今天,我们来爬取红袖添香的小说基本信息,并存入到本地的mysql中,以下是要爬取的界面
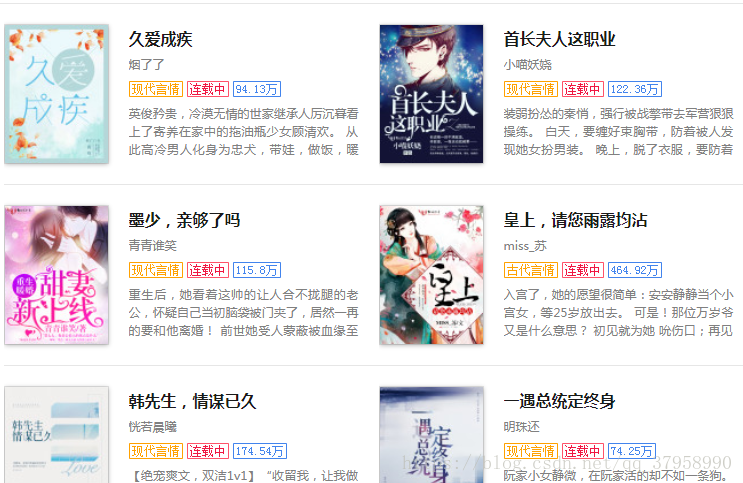
首先,使用scrapy创建项目,创建爬虫,进入到这个页面,我们为了方便直接从这个页面开始爬,而不是从首页。
def parse(self, response):
list=response.xpath('//div[@class="right-book-list"]/ul/li')
for l in list:
item=HongxiuItem()
name=l.xpath('.//div[@class="book-info"]/h3/a/text()').extract_first('')
author=l.xpath('.//div[@class="book-info"]/h4/a/text()').extract_first('')
des=l.xpath('.//div[@class="book-info"]/p[@class="intro"]/text()').extract_first('')
img='http:'+l.xpath('.//div[@class="book-img"]/a/img/@src').extract_first('')
item['name']=name
item['author']=author
item['des']=des
item['img']=img
yield item爬取书名,作者,简介,图片的代码如上所示,将他们传入管道中。
我们需要将这些数据存入到数据库中,就需要连接数据库,创建表,然后插入数据,这些都将在管道中完成
class HongxiuDB(object):
def open_spider(self, spider):
self.db =pymysql.connect(host="localhost", user='root', password='123456', db='table', port=3306)
self.cursor= self.db.cursor()
sql = "CREATE TABLE xsk(name text,author text,des text,img text)ENGINE=InnoDB DEFAULT CHARSET=utf8"
# 执行sql语句
self.cursor.execute(sql)
def process_item(self, item, spider):
self.cursor.execute('insert into xsk(name,author,des,img)VALUES ("{}","{}","{}","{}")'.format(item['name'],item['author'],item['des'],item['img']))
self.db.commit()
def close_spider(self, spider):
self.cursor.close()
self.db.close()只需要这三个方法即可完成,通过接收传来的item并处理即可完成存入数据库的功能,代码比较简单,需要注意的就是mysql是默认不支持插入中文的,这里需要在创表时额外加一句ENGINE=InnoDB DEFAULT CHARSET=utf8"就可以了
因为是为了测试存入数据库,所以我们就不存放太多了,到这里就结束了。