1、官网:storm.apache.org,twitter开源。
2、为什么使用Storm?
Stom是一个免费和开源分布式实时计算系统。 Storm可以实时可靠地处理无限流的数据,可使用任何编程语言。
Storm有许多应用,如网上实时分析,机器学习,连续计算,分布式RPC、ETL等等。 Storm运行速度很快:每个节点每秒钟可处理上百万个Tuple。 它是可伸缩的,容错的,保证你的数据将被处理,也很很容易设置和操作。
Stormke可以整合队列和数据库的技术。 Storm topology可以以任意复杂的方式消费Stream数据,但在数据计算的每个阶段需要重新划分Stream。
3、什么是实时计算?
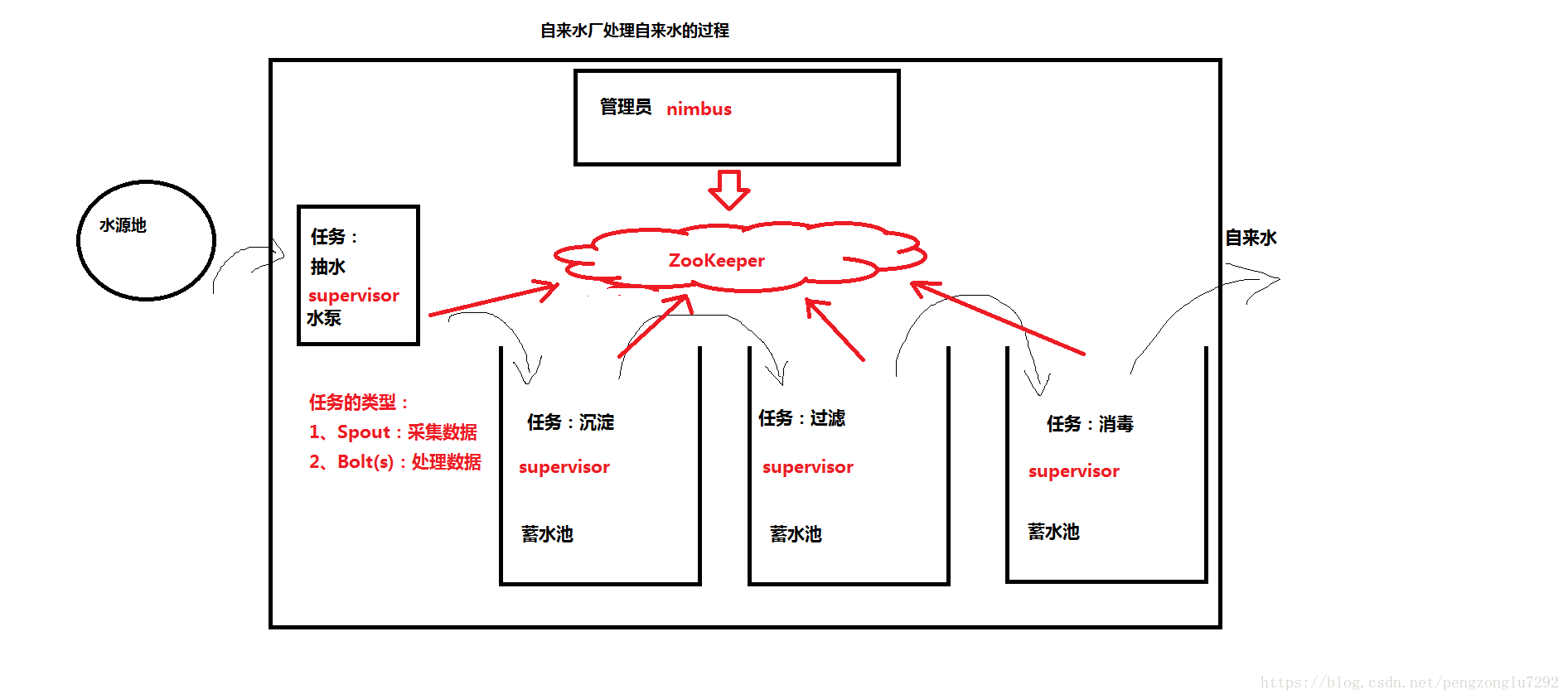
4、批计算VS实时计算。
批计算:批量获取数据,批量传输数据,周期性计算
例子:Sqoop从关系型数据库中抽取数导入到Hive或Hbase并最终保存在HDFS上,使用MapReduce或Hive进行处理。
实时计算:数据源源不断产生,使用流式处理系统计算。
例子:Flume实时数据采集或直接读取数据库日志,然后缓存Kafka中,并使用Storm计算,将最终结果保存在Hbase或Postgre数据库中。
5、MapReduce VS Storm

6、Storm的体系架构。

7、Storm的两种安装模式:
本地模式
集群模式
------------------------------------------------------------------------------------------------------------------------------
Storm的安装配置
一、安装部署Zookeeper
1、下载ZK并解压,由于需要三台ZK,我们可以在一台机器上配置好然后拷贝到其他节点上。
2、配置zk环境变量(三台都要)。

3、更改zk配置文件。

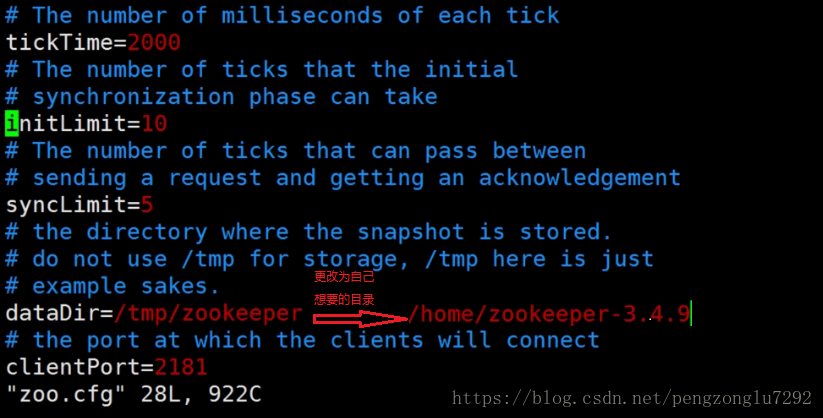


4、配置ZK唯一标识ID。

5、拷贝配置好的ZK到另外两台机器上。


6、在另外两台机子上更改标识ID。
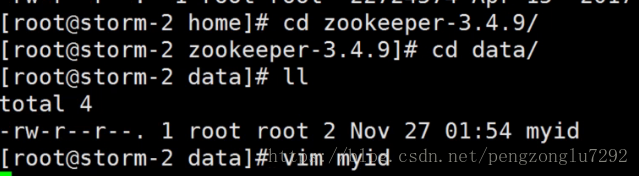
7、启动ZK,三台机器都要执行。

8、查看ZK节点状态。


9、验证ZK集群之间的数据自动同步特性。
A。在一台ZK上执行“zkCli.sh”打开客户端,执行"create /mydata hellowold"命令,在根目录下创建一个/mydata文件,文件内容为“helloworld”。
B。在另外两台ZK上任选一台执行“zkCli.sh”打开客户端,执行“ls /”发现根目录下也有一个/mydata文件,文件内容也为“helloworld”。
至此,ZK搭建完毕。
二、安装部署Storm
1、下载好Storm并解压。
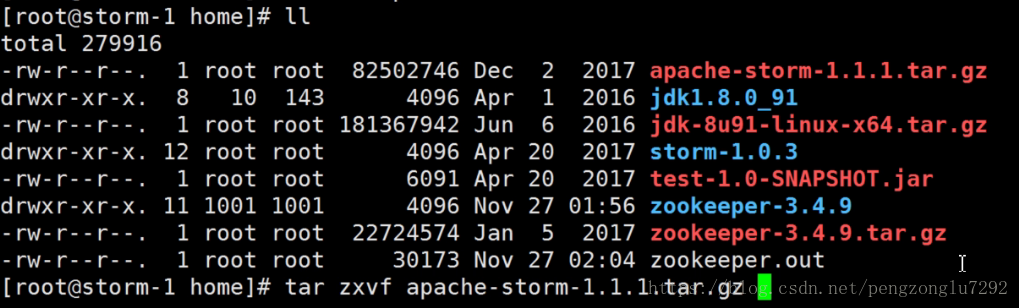
2、配置Storm环境变量。

3、更改配置文件。
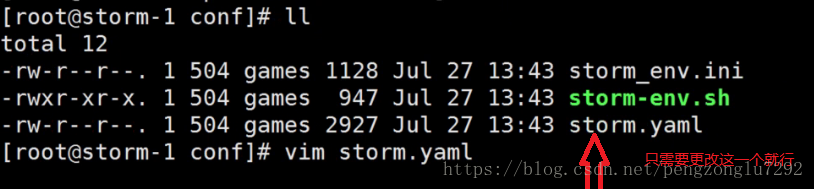
原图为:
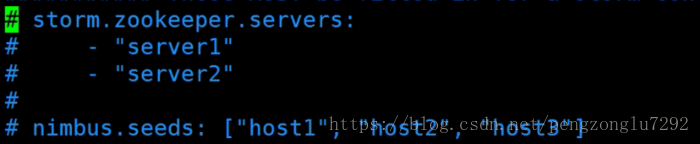
更改为:


4、拷贝配置好的Storm到其他Storm节点上。


5、更改第二台第三台Storm的环境变量文件。

6、启动Storm。
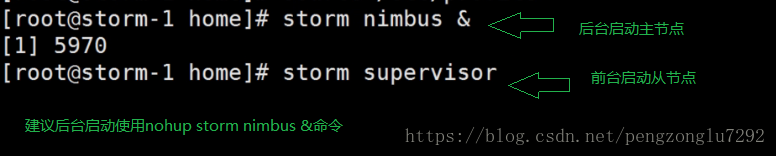

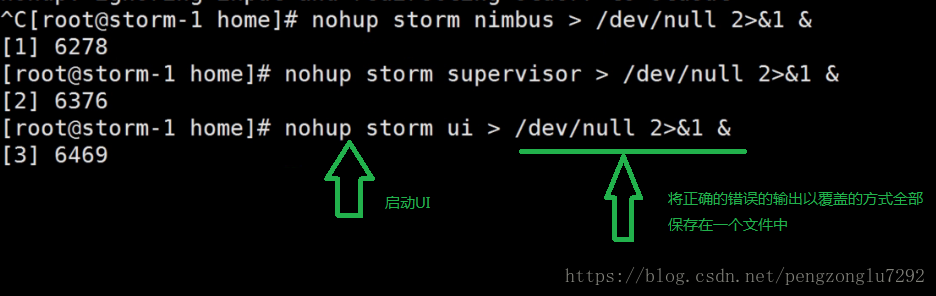
网页UI也要单独启动。