基本概念
1、路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
2、结点的权及带权路径长度
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
3、树的带权路径长度
树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。
4、哈夫曼树
给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
构造哈夫曼树
Huffman树构造算法:
1、由给定的n个权值{w1,w2,w3,…,wn}构造n棵只有根节点的扩充二叉树森林F={T1,T2,T3,…,Tn},其中每棵扩充二叉树Ti只有一个带权值wi的根节点,左右孩子均为空。
2、重复以下步骤,直到F中只剩下一棵树为止:
a、在F中选取两棵根节点的权值最小的扩充二叉树,作为左右子树构造一棵新的二叉树。将新二叉树的根节点的权值为其左右子树上根节点的权值之和。
b、在F中删除这两棵二叉树;
c、把新的二叉树加入到F中;
这样最后得到哈夫曼树。

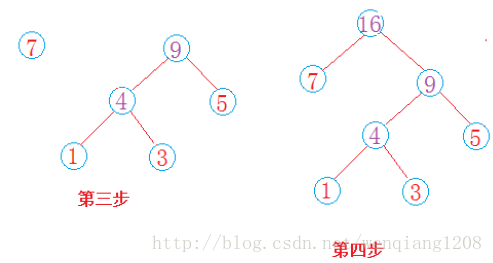
结论:从上图可以看出根节点的值为构建哈夫曼树所有节点的值和16 = 7+5+3+1
取两个值最小的值,可以用堆来实现。
#pragma once
#include <iostream>
#include <assert.h>
#include <queue>
#include <vector>
template <typename T>
struct HuffmanTreeNode
{
HuffmanTreeNode(const T &data)
: _weight(data)
, _pLeft(NULL)
, _pRight(NULL)
, _pParent(NULL)
{}
T _weight;
HuffmanTreeNode *_pLeft;
HuffmanTreeNode *_pRight;
HuffmanTreeNode *_pParent;
};
template <typename T>
struct greater
{
bool operator()(const T &left, const T &right)
{
return left->_weight > right->_weight;
}
};
template <typename T>
class HuffmanTree
{
public:
HuffmanTree(const T *weight, int size, const T &invalid)
: pRoot(NULL)
, _invalid(invalid)
{
assert(NULL != weight && size >= 0);
_Create(weight, size);
}
~HuffmanTree()
{
_Destroy(pRoot);
}
void LevelTraverse()
{
std::queue<HuffmanTreeNode<T> *> q;
if (NULL != pRoot)
q.push(pRoot);
while (!q.empty())
{
HuffmanTreeNode<T> *pCur = q.front();
q.pop();
std::cout << pCur->_weight << " ";
if (NULL != pCur->pLeft)
q.push(pCur->pLeft);
if (NULL != pCur->pRight)
q.push(pCur->pRight);
}
std::cout << std::endl;
}
HuffmanTreeNode<T> * GetRoot()
{
return pRoot;
}
private:
void _Destroy(HuffmanTreeNode<T> * &pRoot)
{
if (NULL != pRoot)
{
_Destroy(pRoot->_pLeft);
_Destroy(pRoot->_pRight);
delete pRoot;
pRoot = NULL;
}
}
void _Create(const T *weight, int size)
{
if (0 == size)
return;
else if (1 == size)
{
if (*weight != _invalid)
pRoot = new HuffmanTreeNode<T>(*weight);
}
else
{
std::priority_queue<HuffmanTreeNode<T> *, std::vector<HuffmanTreeNode<T>* >, greater<HuffmanTreeNode<T>*> >
heap;
for (int i = 0; i < size; ++i)
{
if (weight[i] != _invalid)
{
HuffmanTreeNode<T> *tmp = new HuffmanTreeNode<T>(weight[i]);
heap.push(tmp);
}
}
HuffmanTreeNode<T> *pLeft, *pRight;
while (heap.size() >= 2)
{
pLeft = heap.top();
heap.pop();
pRight = heap.top();
heap.pop();
HuffmanTreeNode<T> *pParent = new HuffmanTreeNode<T>(pLeft->_weight + pRight->_weight);
pParent->_pLeft = pLeft;
pParent->_pRight = pRight;
pLeft->_pParent = pParent;
pRight->_pParent = pParent;
heap.push(pParent);
}
if (!heap.empty())
pRoot = heap.top();
}
}
private:
HuffmanTreeNode<T> *pRoot;
T _invalid; //非法值
};哈夫曼编码
统计字符出现的个数,然后进行构建哈夫曼树;
后序遍历哈夫曼树,左0右1,对每个叶子节点
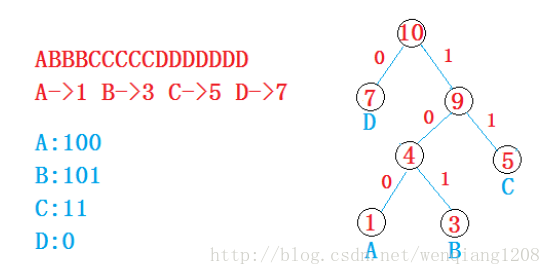
注意:在建立不等长编码时,必须是任何一个字符的编码不能是另一个字符编码的前缀,这样才能保证译码的唯一性。
任何一个字符的huffman编码都不可能是另一个字符的huffman编码的前缀。