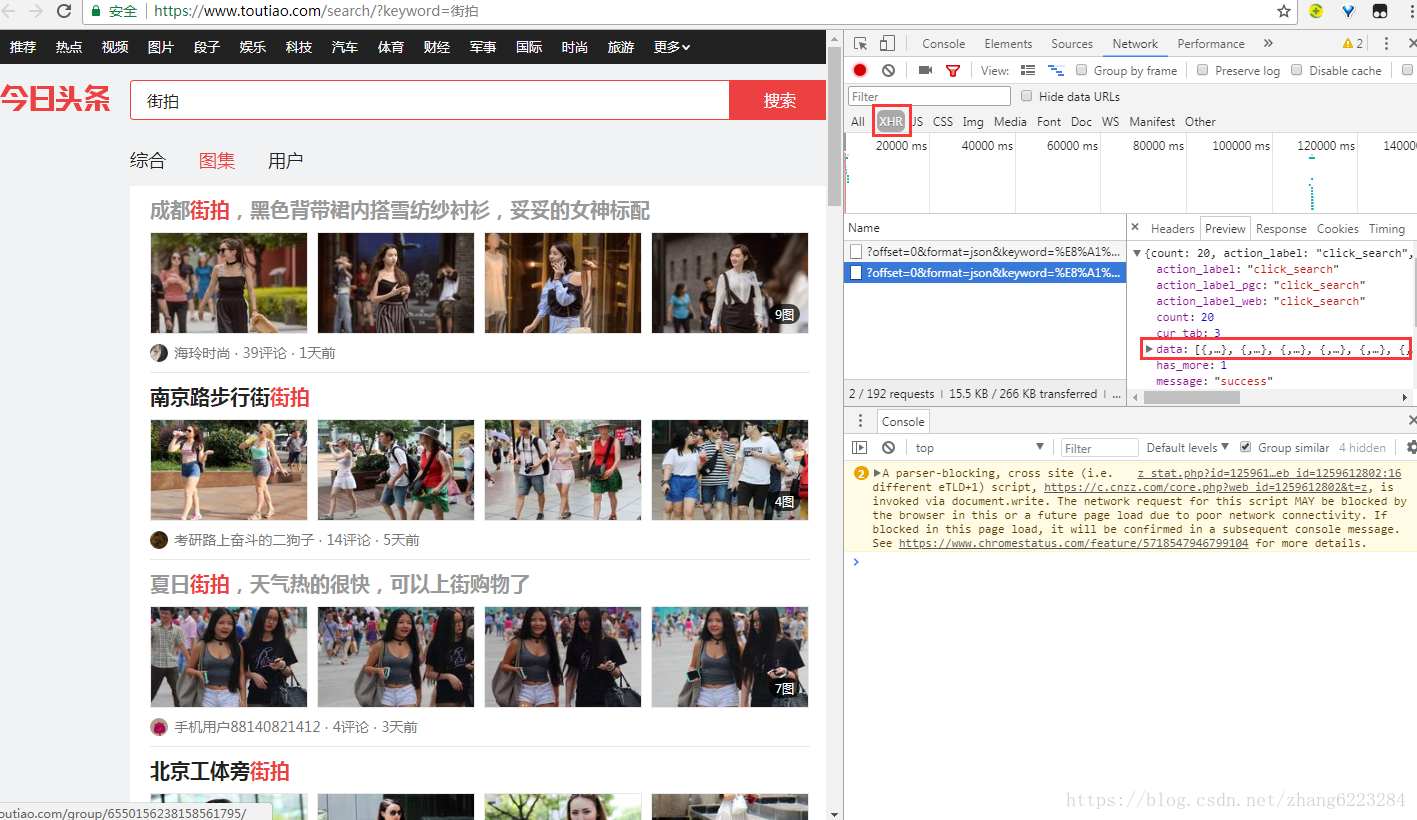
因为界面是动态生成的,所以我们要找的 URL 全都存在这里面。
点开 data,找到我们需要的 URL。
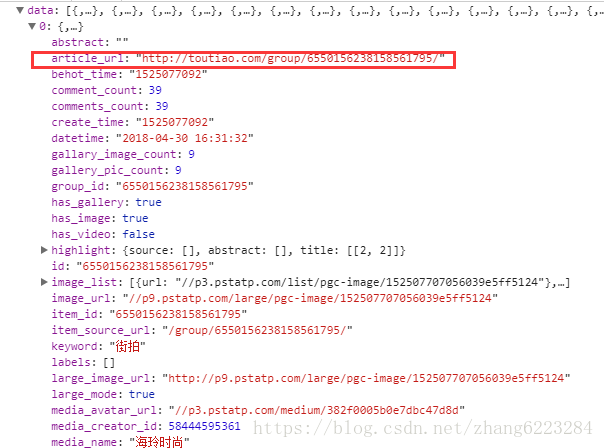
这里注意一点,这个 url 里面用的是 http 的请求,并且路径上面多了一个 group,所以我们要重新拼接一下。
x.url='https://www.'+x.url.substring(7,19)+'a'+x.url.substring(25);接下来就是发起请求,获取界面数据。我们所需要的图片路径如下。
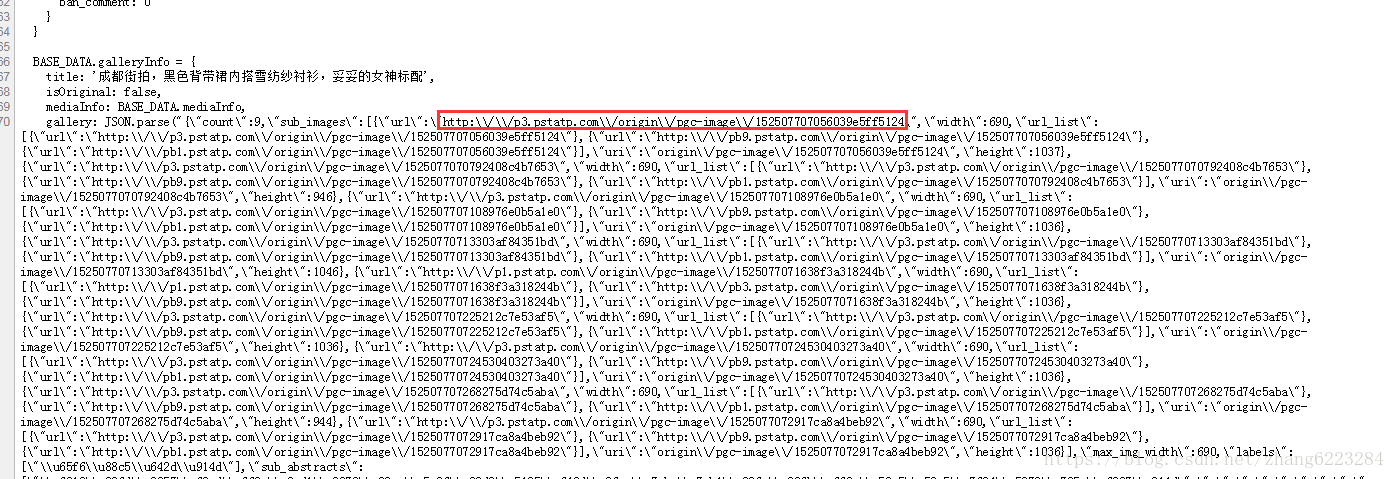
分析几个页面图片的路径得出我们需要使用的正则表达式
let reg=/http\:\\\/\\\/p\d\.pstatp\.com\\\/origin(\\\/pgc\-image)?\\\/[A-Za-z0-9]+/g;这个正则表达式不难,但是应该是我写过的最长的了,其中 \\/pgc-image 这一段有的图片路径没有,所以用 ? 来匹配 0 次或 1 次。注意不要匹配最后的 \,不然无法正确获取路径。 接下来就是把获取的文件保存下来。匹配下来的 URL 是 http:/\/\ 这种模式,需要自己重新设置。
var img_src = 'http://'+item.substring(9);接下来,就是把图片下载到本地。
下面是完整源码
/*
* @Author: user
* @Date: 2018-04-30 12:25:50
* @Last Modified by: user
* @Last Modified time: 2018-04-30 22:02:59
*/
var https =require('https');
var http = require('http');
var fs = require('fs');
var request = require('request');
let startPage=0;//从哪一页开始爬
let page=startPage;
let endPage=1;//爬到哪一页
//初始请求地址
var url='https://www.toutiao.com/search_content/?offset='+startPage*20+'&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=3&from=gallery'
var i = 0;
//用来判断存储还是访问
var temp=0;
//存储首页url
urlList=[];
//封装了一层函数
function fetchPage(x) {
setTimeout(function(){
startRequest(x); },2000)
}
//首先存储要访问界面的url
function getUrl(x){
temp++;
https.get(x,function(res){
var html = '';
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
html = JSON.parse(html);//由于获取到的数据是JSON格式的,所以需要JSON.parse方法浅解析
for(let i of html.data){
var obj1={title:i.title,url:i.article_url};
urlList.push(obj1)
}
page++;
if(page<=endPage){
let tempUrl='https://www.toutiao.com/search_content/?offset='+page*20+'&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=3&from=gallery';
getUrl(tempUrl);
}
else{
fetchPage(urlList.shift());
}
})
}).on('error', function (err) {
console.log(err);
});
}
function startRequest(x) {
if(temp===0){
getUrl(x);
}
else{
//采用http模块向服务器发起一次get请求,截取的字符串为文章链接地址
x.url='https://www.'+x.url.substring(7,19)+'a'+x.url.substring(25);
setTimeout(function(){
https.get(x.url, function (res) {
var html = ''; //用来存储请求网页的整个html内容
res.setEncoding('binary');
//监听data事件,每次取一块数据
res.on('data', function (chunk) {
html += chunk;
});
//监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数
res.on('end', function () {
var news_item = {
//获取文章的标题
title: x.title,
//i是用来判断获取了多少篇文章
i: i = i + 1,
};
console.log(news_item); //打印信息
//用来匹配script中的图片链接
let reg=/http\:\\\/\\\/p\d\.pstatp\.com\\\/origin(\\\/pgc\-image)?\\\/[A-Za-z0-9]+/g;
let imageList=[];
imageList=html.match(reg);
savedImg(imageList,x.title);
//如果没访问完继续访问
if (urlList.length!=0 ) {
fetchPage(urlList.shift());
}
});
}).on('error', function (err) {
console.log(err);
});},2000)
}
}
function savedImg(imageList,title){
fs.mkdir('./image/'+title, function (err) {
if(err){console.log(err)}
});
imageList.forEach(function(item,index){
var img_title = index;//给每张图片附加一个编号
var img_filename = img_title + '.jpg';
//图片的url需要转换一下
var img_src = 'http://'+item.substring(9); //获取图片的url
//采用request模块,向服务器发起一次请求,获取图片资源
request({uri: img_src,encoding: 'binary'}, function (error, response, body) {
if (!error && response.statusCode == 200) {
fs.writeFile('./image/'+title+'/' + img_filename, body, 'binary', function (err) {
if(err){console.log(err)}
});
}
})
})
}
fetchPage(url); //主程序开始运行接下来在创建的文件夹下面运行
node study.js
OK,大功告成
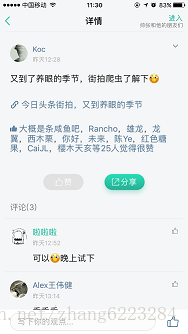
下面是成果展示,这次不用打码了
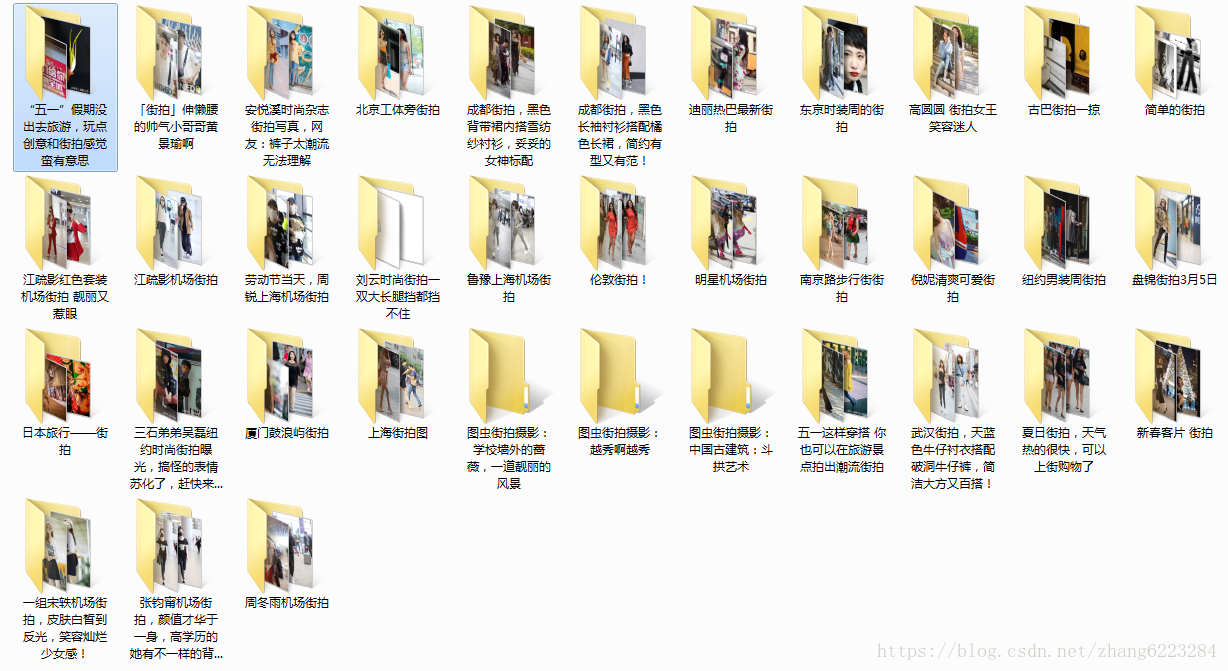
后记
今天在网上找了一天该怎么爬动态界面也没找到类似的,最后只能用正则表达式来匹配,哪位大佬知道更好的方法望不吝赐教。这两天对基本的爬虫已经了解了,现在爬动态和静态网页大概知道从哪下手,对开发者工具的理解也稍微深了一点,下面准备尝试一下异步和并发爬取,改善一下代码,因为自己也没做过异步并发的东西,顺便也加深一下自己对这方面的概念。