一、设计要求
1.从文件读入26个英文字母及其权值,建立哈夫曼树并将它存于文件中.将哈夫曼树以直观的方式显示在图形化界面上;
2.利用已经建好的哈夫曼树,对文件中的正文进行编码,然后将结果存入文件中,并求出最短平均编码,哈弗曼最短平均编码,冗余度以及程序运行时间。
二、数据结构
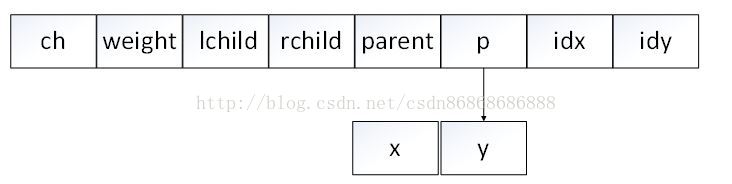
ch: 字符
weight:权重
lchild: 左孩子
rchild: 右孩子
parent: 双亲
p: 绘图坐标
idx,idy:绘图标志
三、代码
/*
描述:实现哈夫曼树的图形化以及根据哈夫曼树对数据进行编码
*/
#include<stdio.h>
#include<math.h>
#include<graphics.h> //图形化界面用到
#include<conio.h>
#include<stdlib.h>
#include<time.h>
#define n 26 //叶子数目
#define maxval 10000.0
#define maxsize 20 //哈夫曼编码的最大位数
typedef struct //坐标数据结构
{double x;
double y;
}Point;
typedef struct //节点数据结构
{
char ch;
float weight;
int lchild,rchild,parent;
double idx,idy;
Point p;
}huffmantree;
typedef struct
{
char bits[n]; //位串
int start; //编码在位串中的起始位置
char ch; //字符
}codetype;
void huffman(huffmantree tree[]);//建立哈夫曼树
void huffmancode(codetype code[],huffmantree tree[]);//根据哈夫曼树求出哈夫曼编码
void HuffmanDrawing(huffmantree tree[],codetype code[]);//绘制哈夫曼树
void main()
{
clock_t start;//程序开始运行时间
clock_t end;//程序结束运行时间
int t;
FILE *fp;
start=clock();//取得程序开始运行时的系统时间
printf("总共有%d个字符\n",n);
huffmantree tree[2*n-1];
codetype code[n];
huffman(tree);//建立哈夫曼树
huffmancode(code,tree);//根据哈夫曼树求出哈夫曼编码
printf("哈夫曼树已绘制,请按任意键查看!");
getchar();
HuffmanDrawing(tree,code);//绘制哈夫曼树
end=clock();//取得程序结束运行时的系统时间
t=(end-start)/CLOCKS_PER_SEC;//计算程序运行总时间
if((fp=fopen("output.txt","ab"))==NULL) //向文本文档追加数据
{printf("can not open the file\n");
exit(0);
}
fprintf(fp,"程序运行总时间:%d秒\n",t);
fclose(fp);
printf("程序运行时间已写入文本!\n",t);
}
void huffman(huffmantree tree[])//建立哈夫曼树
{
int i,j,p1,p2;//p1,p2分别记住每次合并时权值最小和次小的两个根结点的下标
float small1,small2,f,sum=0;
char c;
FILE *fp;
for(i=0;i<2*n-1;i++) //初始化
{
tree[i].parent=-1;
tree[i].lchild=-1;
tree[i].rchild=-1;
tree[i].weight=0.0;
}
if((fp=fopen("input.txt","r"))==NULL)//从文件读取字符、权值
{printf("can not open the file\n");
exit(0);
}
for(i=0;i<n;i++) //读入前n个结点的字符及权值
{
fscanf(fp,"%c %f\n",&c,&f);
tree[i].ch=c;
tree[i].weight=f;
sum=sum+tree[i].weight;//权值累计
}
fclose(fp);
if((int)sum==1)printf("文本数据正确,已从中读出!\n");
else printf("数据有误!概率和不为1!\n");
for(i=n;i<2*n-1;i++) //进行n-1次合并,产生n-1个新结点
{
p1=0;p2=0;
small1=maxval;small2=maxval; //maxval是float类型的最大值
for(j=0;j<i;j++) //选出两个权值最小的根结点
if(tree[j].parent==-1)
if(tree[j].weight<small1)
{
small2=small1; //改变最小权、次小权及对应的位置
small1=tree[j].weight;
p2=p1;
p1=j;
}
else
if(tree[j].weight<small2)
{
small2=tree[j].weight; //改变次小权及位置
p2=j;
}
tree[p1].parent=i;
tree[p2].parent=i;
tree[i].lchild=p1; //最小权根结点是新结点的左孩子
tree[i].rchild=p2; //次小权根结点是新结点的右孩子
tree[i].weight=tree[p1].weight+tree[p2].weight;
}
}
void huffmancode(codetype code[],huffmantree tree[])//根据哈夫曼树求出哈夫曼编码
{
int i,c,p;
codetype cd; //缓冲变量
float sum=0,summ=0,x;//冗余度
FILE *fp;
for(i=0;i<n;i++)
{
cd.start=n;
cd.ch=tree[i].ch;
c=i; //从叶结点出发向上回溯
p=tree[i].parent; //tree[p]是tree[i]的双亲
while(p!=-1)
{
cd.start--;
if(tree[p].lchild==c)
cd.bits[cd.start]='0'; //tree[i]是左子树,生成代码'0'
else
cd.bits[cd.start]='1'; //tree[i]是右子树,生成代码'1'
c=p;
p=tree[p].parent;
}
code[i]=cd; //第i+1个字符的编码存入code[i]
sum=sum+(n-cd.start)*tree[i].weight; //计算平均码长
summ=summ+tree[i].weight*log10(tree[i].weight)/log10(2);//计算最短平均码长
}
x=(sum+summ)/sum;//计算冗余度
if((fp=fopen("output.txt","w"))==NULL) //输出哈夫曼编码到文件
{printf("can not open the file\n");
exit(0);
}
fprintf(fp,"每个字符的哈夫曼编码:\n");
for(i=0;i<n;i++)
{
fprintf(fp,"%c: ",code[i].ch);
for(int j=code[i].start;j<n;j++)
fprintf(fp,"%c ",code[i].bits[j]);
fprintf(fp,"\n");
}
fprintf(fp,"最短平均码长:%f\n",0-summ);//输出平均码长、最短码长以及冗余度到文件
fprintf(fp,"哈夫曼编码平均码长:%f\n",sum);
fprintf(fp,"冗余度为:%f\n",x);
fclose(fp);
printf("编码完成!\n编码,平均码长,冗余度已写入文本!\n");
}
void HuffmanDrawing(huffmantree tree[],codetype code[])//绘制哈夫曼树
{
char a[n][20],c[n][20];
tree[2*n-2].idx=1;
tree[2*n-2].idy=1;
for(int i=2*n-2;i>=n;i--)//将哈夫曼树与完全二叉树对应起来
{
tree[tree[i].lchild].idx=2*tree[i].idx;
tree[tree[i].rchild].idx=2*tree[i].idx+1;
tree[tree[i].lchild].idy=2*tree[i].idy;
tree[tree[i].rchild].idy=2*tree[i].idy+1;
}
for(i=2*n-2;i>=0;i--)//为idx域赋值
tree[i].idx=tree[i].idx/
pow(2,(int)(log10(tree[i].idx)/log10(2)));
for( i=0;i<=n-1;i++)//求出每个i叶子节点的idx排序
{
for(int j=0,k=1;j<n;j++)
{
if(tree[j].idx<tree[i].idx)k++;
}
tree[i].p.x=300+k*30;//根据叶子节点的idx排序求出叶子节点的x坐标
}
for(i=n;i<2*n-1;i++)//根据叶子节点求出双亲的x坐标
{
tree[i].p.x=(tree[tree[i].lchild].p.x+
tree[tree[i].rchild].p.x)/2;
}
for( i=0;i<2*n-1;i++)
tree[i].p.y=40*int(log10(tree[i].idy)/log10(2));//根据节点的层数求出节点的y坐标
for(i=0;i<n;i++){ //对文本编码的图形化转换
for(int j=code[i].start,k=0;j<n;j++,k++)
{c[i][k]=code[i].bits[j];
}
c[i][k]='\0';
}
for(i=0;i<n;i++){ //对文本权值的图形化转换
sprintf(a[i], "%g", tree[i].weight);
}
initgraph(1000,600);//初始化绘图屏幕
setcolor(WHITE);
setbkcolor(WHITE);
setfillstyle(WHITE);
cleardevice();
setcolor(BLACK);
outtextxy(10,0,"字母 概率 编码");
for(i=0;i<n;i++) //输出每个字符及其对应的概率、编码
{
outtextxy(20,20*(i+1),tree[i].ch);
outtextxy(50,20*(i+1),a[i]);
outtextxy(110,20*(i+1),c[i]);
}
for(i=0;i<2*n-1;i++) //绘制节点,以小圆代替
{circle((int)tree[i].p.x-100,100+(int)tree[i].p.y,2);
if(tree[i].lchild==-1)
outtextxy((int)tree[i].p.x-100,105+(int)tree[i].p.y,tree[i].ch);
if(tree[i].lchild!=-1) //绘制节点的左右子树
{
outtextxy((int)(tree[i].p.x+tree[tree[i].lchild].p.x)/2-100,//左子树标0
(int)(tree[i].p.y+tree[tree[i].lchild].p.y)/2+100,"0");
outtextxy((int)(tree[i].p.x+tree[tree[i].rchild].p.x)/2-100,//右子树标1
(int)(tree[i].p.y+tree[tree[i].rchild].p.y)/2+100,"1");
line((int)tree[i].p.x-100,(int)tree[i].p.y+100,//绘制节点与左子树的连线
(int)tree[tree[i].lchild].p.x-100,
(int)tree[tree[i].lchild].p.y+100);
line((int)tree[i].p.x-100,(int)tree[i].p.y+100,//绘制节点与右子树的连线
(int)tree[tree[i].rchild].p.x-100,
(int)tree[tree[i].rchild].p.y+100);
}
}
outtextxy(200,50,"按回车返回");
getch();
closegraph(); //关闭绘图屏幕
}
四、输入输出
输入:
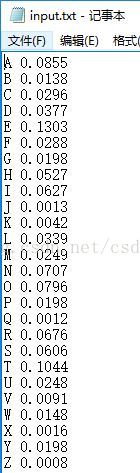
输出:



参考:
[1] 严蔚敏,吴伟民.数据结构(C语言版)[M].北京:清华大学出版社,1997.
[2] 孙学琛,李新洁.哈夫曼树的图形化算法设计[J].山东理工大学学报,2008.
注意:
需要安装Easyx图形库,完整工程http://download.csdn.net/detail/csdn86868686888/9736773