【摘要】运维累都是有原因的,此时就可以轮到故障自愈出场了。
背景
最近晚上23:00甚至是凌晨总收到告警通知:磁盘可用量低于20%,这个时候不得不爬起来处理告警。当然这里要提醒大家:对于小问题,运维也绝不要抱着侥幸的心理,因为只有痛过才知道。
磁盘类告警只是我们诸多告警中的冰山一角,虽然我们有值班人员甚至是运维团队支撑,但是也不能因为这种小问题就分散注意力,这时我们就需要考虑如何通过自动化实现。
针对这种情况,我们通常会想到以下几点:
▪ 在告警机器上设置定时任务;
▪ 编写脚本压缩日志或清理磁盘空间。
这种方案虽然可行,但是试想下:如果我们管理的是上千台机器且目录结构混乱,那么我们面临的将是上千个脚本及定时任务,这个工作量是非常大的。
运维累都是有原因的,此时就可以轮到故障自愈出场了。
故障自愈
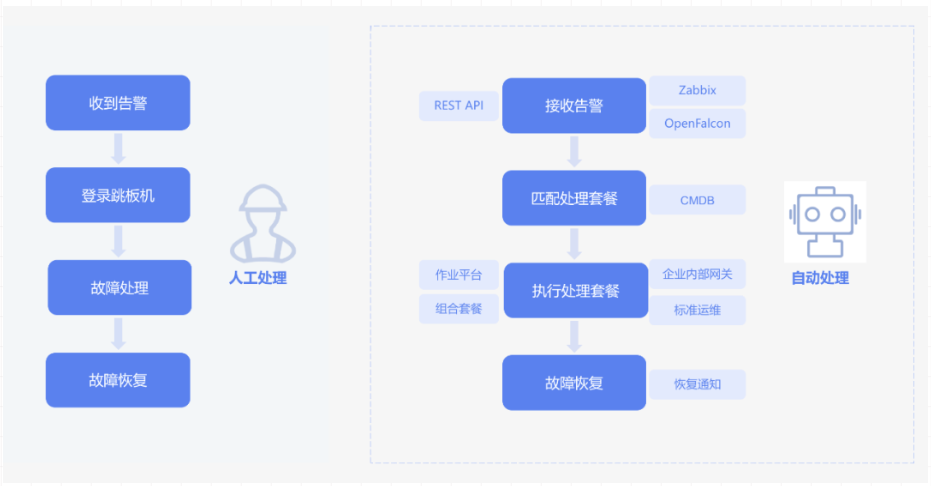
如图所示,对于生产故障,运维标准的处理流程是收到告警、登录跳板机、故障处理、故障恢复,整个过程都是通过人工手动处理。而故障自愈则是接受监控平台的告警定位,匹配预设的故障处理流程,进而通过自动化手段实现故障的自动恢复。
在认识故障自愈后,我们需要考虑的就是如何让运维管理的生产环境更广泛的接入故障自愈,而不是只针对单一的机器或某一类故障。因此在正式接入故障自愈前,我们还有很多的工作要