在知乎上看到这篇文章,插图风格不错,决定看看,顺手翻译,欢迎指正~
How a Kalman filter works, in pictures
http://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/Improving IMU attitude estimates with velocity data
http://www.bzarg.com/p/improving-imu-attitude-estimates-with-velocity-data/译文尽量尊重原著。。。。
CSDN 的 Markdown 好像不支持公式的自动编号,所以只能手动添加了。略丑,见谅……
我不得不给你们讲讲卡尔曼滤波器,因为它的作用真的是太惊人了。
令人惊讶的是似乎很少有软件工程师和科学家知道这个,这让我很伤心。因为它是如此全面、强大的工具,用于在不确定的情况下进行信息融合(combining information)。有时,它提取精确信息的能力几乎不可思议——如果你觉得我说的太夸张,可以看一下我之前发布的视频,演示了卡尔曼滤波器通过观测速度,得到自由物体的姿态信息。干净利落!
What is it?
它是什么?
你可以在动态系统中任何有不确定信息的地方使用卡尔曼滤波器,也可以对系统下一步将要干什么做出猜测。即使你想要得到的动作 (motion ) 伴随着大量干扰,卡尔曼滤波器通常都能够得出到底发生了什么。而且它可以利用人们无法读懂杂乱现象间的相关性,
卡尔曼滤波非常适合这些不断变化的系统。它们具有的优点是:轻量级存储(它们不需要保存上一状态以外的任何历史数据),计算快速,这使得它们非常适合于实时问题和嵌入式系统。
用于实现卡尔曼滤波器的数学在谷歌的大部分地方都是相当可怕、晦涩的。这是一个糟糕的状态,因为如果你能找到正确的方法,卡尔曼滤波实际上是十分简单、易于理解的。因此,它是一个很好的文章主题,我将试着使用大量清晰漂亮的图片和颜色描述它。前提条件很简单:你们需要对概率和矩阵有一些基本的理解。
我会从一个卡尔曼滤波器所能解决的例子(loose example)开始,但如果你想直接看漂亮的图片和数学公式,可以随意向前跳转。
What can we do with a Kalman filter?
我们能用卡尔曼滤波器做什么?
我们举个玩具的例子:你做了一个小机器人,它可以在树林里散步,所以机器人想要导航就需要知道它的精确位置。

我们说机器人有一个状态
状态就是你系统基本配置(configuration)的数字列表;它可以是任何变量。在这个例子中,状态就是位置和速度,但是它可以是油罐中液体的总量数据、引擎的温度、用户手指在平板上的位置,或者任何你想要观察的数据。
我们的机器人有一个 GPS ,精确约为 10米,状态良好,但是我们对机器人定位的精度要求高于10米。树林里有很多沟和崖,如果机器人走错几英尺,就可能跌落悬崖。所以仅有 GPS 是不够的。
我们还需要知道机器人是怎样移动的:它知道发送给马达的命令,知道是否朝向某个方向,没有障碍,下一步,它可能就沿着这个方向前进。当然,它不可能知道运动过程中的所有状况:它可能被风刮倒,车轮可能打滑,或者在颠簸的路面侧翻;所以轮子的转角并不能精确的表示机器人走了多远,这个预测不是完美的。
GPS 告诉我们一些状态,但只是间接的,并且带有一些不确定性和干扰。我们 预测 机器人是如何运动的,但也是间接的,带有不确定性和干扰。
但是,如果我们使用所有能够获取的信息,我们可以得到一个比这两个由各自传感器得到的估计更好的答案吗?答案当然是肯定的,这就是卡尔曼滤波器要做的。
How a Kalman filter sees your problem
卡尔曼滤波器怎样看待这个问题
让我们看看试图解释的场景。继续使用只有位置和速度的状态。
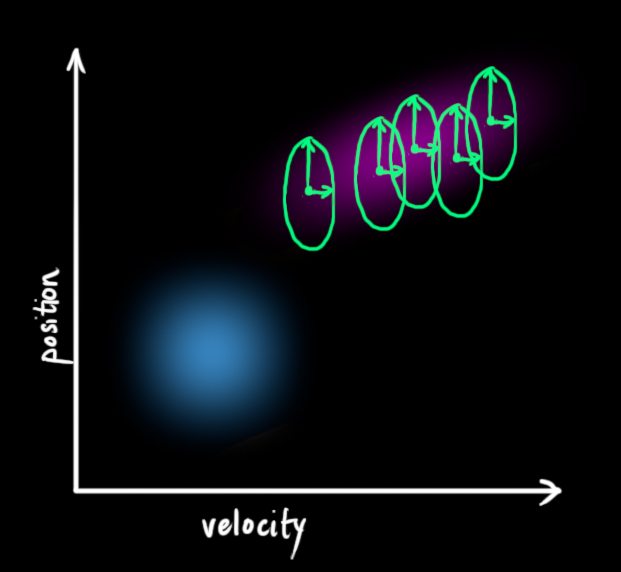
我们并不知道实际的位置和速度;有一系列可能的位置与速度的组合,但是其中的一些可能性更高:

卡尔曼滤波器假设所有的变量(本例中为:位置、速度)都是随机高斯分布(正态分布)的。每个变量都有一个期望

上图中,位置和速度是不相关的。
下面的例子中:位置和速度是相关的。一个指定位置的可能观测值取决于速度:

这种情况一般发生在:我们根据之前的位置估计当前位置。如果速度很快,就会移动很远。反之,就会很近。
这种关系在跟踪定位时非常重要,因为这会提供更多信息:一个测量值告诉我们其他测量值的可能范围。这就是卡尔曼滤波器的目标,我们希望从不确定的测量值中得到尽可能多的信息。
这种相关性由协方差矩阵给出。简单来说,协方差矩阵的每个元素

Describing the problem with matrices
用矩阵描述问题
对高斯斑点进行建模,我们需要两个信息:在
(公式中只使用了本例中的位置和速度。)
接下来,我们看一下当前状态(时刻:k-1 )和预测下一状态 (时刻:k )。我们并不知道哪个状态是真实的,但是预测方程并不关心。它根据所有可能状态,给出一个新的分布:

我们可以用矩阵

它根据原始状态的每一个点,得到新的预测。(如果原始状态中包含真实状态,则预测状态中也包含真实状态)。
我们怎样使用一个矩阵来预测下一时刻的位置和速度?我们将使用基本的运动学方程:
即:
我们现在有了预测下一状态的预测矩阵,但是任然不知道怎样更新协方差矩阵。
我们需要另一个方程。如果我们对分布中的每一个点乘以一个矩阵
这比较简单,我将直接给出:
由
External influence
外部影响
如果状态只根据自身的属性变化,则没有问题。如果状态同时根据外部作用变化,只要我们知道外部作用力的属性,也没有问题。
但是,如果是我们不知道的力呢?比如,四旋翼在飞行中会受到阵风的影响。轮式机器人的轮子可能打滑。如果这种情况发生,而我们没有考虑这些外部因素,我们将无法继续保持对机器的追踪。
我们可以在每一步预测之后增加一些新的不确定因素,以完成对机器人相关的不确定性建模。

在原始估计中的每一个状态都能够转移到一定状态范围。因为高斯斑,可以说,在
这会产生一个新的高斯斑,有新的协方差(相同的期望):

这个扩展的协方差通过加
也就是说,新的最优估计是由上一时刻的最优估计进行预测,加上已知外部影响的修正得到的。
新的不确定性是由上一时刻的不确定性进行预测,加上一些环境中额外的不确定性。
这就简单了,我们有了系统当前状态的模糊估计(
Refining the estimate with measurements
测量值校正估计
我们可能有多个能反映系统状态的传感器。目前,它们测量的是什么并不影响;可能一个测量位置,其他测量速度。每个传感器都间接的给出了一些状态信息,也可以说是传感器作用于一个状态,并产生了一系列读数。
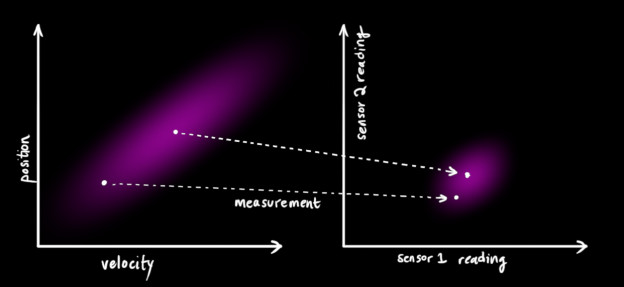
读数的单位和量程可能与状态的不同。你也许能猜到这是怎么回事:我们用矩阵
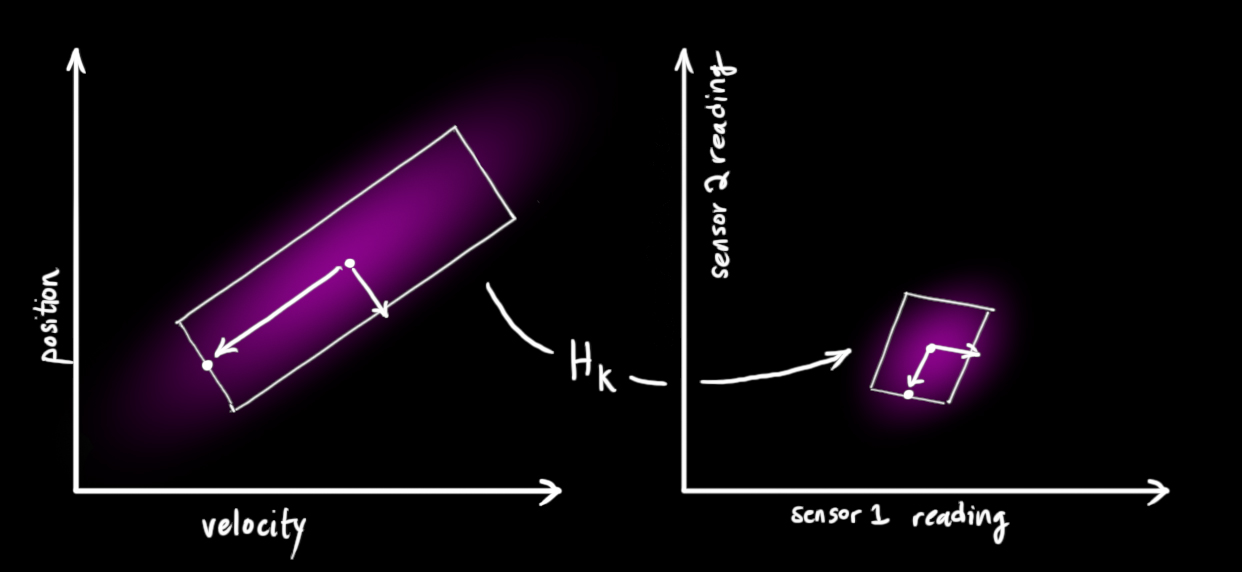
我们能够得到传感器读数的分布:
卡尔曼滤波适合于处理传感器的噪声。也就是说,传感器多少都会有些不可靠性,原始估计中的每一个状态的传感器读数都会是一个范围值。
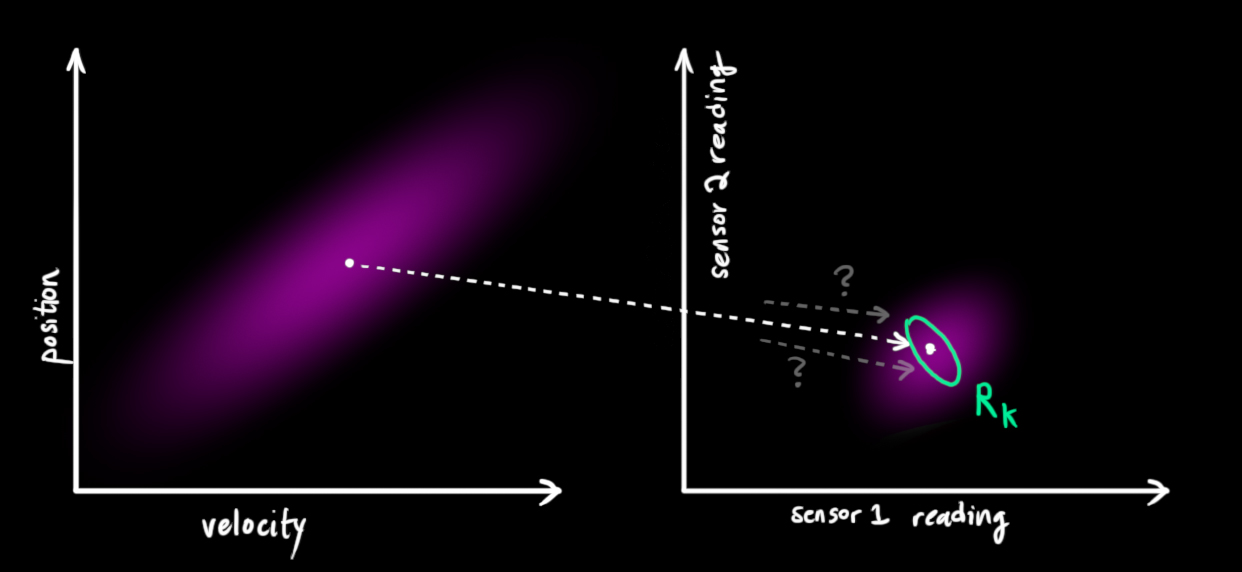
从我们观测到的每一个读数,我们可能猜测系统在一个特定的状态。但是因为存在不确定性,观测到的数据中某些状态的可能性会比较高。

称这个不确定性(传感器噪声)的协方差为
现在,我们得到两个高斯斑:一个表示系统状态预测;一个表示传感器读数。

我们必须设法协调基于预测状态的猜测和基于传感器读数的猜测。
所以,我们的新状态是什么呢? 对于任何可能的读数
如果我们有两个概率,想知道两个都是真的概率,只要把它们相乘即可。因此,我们取两个高斯斑并将其相乘:
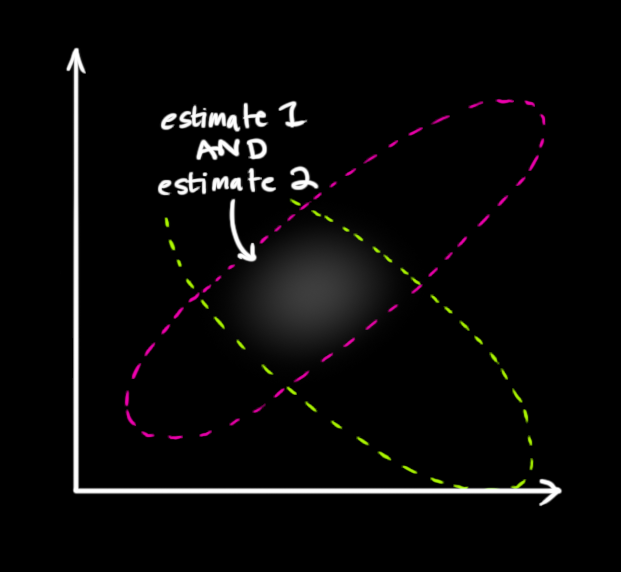
剩下的是重叠部分,原来两个高斯斑都较 亮/可能 的部分。这个结果比之前两个高斯斑都更精确。这个分布的期望是根据两个估计都是最可能的配置得到的,因此,这就是根据我们所有信息能够给出的真实配置的最佳猜测。
恩。。。看起来像是另一个高斯斑。

事实上,当你将两个不同的高斯斑相乘的时候,就得到了一个全新的高斯斑!
我们正在做的就是:得到一个方程,可以从之前的状态获取新的状态。
Combining Gaussians
高斯分布的结合
首先,来看最简单的一维情况。一维高斯曲线(方差:
两个高斯曲线相乘的情况:
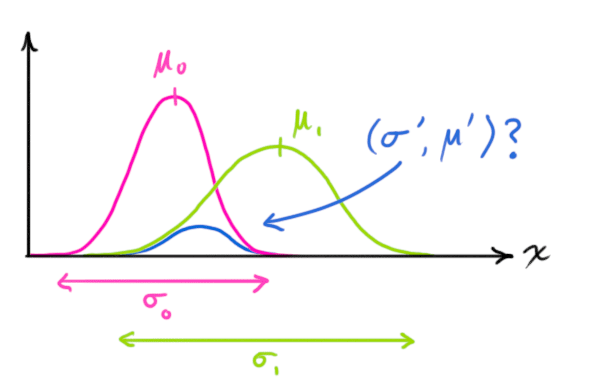
将 [9]式带入 [10]式中,得到:
简化为:
注意你怎样通过之前的估计添加修正,获得当前的估计。看看这个方程多么简单!
将式 [12] 和 [13] 重写为矩阵形式。假设
Putting it all together
综上所述
我们有两个分布:预测,
代入 式 [14] ,得到卡尔曼增益:
将式 [16]、[17] 中的
在此给出了用于更新的完整方程。
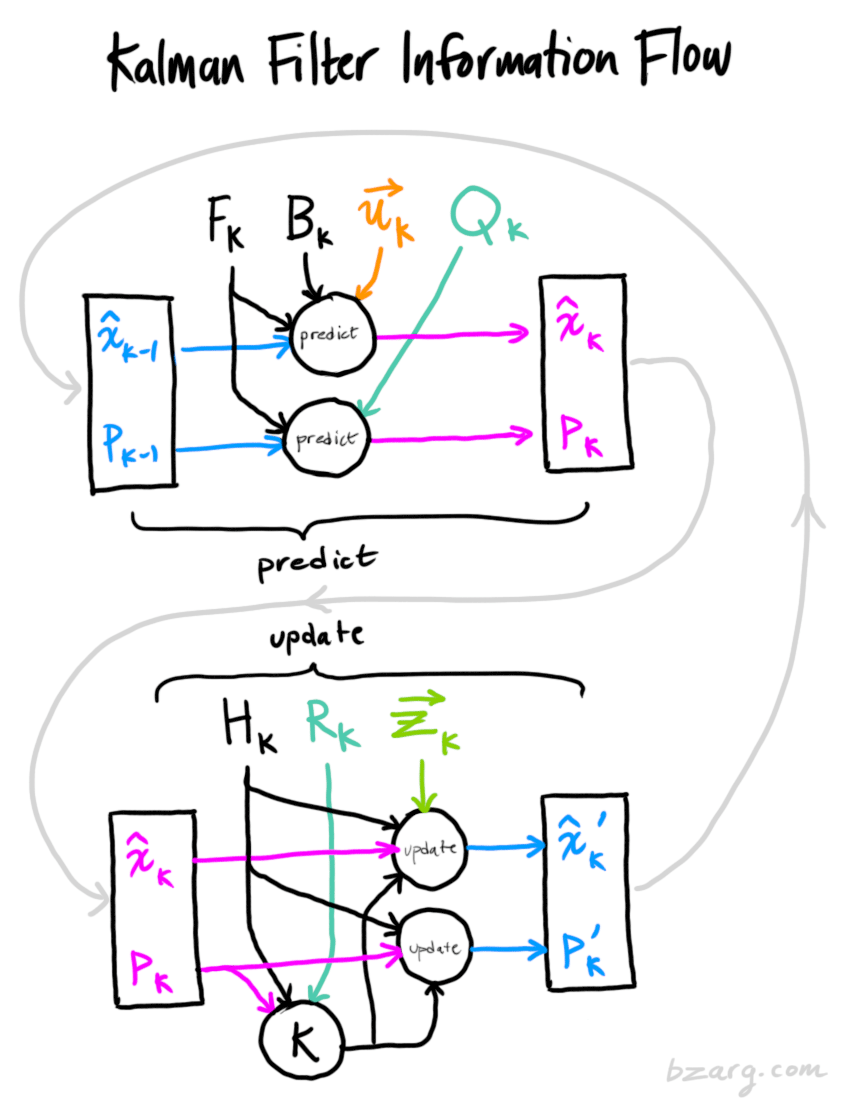
Wrapping up
总结
文中所有的数学公式,你需要使用的是:[7] [18] [19]。(如果你忘了这些,还可以从式 [4] [15] 重新推导)
这可以对任何线性系统进行精确建模。对于非线性系统,可以使用扩展卡尔曼滤波,就是对期望值的预测和测量线性化。(我可能在以后再写一个 EKF的文章)。
如果这篇文章写的还不错,希望人们能够意识到卡尔曼滤波有多么酷,并把它应用到一些新的领域。
相关的推导和证明可以参看这篇文章
文中使用了相似的方法介绍重叠的高斯分布。如果感兴趣的话,可以在文章中找到深入的推导。
该文章发布于:August 11, 2015