哈夫曼编码虽然在acm上用到的似乎很少,但其经常作为一种基础算法出现在计算机类的书籍上。
而我对哈夫曼编码的理解也仅仅局限在其用于编码领域,可以提高数据传输效率,或者是用于压缩文件?这些可能并不准确,我没有细细的去查证。
哈夫曼编码可以通过构建哈夫曼树来得到。
举例
我们用一个简单的例子,来简单描述下哈夫曼编码是什么?有什么好处?
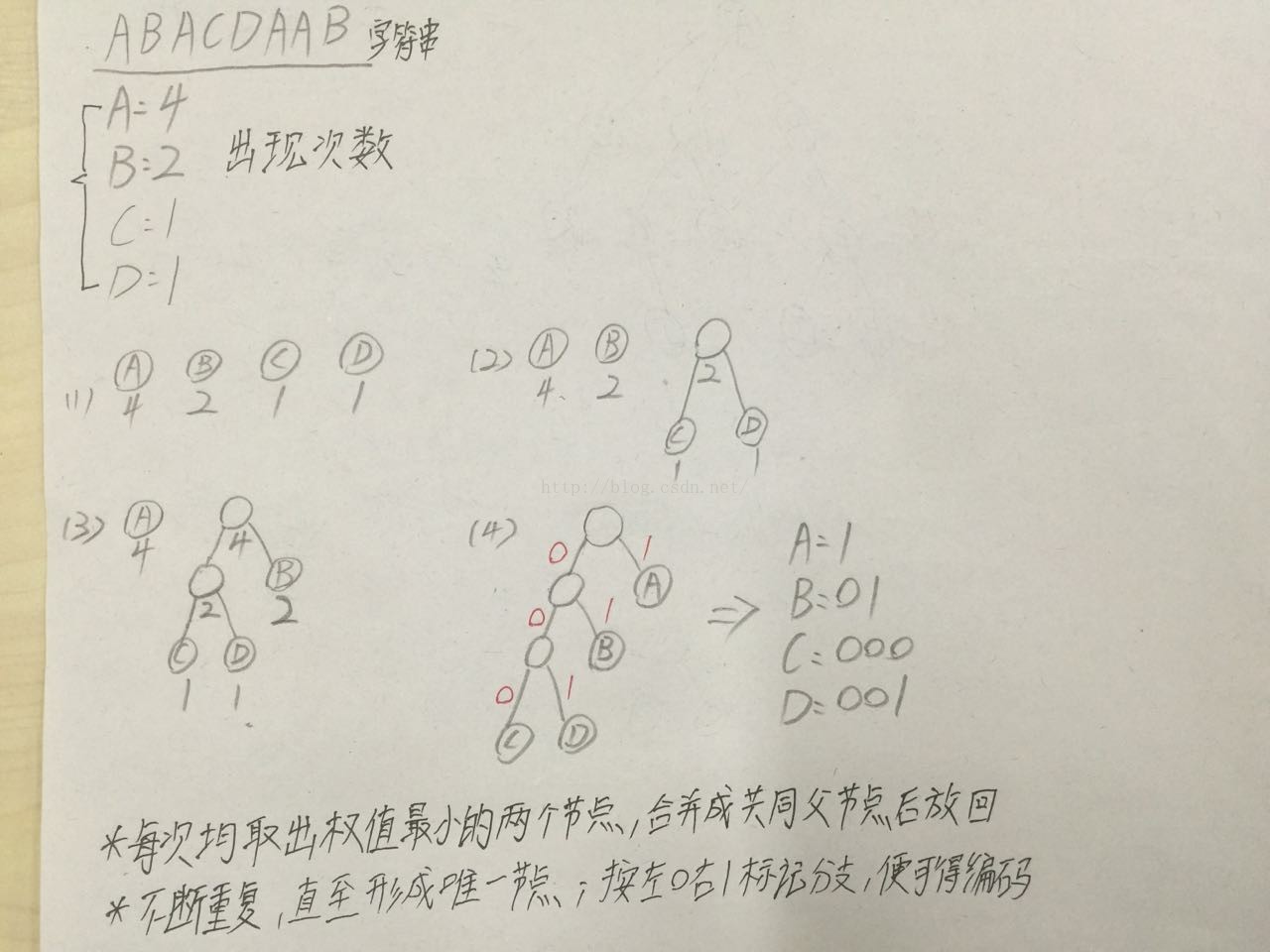
场景:X地区需要向Y地区发送一些文本,两地之间通过电缆(或者通过电报)连接,要求用最少的二进制流传递信息:ABACDAAB
可以看到该信息中一共出现4个A,2个B,C、D各1个
1. 如果用常见的二进制形式编码,那么A:00,B:01,C:10,D:11;信息转二进制流为:0001001011000001,一共是16位。
2. 如果用哈夫曼编码,则其的一种为A:1,B:01,C:000,D:001;信息转二进制流为:10110000011101,一共是14位,比普通的少2位。
这时,我们可能就明白了哈夫曼编码不就是频率出现越高,其编码越短吗?
我们尝试这样来赋值,A:0,B:1,C:01,D:10;二进制流为:0100110001,这个只有10位,比哈夫曼还少呢!
上面的说法似乎有道理,但是我们忽略了哈夫曼的用途可能是信息传输和压缩。当我们把编码规则和二进制流告诉接收方时,他们需要把这些二进制流还原为看得懂的信息。普通编码和哈夫曼编码都可以顺利还原,而第三种则不可能还原,0100....到底是ABAA....还是CAA....呢?
所以哈夫曼编码必须是前缀码,而且还是最优前缀码(前缀码定义:在一个字符集中,任何一个字符的编码都不是另一个字符编码的前缀)
因此,必须达到以上两点构造出的编码才是哈夫曼码。
求解
下面我们还是通过这个例子,简单来看看当获得ABACDAAB时,如何通过构建哈夫曼树求每个字符的哈夫曼编码:
步骤一:获得每个字符出现的次数作为该字符节点的权值;
步骤二:每次选取权值最小的两个节点,合并成有共同的父节点后放回;不断重复,直至只剩下一个节点;此时按照左分支为0,右分支为1进行编码;
具体的过程详见下图:
代码的实现
步骤一可以通过哈希遍历来获得每个字母的出现次数;
步骤二可用二叉链表模拟建树来实现;
步骤二中每次从集合中弹出两权值最小的节点合并为同一父节点后还要放回,显然需要在普通队列上加段每次插入后都排序的代码;如果自己造轮子想必还要费点时间,好在C++标准库提供了“优先队列”可以满足我们的需求。(在优先队列中,元素被赋予优先级;当访问元素时,具有最高优先级的元素最先出队列)
下面我们来看下具体的代码:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<queue>
using namespace std;
typedef struct node{
char ch; //存储该节点表示的字符,只有叶子节点用的到
int val; //记录该节点的权值
struct node *self,*left,*right; //三个指针,分别用于记录自己的地址,左孩子的地址和右孩子的地址
friend bool operator <(const node &a,const node &b) //运算符重载,定义优先队列的比较结构
{
return a.val>b.val; //这里是权值小的优先出队列
}
}node;
priority_queue<node> p; //定义优先队列
char res[30]; //用于记录哈夫曼编码
void dfs(node *root,int level) //打印字符和对应的哈夫曼编码
{
if(root->left==root->right) //叶子节点的左孩子地址一定等于右孩子地址,且一定都为NULL;叶子节点记录有字符
{
if(level==0) //“AAAAA”这种只有一字符的情况
{
res[0]='0';
level++;
}
res[level]='\0'; //字符数组以'\0'结束
printf("%c=>%s\n",root->ch,res);
}
else
{
res[level]='0'; //左分支为0
dfs(root->left,level+1);
res[level]='1'; //右分支为1
dfs(root->right,level+1);
}
}
void huffman(int *hash) //构建哈夫曼树
{
node *root,fir,sec;
for(int i=0;i<26;i++) //程序只能处理全为大写英文字符的信息串,故哈希也只有26个
{
if(!hash[i]) //对应字母在text中未出现
continue;
root=(node *)malloc(sizeof(node)); //开辟节点
root->self=root; //记录自己的地址,方便父节点连接自己
root->left=root->right=NULL; //该节点是叶子节点,左右孩子地址均为NULL
root->ch='A'+i; //记录该节点表示的字符
root->val=hash[i]; //记录该字符的权值
p.push(*root); //将该节点压入优先队列
}
//下面循环模拟建树过程,每次取出两个最小的节点合并后重新压入队列
//当队列中剩余节点数量为1时,哈夫曼树构建完成
while(p.size()>1)
{
fir=p.top();p.pop(); //取出最小的节点
sec=p.top();p.pop(); //取出次小的节点
root=(node *)malloc(sizeof(node)); //构建新节点,将其作为fir,sec的父节点
root->self=root; //记录自己的地址,方便该节点的父节点连接
root->left=fir.self; //记录左孩子节点地址
root->right=sec.self; //记录右孩子节点地址
root->val=fir.val+sec.val;//该节点权值为两孩子权值之和
p.push(*root); //将新节点压入队列
}
fir=p.top();p.pop(); //弹出哈夫曼树的根节点
dfs(fir.self,0); //输出叶子节点记录的字符和对应的哈夫曼编码
}
int main()
{
char text[100];
int hash[30];
memset(hash,0,sizeof(hash)); //哈希数组初始化全为0
scanf("%s",text); //读入信息串text
for(int i=0;text[i]!='\0';i++)//通过哈希求每个字符的出现次数
{
hash[text[i]-'A']++; //程序假设运行的全为英文大写字母
}
huffman(hash);
return 0;
}
因为在其被合并时,需要将自己的地址传递给父节点的孩子指针。而我们每次压入队列的是一个节点变量,并不是该节点的地址,所以必须有域记录该节点的地址。那如果我们改一下优先队列的定义,让其中存储的从变量改成地址呢?
priority_queue<struct node *> p;
p.push(root);
答案仍然是否定的,优先队列的比较函数重载时不能接受地址,原因详见“liuzhanchen1987”的博客,感谢这位博主的分享。
演示程序
之前我有用VC6写过两个小程序,分别用哈夫曼编码实现编码发送信息和解码还原信息。
如果有需要可以“点击下载”,程序目前还只能传输大写英文字符,数字和少量标点;如果要传输更多的字符,扩大哈希数组的长度即可。
程序只提供源码和运行的截图,见谅^_^