版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/eye_water/article/details/78985745
K均值聚类,先人工制造几个中心点,根据数据寻找距离每个中心点最近的所有实例点,用所有实例点的均值代替中心点,如此反复,直到所有的实例点都被归类到正确的中心点。
例子
对于下面的实例点
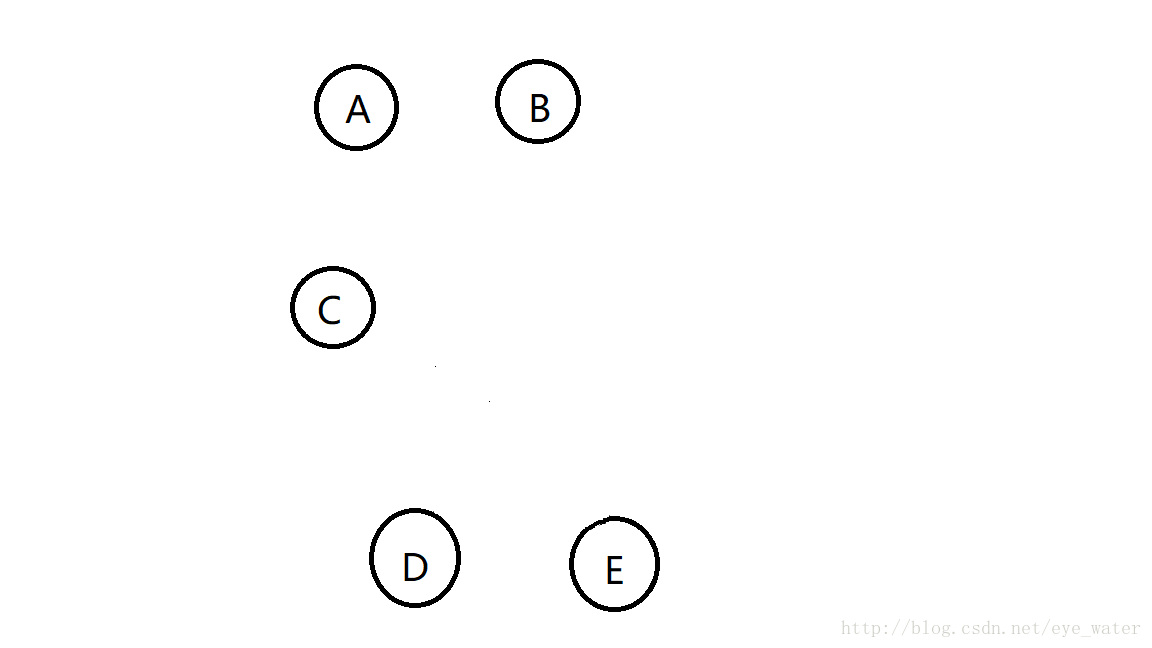
人工构造两个中心点,对于每个中心点寻找距离其最近的所有实例点,用距离其最近的所有实例点的均值代替中心点
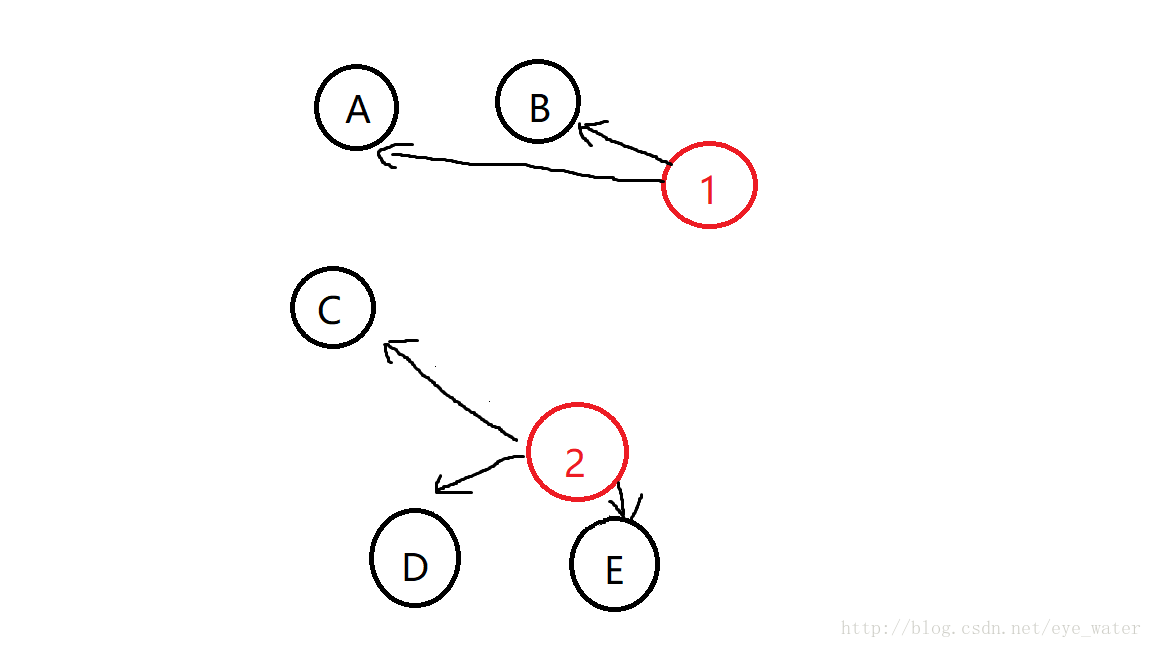
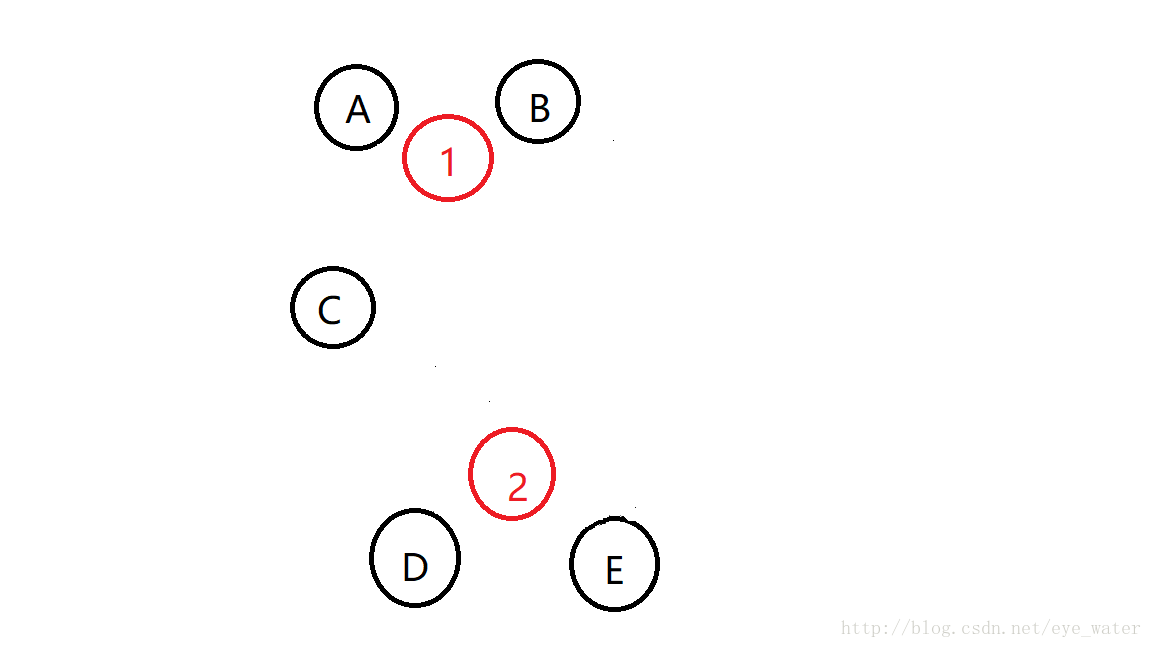
通过A与B所构造的中心点到C的距离比通过C、D、E所构造的中心点到C的距离近,因此A与B的中心点继续变化,而C与D的中心点不动
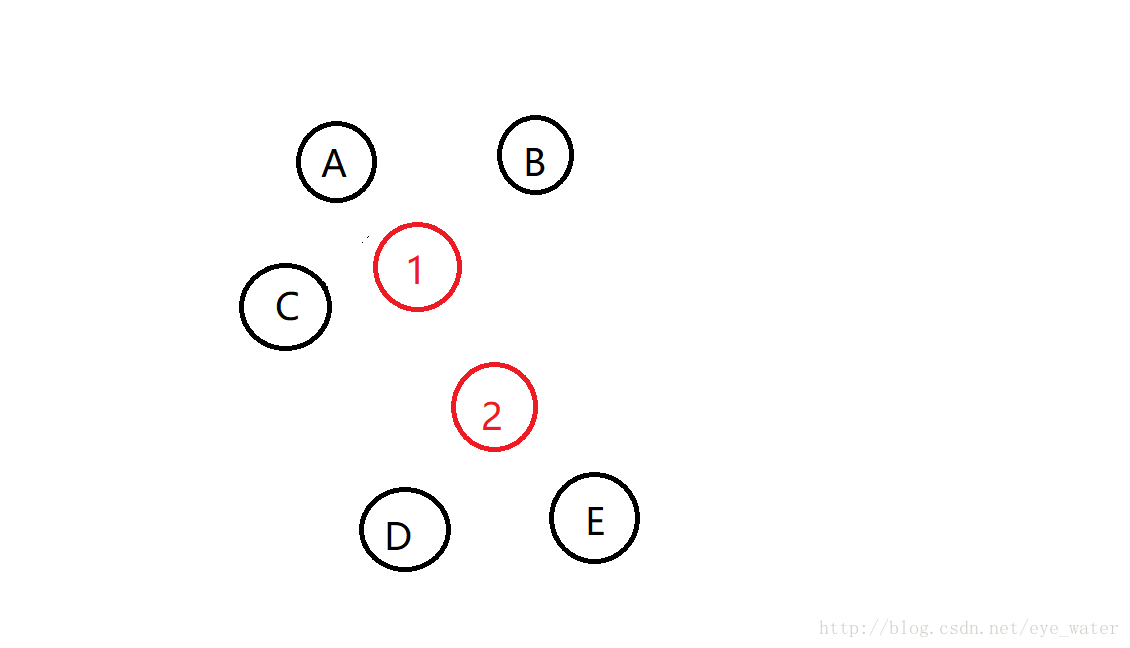
对于中心点1来说最近的实例点是A、B、C,因此即使再继续找中心点仍和原来一样,中心点2也是一样,即使继续找,位置也不会变化。
这样就完成了聚类,A、B、C为一类,D、E为一类。
代码详解
对于每一个实例看起来就像下面的表格那样
| Blog | app | Android | … |
|---|---|---|---|
| person1 | 100 | 50 | … |
| person2 | 200 | 300 | … |
| … | … | … | … |
但是表格程序是读不出来的,不过只需要数据的二维列表就行了。
计算每一个单词使用次数的最大值和最小值,计算时可以把二维列表想象成下面这样
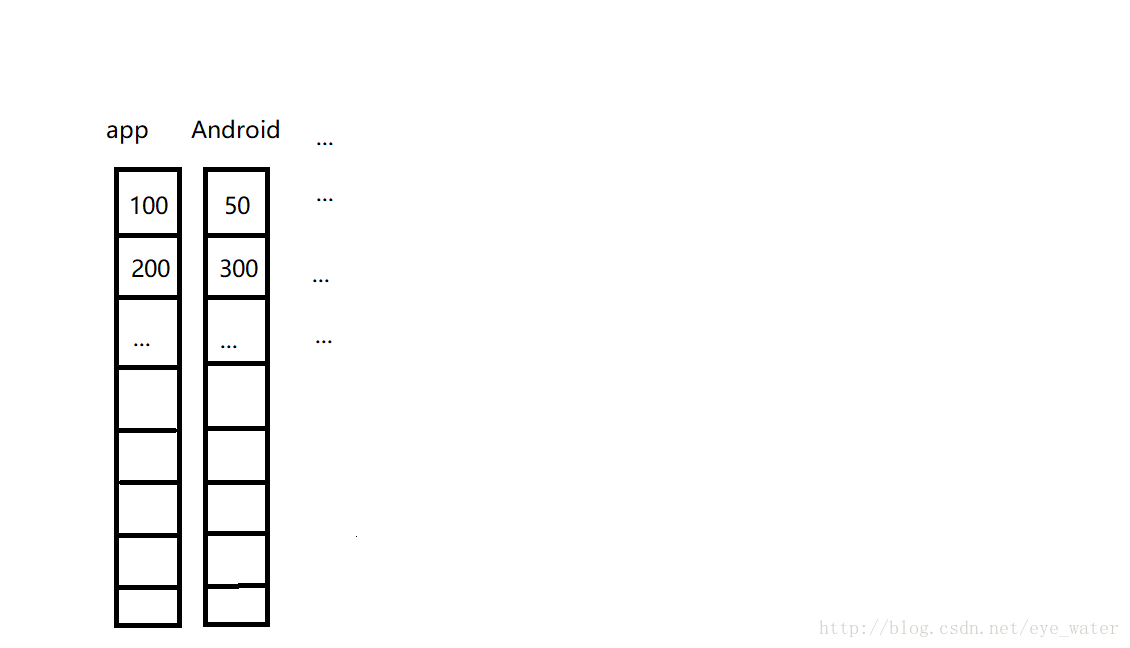
ranges = [(min([row[i] for row in rows]), max([row[i] for row in rows]))创建中心点,中心点不是只有一个数据,它相当于我们自己创建的博主,并为其随机生成单词使用次数的数据
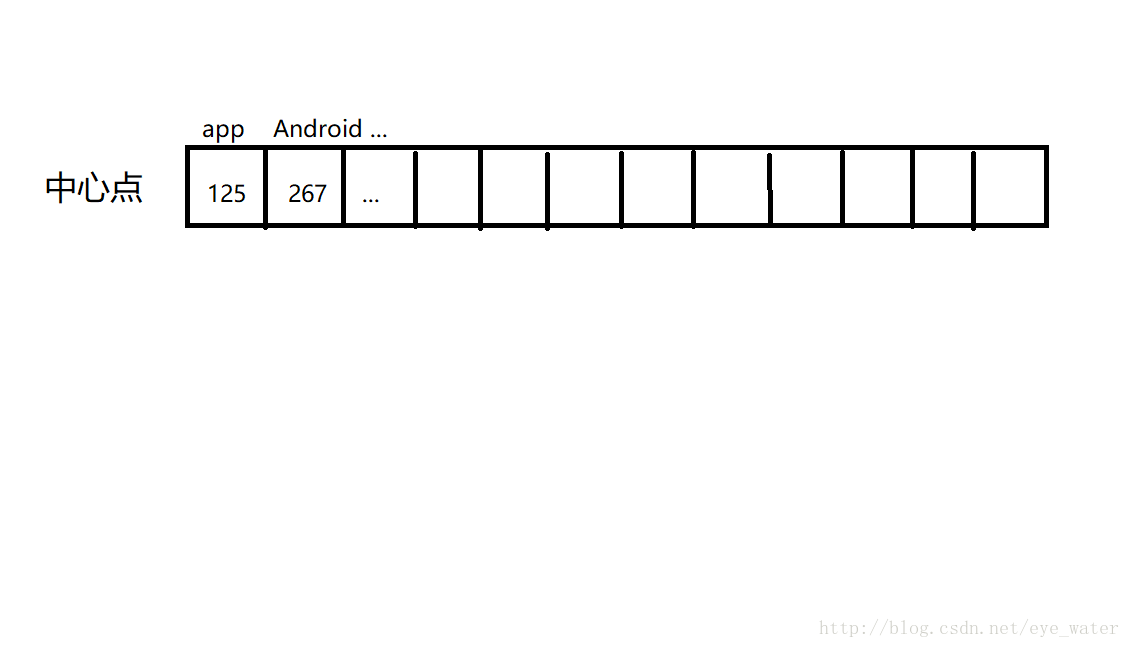
clusters = [[random.random() * (ranges[i][1] - ranges[i][0]) + ranges[i][0]
for i in range(rows[0])] for j in range(k)]建立一个for循环来进行聚类:
for t in range(20):
print('Interation %d' % t)
'''
存储与中心点最近的实例点的下标
'''
bestmatches = [[] for i in range(k)]
for j in range(len(rows)):
row = rows[j]
bestmatch = 0
for i in range(k):
d = distance(clusters[i], row)
if d < distance(clusters[bestmatch], row):
bestmatch = i
bestmatches[bestmatch].append(j)
'''
判断这一轮循环得到的距离每个中心点最近的实例点与上一轮得到的距离每个中心点最近的实例点是否相同,如果相同停止循环,否则继续
'''
if bestmatches == lastmatches:
break举个例子,如图
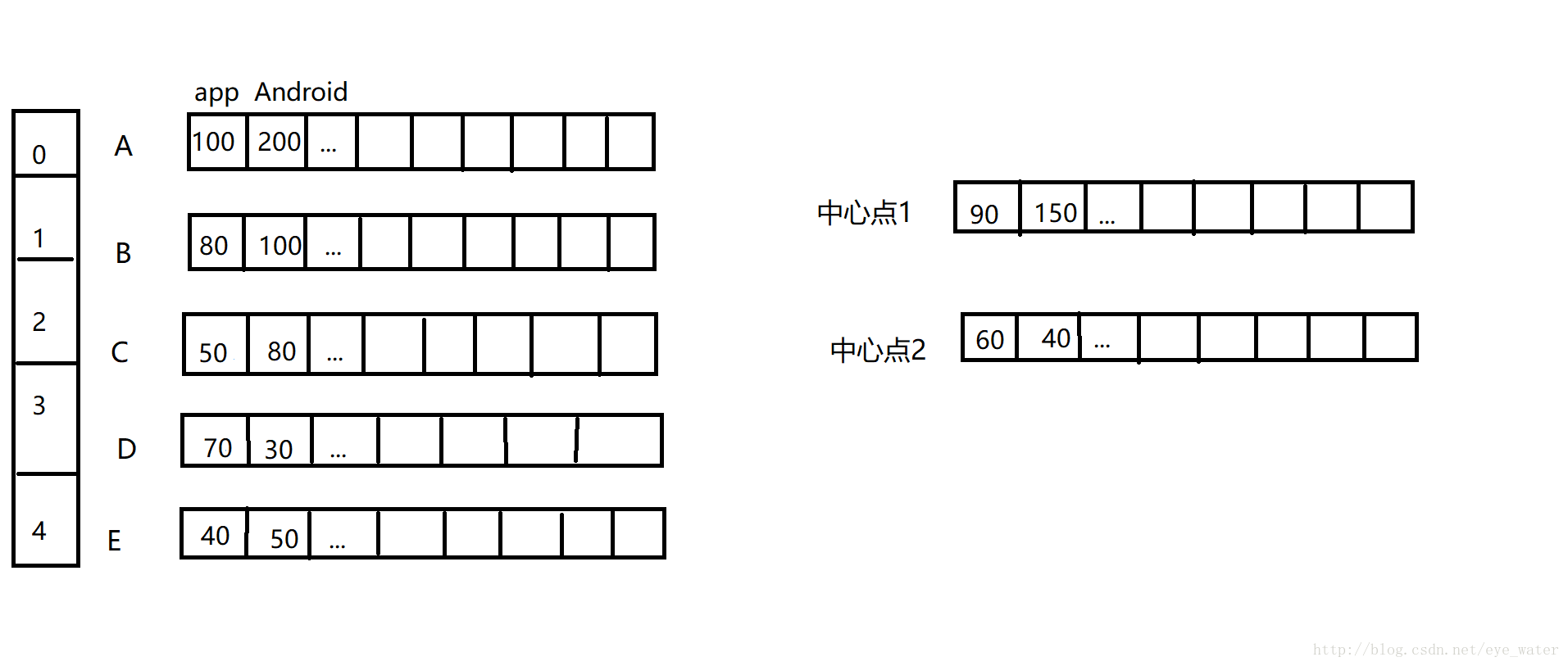
假设距离中心点1最近的实例点为A、B、C,距离中心点2最近的实例点为D、E,那么第一次循环bestmatches为:
[['0', '1'], ['2', '3', '4']]找到距离每个中心点最近的实例点后,中心点中的单词使用次数为距离每个中心点最近的一组实例点的均值
if bestmatches == lastmatches:
break
lastmatches = bestmatches
for i in range(k):
avgs = [0.0] * len(rows[0])
if len(bestmatches[i]) > 0:
for rowid in bestmatches[i]:
'''
先求和
'''
for m in range(len(rows[rowid])):
avgs[m] += rows[rowid][m]
'''
再除以实例点的个数
'''
for j in range(len(avgs)):
avgs[j] /= len(bestmatches[i])
clusters[i] = avgs那么经过处理后,上面的图片就会变成这样
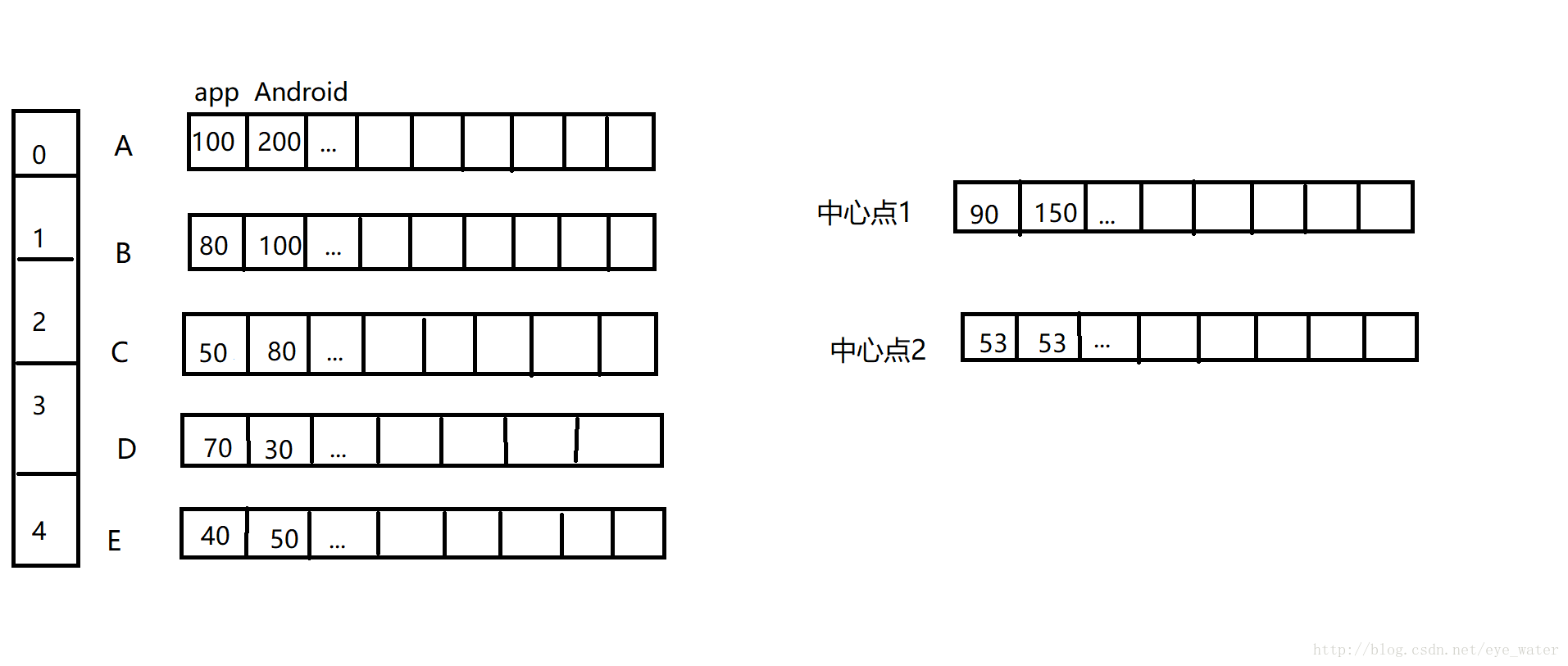
然后开始第二次循环,假设此时距离中心点1最近的点是C,那么中心点1的数值继续改变,而中心点2的数值不变:
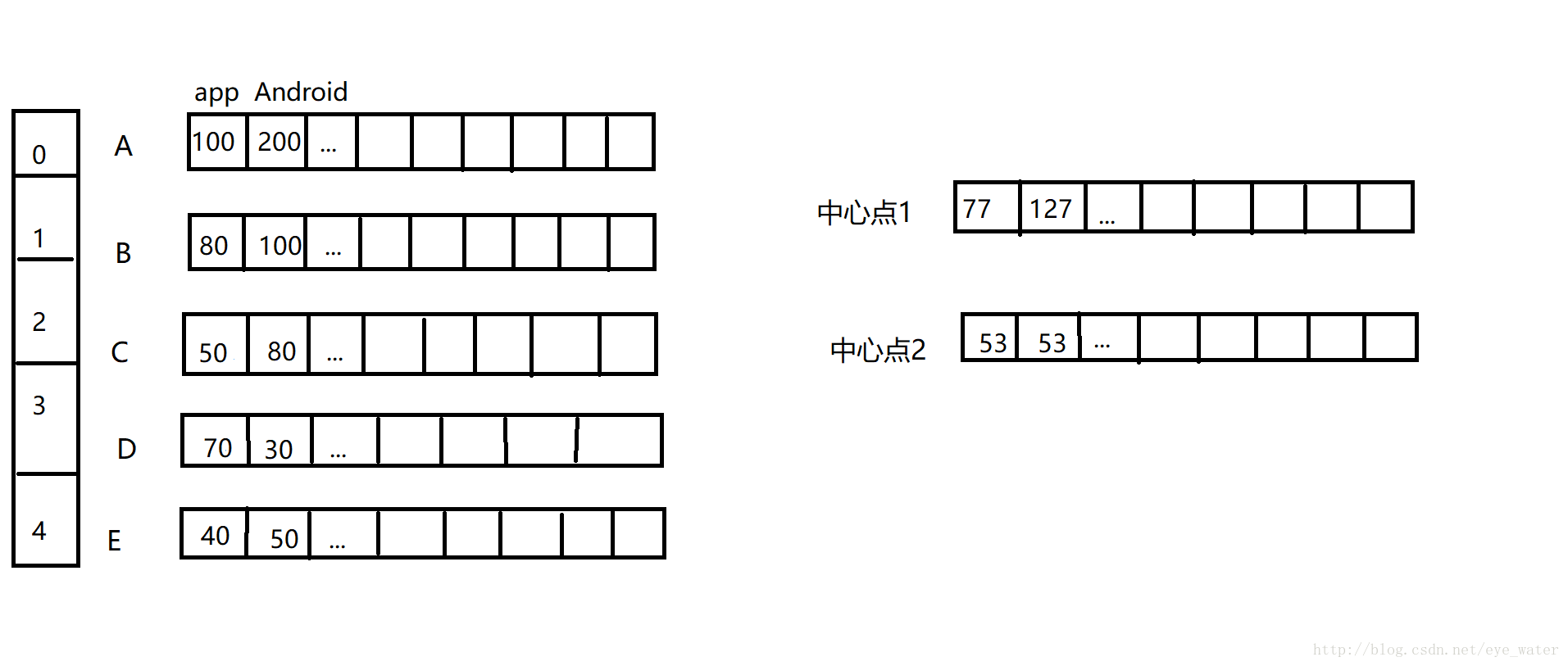
中心点1每个单词使用次数的计算公式为
第二次循环
bestmatches = [['0', '1', '2'], ['3', '4']]
lastmatches = bestmatches第三次循环
bestmatches = [['0', '1', '2'], ['3', '4']]此时,对于此次循环来说
lastmatches = bestmatches即所有的实例点都被成功地聚类,循环结束。