简介
本文是实施前的概述,后期会在具体实施过程中来不断总结,改善。
故障自愈涉及到IT系统的不同方向,本文以MySQL数据库为例来阐述故障自愈系统应该如何来实现,如有雷同,算我抄你。
框架
在解决问题时,最怕的就是看不清楚问题的本质。
我们先来看一个非自愈的问题解决过程,比如说线上出现一个问题,cpu飙升到了90%,监控系统发现了问题,然后会发送给dba,dba收到告警后,登陆到数据库查看,发现有几十个语句并发执行了几十秒,然后经过explain发现确实是慢语句,而不是硬件问题,随后dba开始执行kill操作,添加索引(或者通知RD回滚代码)等来解决。直到添加完索引(代码回滚完成)解决掉问题,cpu下降,发送ok告警,问题解决。
再来看故障自愈,这四个字几乎涵盖了系统的组成部分。如下所示
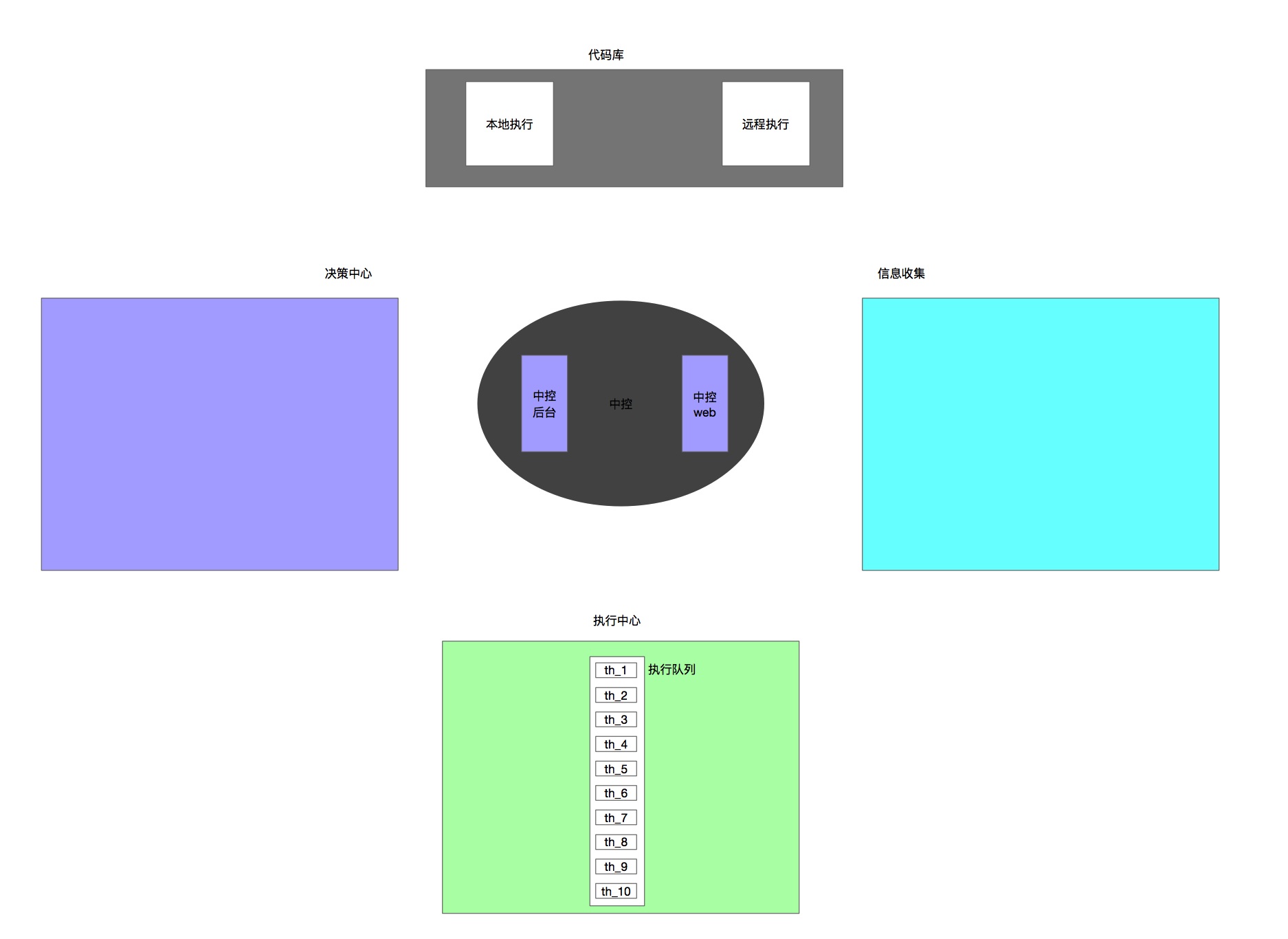
这张图比较简陋,但是基本涵盖了各个模块,这里没有把监控系统纳入进来,写了信息收集。监控告警系统有很多比较成熟的解决方案,它仍然很重要,并且是整个故障自愈系统的基石。
我们把监控系统拿进来,替换掉信息收集
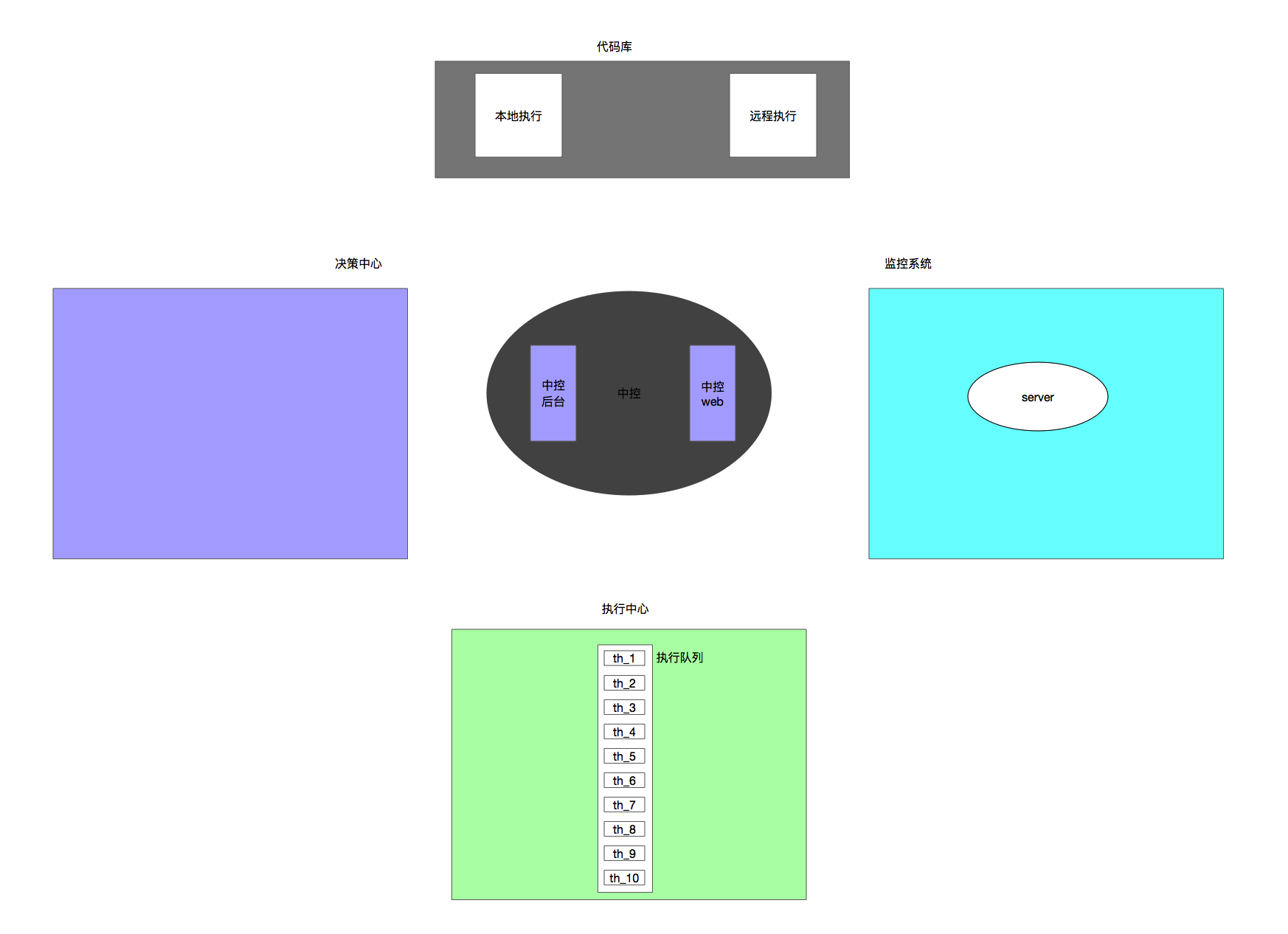
现在还以刚才提到的那个问题为例,来看下在故障自愈模式下,应该如何来解决。我想应该是分为如下几个步骤:
- 监控系统发现问题,cpu升高到90%,发送告警的同时,并且发送给了故障自愈系统的中控系统。
- 中控收到监控系统发送的告警信息,这条信息可能是如下数据格式,当然可能是jason,或者其他什么样子
- 中控注册自己的故障列表,并发送给决策中心。
- 决策中心根据中控给出的故障信息,根据既定的方案来获取问题的根因,然后生成解决方案并返回给中控。
- 中控把解决方案丢给执行中心,来解决问题,
- 最后是问题解决的验证,中控可以等待告警系统发送验证通知,当然也可以自发的去探测问题的恢复程度
- 所有已经解决,正在解决,预测等等的信息,通过web来展现。
为什么要作出这么多的模块呢,我想可能是考虑到多方协作来共同完成这个系统的开发,因为今天既作为一个产品的角色,也作为一个研发,实施,维护的角色,当然这种模式也并非一成不变,这在本文的开始就已经说过了。下面来看实现。
实现
我们想象中的工作模式,要落地,下面来看落地的过程中的各个细节。依然采取上面的思路来看,先来解决第一个问题
监控系统与自愈系统之间的通信
我们所有的一切建立在监控系统可以及时发现问题,并且上报问题的基础上,如果这个条件不成立,可能这篇软文又要写一大堆如何来实现一套成熟稳定的监控系统上,这不太是我想要的。好了,来看通信这部分如何实现,分为通信方式和数据格式,或者叫做协议。
通信方式
类似于zabbix/openfalcon这样的监控系统,大多都支持告警回调,我们可以在回调中通过http或者tcp的方式来发送消息,当然更优雅的方式是,直接把告警消息写入到MQ中,由自愈系统来进行消费,但是这有可能加大故障处理的延迟时间,而每增加一个组件,都会增加更多不确定因素,所以初期不推荐使用,因为自愈系统完全可以提供http或者tcp的server端能力。
数据格式
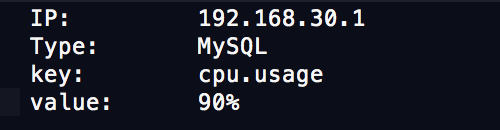
刚才看了一个消息体的示例:它可能包含了如下几个字段
- IP: 表示出问题的机器
- Type: 表示这台机器上部署的是什么应用
- key: 表示是哪个监控项被触发
- value:表示触发阈值
这些信息监控系统应该都是可以完整提供的,但是有如下几点有待商榷
不得不说的是,如果是一个环境复杂的机器,可能上面部署了数据库,应用等很多组件,Type这一列就没有太大的意义,而需不需要type字段,取决于,故障自愈系统能不能通过某种方式获得这台机器的cpu飙升是由谁来引起的,我们先假设故障自愈系统处于幼儿园的阶段,监控系统必须明确的告知,此机器上面部署的是MySQL数据库示例。那数据格式也暂且这样定义。
我们需不需要把告警归类?比如说数值类型,字符串类型,bool类型。因为这可能影响到自愈系统的中控如何去判断问题的根本,以及决策系统提供什么样的解决方案。当然,现在是幼儿园阶段,我们要对每一个告警子类型,确定一种唯一的根因查询方案,故障解决方案
现在定义好了通信方式,数据格式,下面来看中控
中控的处理逻辑
中控收到告警信息之后,要做如下几件事情

一个一个来,先看如何确定问题本质
根因分析
我实在想不出如何在没有大量结构化数据的前提下,通过AI来分析问题本质,这种方法在故障自愈系统的幼儿园阶段,还不太适合,只有在自愈系统稳定运行了一段时间之后,才能逐步的通过数据分析,来辅助预测问题的本质,所以,先抛开AI不谈,于是,最接地气的方式应该是如下这样:上文中的数据格式中,我们已经指定了机器类型,所以自愈中控知道这是一台运行mysqld的机器报出了cpu使用率90%的问题,而针对于这个问题,自愈系统中已经预先定义了一套根因分析的程式。针对于这个问题的根因分析,我想大概是这样的:
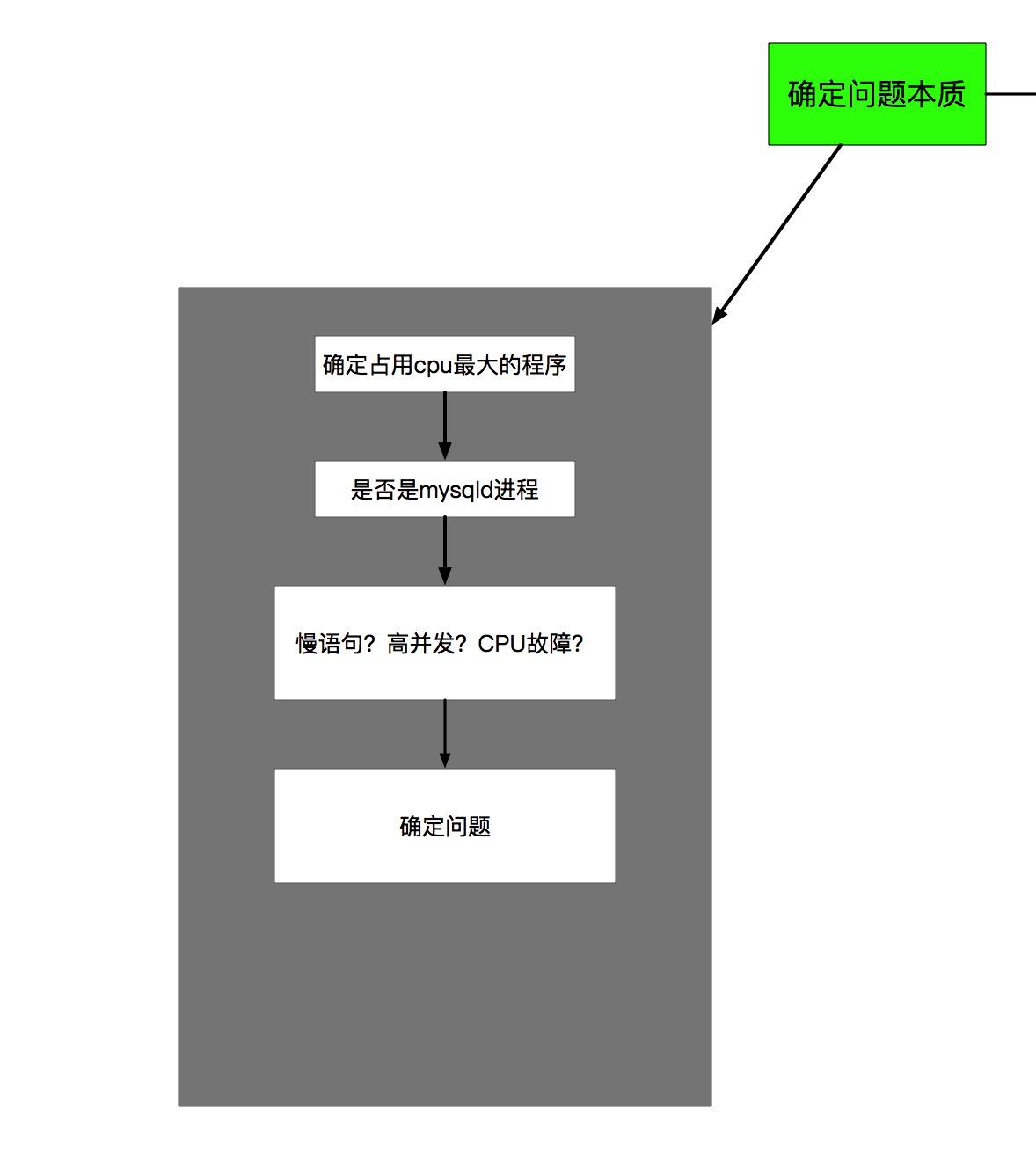
决策系统运行bash-1确定是cpu的问题,紧接着运行bash-1-1发现是慢语句引起的,生成一个已经定义号的问题类型,暂时叫做cpu-slow-query。根因分析结果信息为192.168.30.1:13307:mysqld:cpu-slow-query。问题类型是可以预先定义的,为了方便决策系统的功能扩展,我们把这信息固化到数据库中。我想关于根因类型,可以用以下三张表来表示。
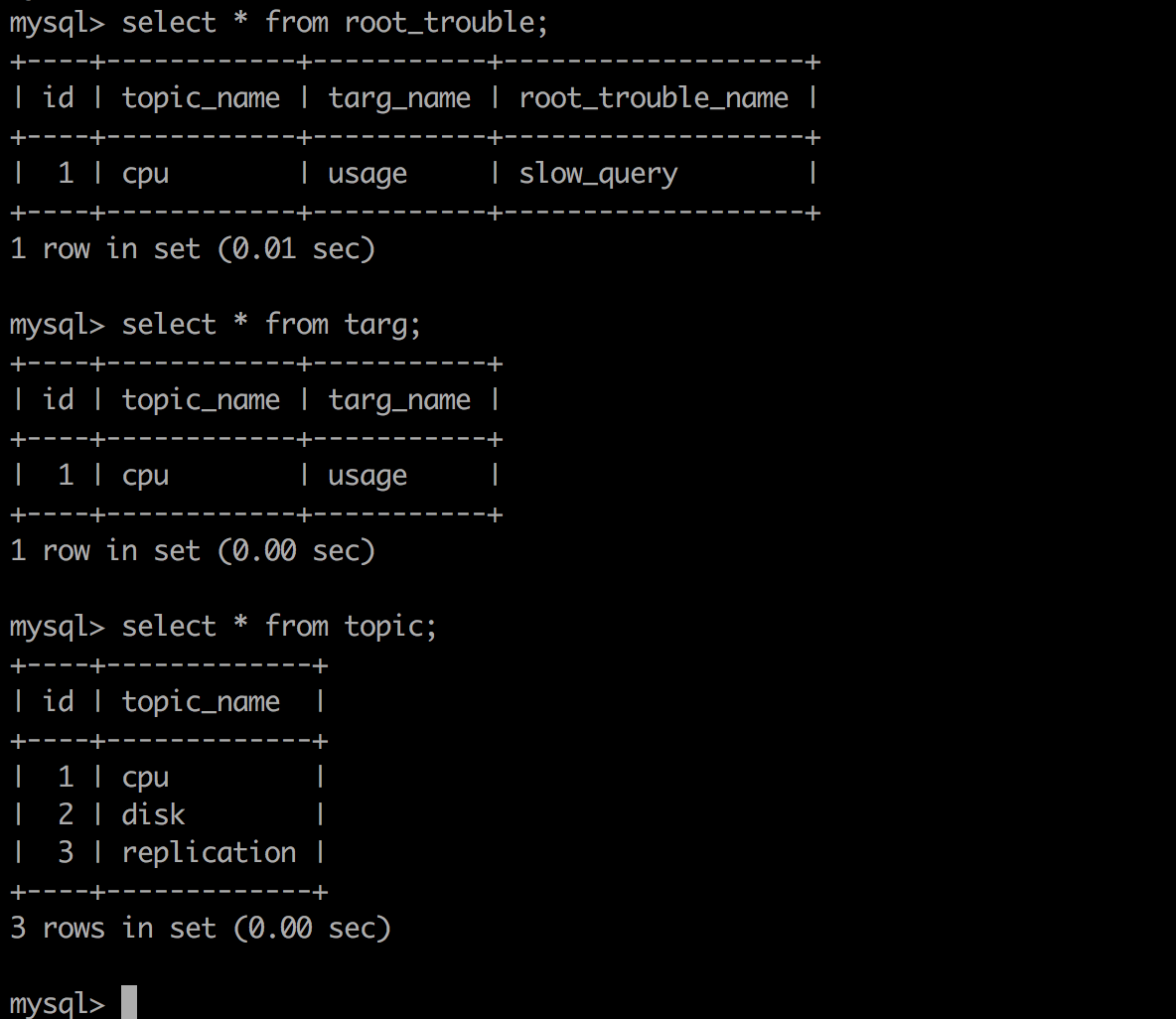
其中topic+targ的命名需要和告警提供者约定,或者直接沿用现有监控的模版,root_trouble则是自愈系统的研发参与者来确定,因为通过topic+targ来确定问题根因时,需要调用一个研发者自定义的程式,当然这不应该限制于程式的格式,比如说c程序,c++程序,python/shell/java等等。因为调用者和被调用者可能是不同部分,甚至不同公司的人去完成的,他们之间只需要协商好调用方式以及数据格式(协议)就好了,这样做的好处是,我们可以把开发权限放开到了解数据库系统的所有人。因此我们需要再加一张表,来表示这种调用关系,数据格式,如下:
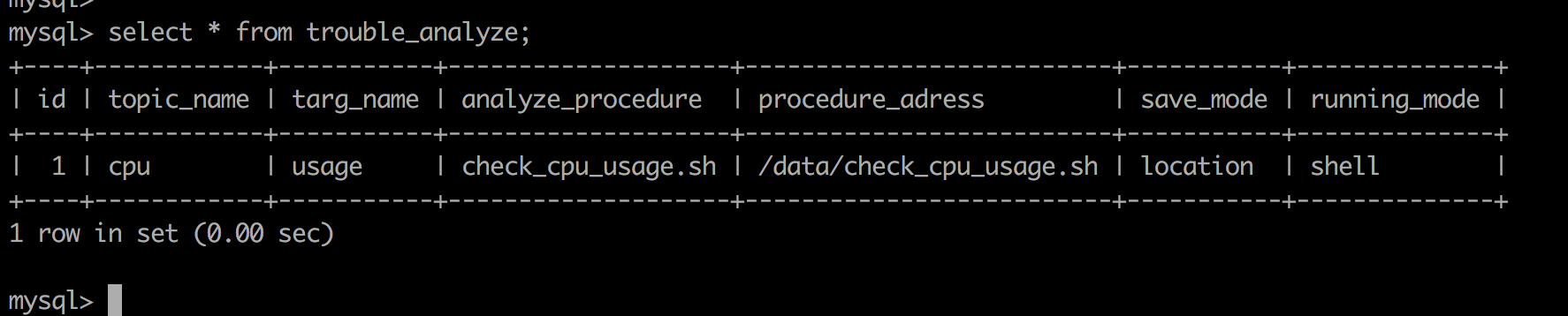
这里有很多值得再去思考的地方,比如说,一个类型为MySQL的机器,同时上面跑了一个别的数据抽取进程,so,是不是要通知一下自愈系统呢?让TK知道这台服务器上运行的是什么东西,这些暂时先不谈了。
我们来假设,决策系统确认了,这是一个由慢语句引起的cpu飙升问题。