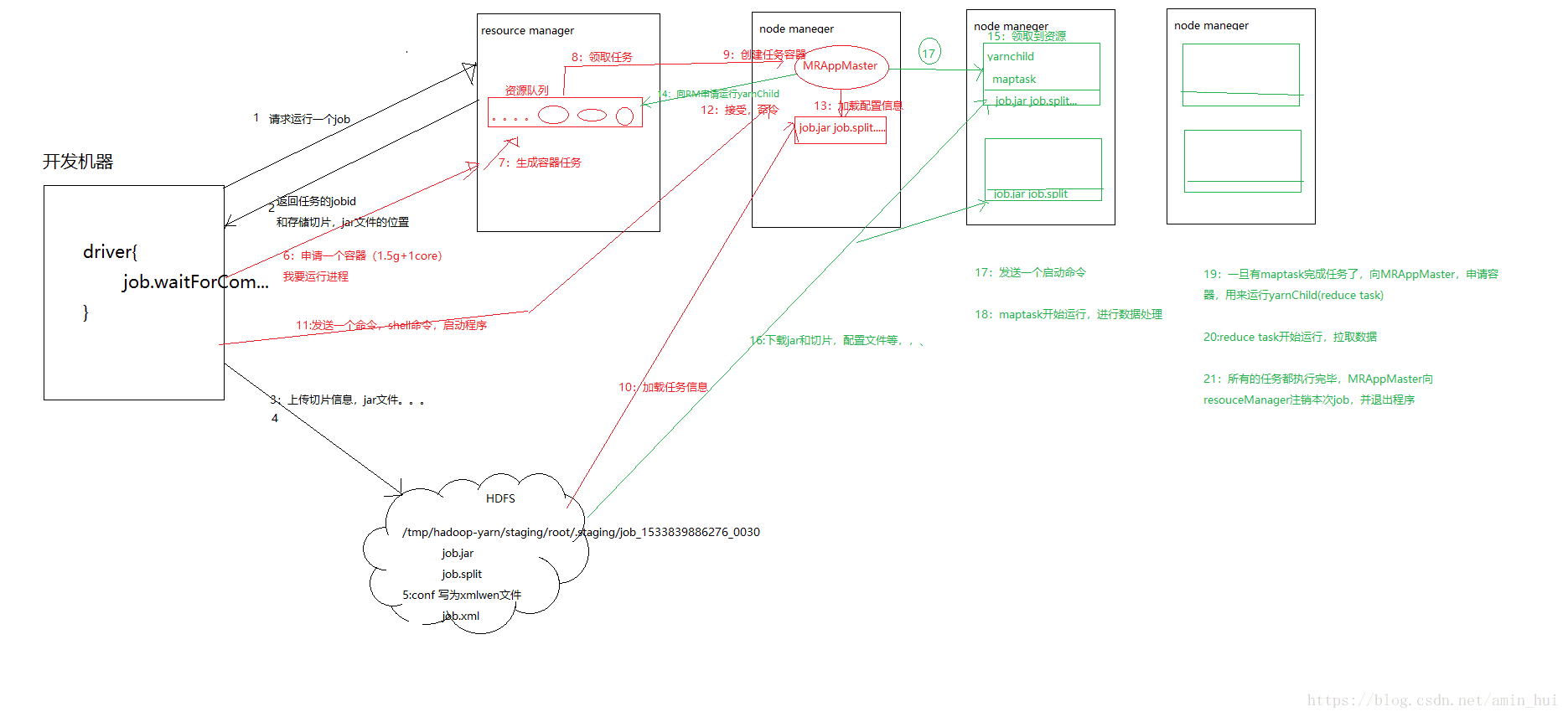
yarn工作原理描述
1.yarn主要包括三部分
1)ResourceManager:负责整个集群的资源管理和调度,
主要作用有:处理客户端请求、启动或监控ApplicationMaster、监控NodeManager、资源的分配与调度
2)ApplicationMaster:负责应用程序相关事务,
主要作用有:负责数据的切分、为应用程序申请资源并分配给内部的任务、任务的监控与容错
3)NodeManager : 管理YARN集群中的每个节点,
主要作用有:管理单个节点上的资源、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令
2.yarn的工作模式属于Master/slave模式,ResourceManager是yarn中的Master,NodeManager 是yarn中的slave,ApplicationMaster则相当于二者之间的媒介,ResourceManager下达命令给ApplicationMaster,ApplicationMaster将命令传输给NodeManager 执行。
yarn工作原理图
MapReduce工作流程
1.Driver开发机器将文件数据切片 ,每一个切片都要执行MapReduce流程
2.使用LineRecorderader每次读取切片的一行数据,从头到尾全部读完,将数据以(key,value)形式提交给Map处理
3.Map依次执行run(),依次执行setup()、循环每行数据执行map()方法,最后执行cleanup()方法;通过MapOutPutBuffer方法将数据序列化为byte数组,放入环形缓冲区,环形缓冲区大小可自行调节;
4.使用partitioner.getpatition方法标记分区;
5.当环形缓冲区的数据大于80%时,则会执行溢写操作,最后小于80%扥数据会直接写入本地,将数据存放本地磁盘,注意:在执行溢写操作前会先将数据快速排序;
6,将上述每一部分数据进行文件合并,进行归并排序,此时数据已经分区;
7.索引文件,记录每个分区;通过http服务的jetty服务器将不同切片上每个分区的数据放置在对应reduce上进行处理
8.使用merage()合并数据,并将数据归并排序,执行分组操作;
9.执行reduce,依次执行setup()、迭代reduce()方法逐行写入数据,,最后执行cleanup()方法;将数据输出到对应文件中。
