作者:Hello,Panda
3 ZYNQ 互联结构
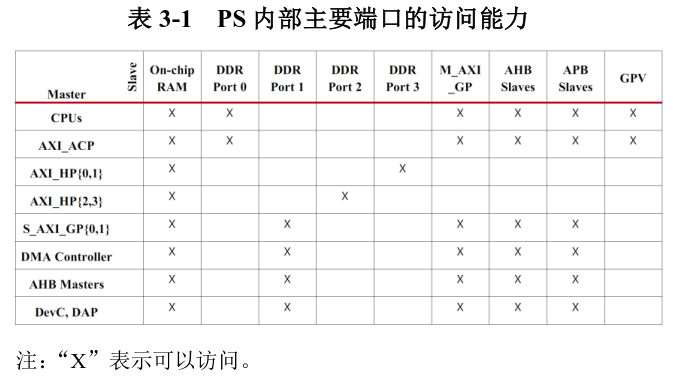
确理解并应用 ZYNQ SoC 的 PL 和 PS 间的互联结构有助于设计最优的软件架构,充分利用Zynq 的资源和性能。在1.3 节已经提到,PL 和 PS间主要通过AXI_HP、AXI_GP、AXI_ACP 总线接口以及一些 EMIO、中断及事件接口紧密结合在一起。可以说 PL设计关键就是用好这些接口。 ZYNQ 的主互联结构如图 3-1 所示,图中清楚表示了设备可以访问的源、目的,可同时支持并发读写的路数,以及 Qos控制的情况。以下就 PS 与PL交互最为密切频繁的 AXI_HP(AXI3.0)、AXI_GP(AXI-Lite)和 AXI_ACP 接口进行详细介绍。 需要注意的是,端口在 PS 内部的连接并不是完全交叉结构,表 3-1 列出了主要端口的访问能力。
互联总线一般采用 AXI4.0 协议标准,有关总线协议的文档参见 ARM《ihi0022d-AMBA®AXI and ACE™ Protocol Specification》。
3.1 AXI_HP 接口
AXI 接口是为了 PL 访问 PS 端的存储器而专门设计的高速通道,它具有以下性能: ①PL 可访问 PS 上的四个 AXI_HP Slave 通道,每通道支持独立可编程的32/64bit 数据宽度;
②在 32bit 接口模式下高效动态扩展到 64bit 对齐传输;
③可以跨 PS 和 PL 间异步时钟传输;
④采用标准的 AXI3.0 协议,突发长度可达 16;
⑤AXI_HP 分成两部分,一部分和 PL 直接相连,另一部分连接到 AXI Interconnect,从而分别访问 DDR 和 OCM。
AXI_HP 接口一般用于逻辑与挂载在 APU 的 DDR 间高速数据交互,数据搬移一般通过 PL内的DMA 完成。例如在设计视频处理时,高清图像可由 FPGA直接完成采集、预处理,然后通过 AXI_HP接口将数据传输到 DDR中供完成APU 进一步处理。
3.2 AXI_GP 接口
AXI_GP 接口是符合 AXI4-Lite 协议的低速接口,没什么突出特点,PS 提供两个主接口,两个从接口。这个接口位宽为 32bit,不支持突发传输,一般用于在PL-PS间传输低速的控制信息和少量数据,也可通过ARM内的中央仲裁器访问DDR。当设备很多时,可通过 PL的 AXI Interconnect进行扩展。3.3 AXI_ACP 接口
加速器一致性端口(ACP)是 SCU 上的一个64 位的 AXI 从接口,提供了来自PL 到 Cortex-A9 MP 核处理器子系统的异步的缓存一致性访问点。通过这个接口PL 端逻辑可以直接访问 PS 部分的 Cache,硬件一致性由 SCU 保证。因此 PL 可以直接从Cache 拿到CPU 计算的结果,同时也可以第一时间将逻辑加速运算的记过送至CPU Cache 中,因此延时最低,适合做专用指令加速器模块接口。 基于 PL 实现的加速器的过程大概如以下所列: ① 在它的本地缓存空间内,CPU 为加速器准备输入数据。
②CPU 使用到 PL 的通用 AXI 主接口,将消息发送到加速器。
③加速器通过 ACP 取数据,处理数据,然后通过 ACP 返回结果。
④ 通过写到一个已知的位置,加速器设置一个标志,用来表示正在处理的 数 据完成。可以通过处理器轮询这个标志的状态或者产生一个中断。
这种低延时的总线非常适用于PS端自定义指令通过PL加速。
3.4 视频处理的互联结构
对视频处理而言,图像算法模块会对 DDR 写入或请求数据,PS 需要配置相关参数,同时,PS 内的算法可能会需要 PL帮助进行加速以提高执行效率,相关执行状态通过中断通知 PS满足快速响应要求。因此,一个典型的应用可能会如图3-2 所示的结构。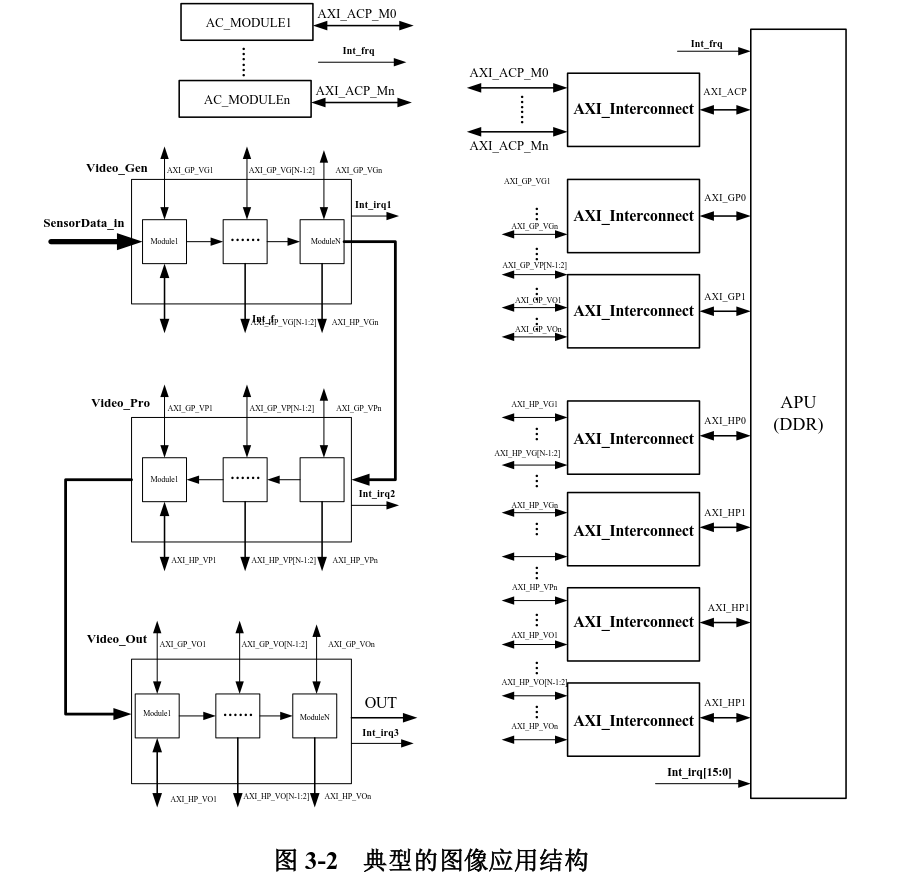
从应用可知,图像处理最关注也最关键的是 AXI_HP所能提供的带宽,这将直接制约整个系统的功能密度和性能。下表 3-2 列出了 PS-PL常用互联接口的性能。 因 AXI 总线读写通道相互独立,因此读写互不影响,所以最终图像处理多并发访问的最终瓶颈任然是 DDR带宽。但是需要注意的是 AXI_HP0/AXI_HP1和 AXI_HP2/AXI_HP3 在连接DDR控制器之前是独立仲裁的,如果许可,最好是在这两个独立端口里分别只使用其中的一个端口,例如端口 0 和端口2。如果使用了同一个仲裁器的两个端口,势必会影响效率。
3.5 各接口对比
通过对各接口的比较,将他们的特点和可能的用途整理到表 3-3 中。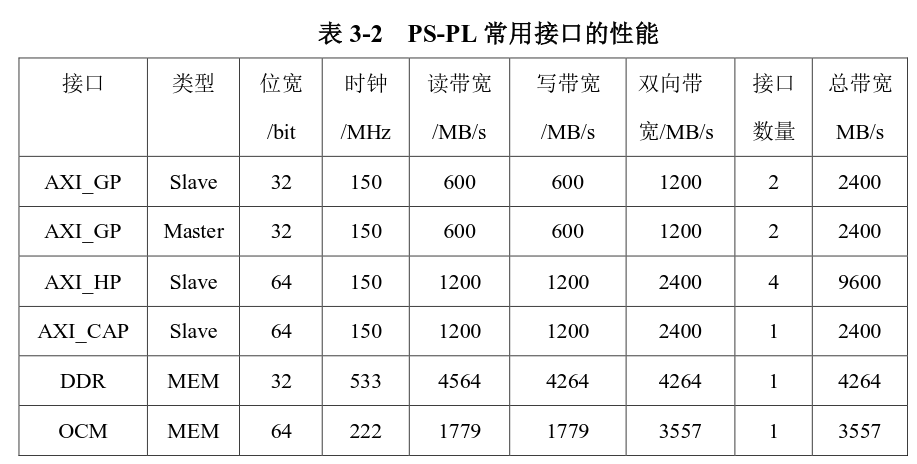
4 开发工具链
在 Xilinx未进行工具整合之前,PL开发需要使用 Xilinx ISE 、PlanAhead和 XPS组合才能完成。针对下一代应用,Xilinx将 PL 开发所有功能整合到VIVADO IDE 中,最新版本为 Vivado2014.4,建议使用最新版本开发环境。PS裸机开发直接使用 Xilinx SDK 即可,操作系统开发可在相应的系统环境中调用SDK 提供的交叉编译工具链,当然也可以在SDK中创建linux工程,只不过在使用上有诸多限制。4.1 工程创建流程(PL)
Xilinx 在 Vivado 中推荐使用图形化的顶层设计方式,用户可以先将 Xilinx提供的IP 核或自定义IP 制作成一个大的 block design (bd),block design也可封装成为一个新的IP。最终的顶层文件是一个以 Zynq PS 为核心的design block。因此一个工程的创建可以分成以下步骤:(1) 在 Vivado中创建一个新工程;
(2) 创建一个新的 block design;
(3) 添加Zynq7 Processing System 到block design,并对其进行初始化配置;
(4) 添加其他IP核到block design,并完成和PS 的互联以及对外接口的连接;
(5) 分配 PS 内地址空间映射;
(6) 进行规则检查;
(7) 生成HDL Wapper(顶层文件)并加入约束;
(8) 编译、综合、实现;
(9) 生成 Stream Bit文件;
(10)导出硬件配置文件到 SDK;
(11)在SDK 中使用这些配置文件生成 FSBL或BSP支持裸机 APP;
4.2 硬软件调试工具
Xilinx 在 Vivado 中提供了三个调试工具调试 PL,目前相比来说不如成熟的ChiScope 方便。这三个的描述 IP 见表 4-1。
Xilinx 在 SDK 中提供实时跟踪的工具 XMD,可实时查看 ARM 的通用寄存器值,中断信息,PC等。同时也可实时查看存储空间的值。同时 SDK还提供远程调试功能(GDBServer 工具链)。
另外需要提到的是,Xilinx提供了一套完整的性能监测工具,可以对设计进行准确的性能评估(包括CPU性能、Cache性能、AXI总线吞吐、DDR带宽等),详细内容参见xilinx官方文档(UG1145):
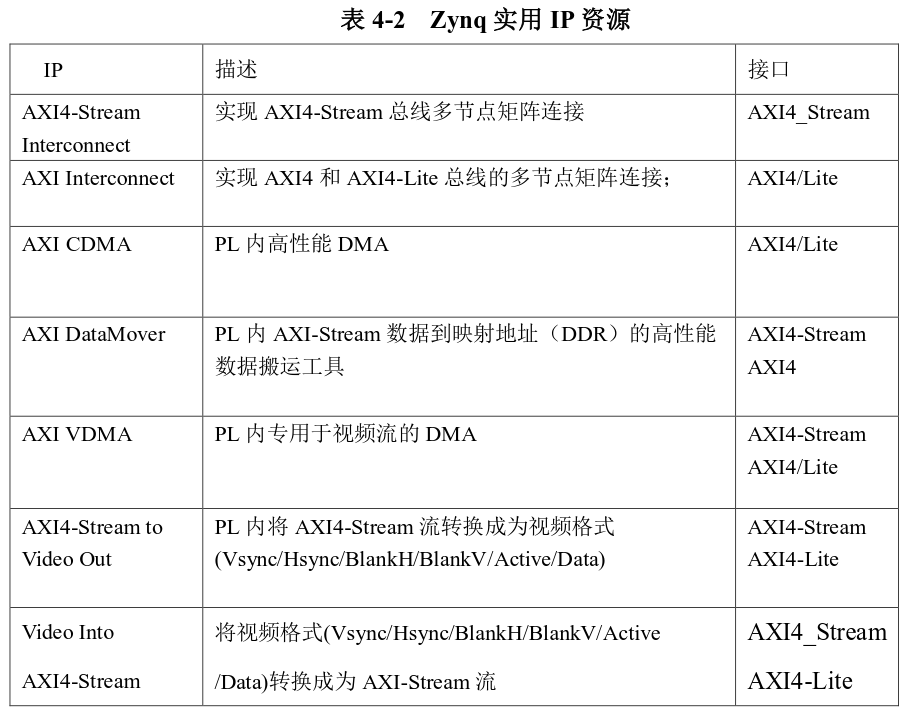
4.3 实用 IP 核
为了更方便灵活的进行基于 Zynq Soc 的设计,Xilinx提供了一系列的 IP核供选用,表4-2 列出了实用IP资源。