基础概念:
(1)数据清洗是耗神的,原因有信息不完整,噪点(比如工资为-1元),前后不一等问题。
(2)数据缺失的原因有:设备故障,采集不当,N/A(Not Apploicable:比如对男性检查宫颈,对学生调查工资)
(3)数据缺失的类型:完全随机缺失,有区分的缺失(女性不愿意说出体重),不完全随机缺失
处理数据缺失的方法:
(1)Ignore
(2)Fill possible number(再次调查或有依据的推测可能的值)
(3)统一填写(平均值或其他固定数字)
一个例子:
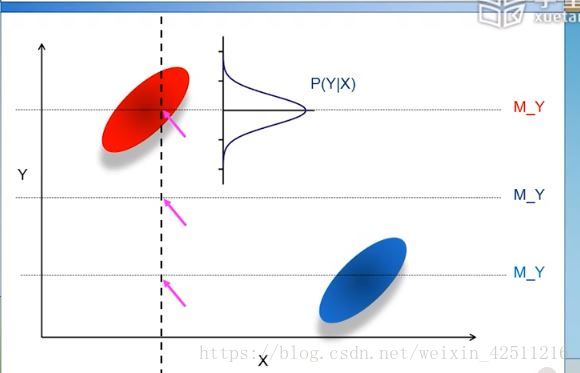
离群点
取决于相对于其他点的距离的差距,即比较性的而非量化的。
LOF方法
(局部异常因子算法-Local Outlier Factor)**
采用LOF方法进行离群点检测时:LOF值越大,越可能为离群点。
简单的说,是一个样本点周围的样本点所处位置的平均密度比上该样本点所在位置的密度。
如果密度大于1,则很有可能是异常点。
异常点和oulier的区别
姚明是oulier,而巨人症患者是异常点。
重复信息
1.调查信息表格式不同
2.不同的描述对应一个人
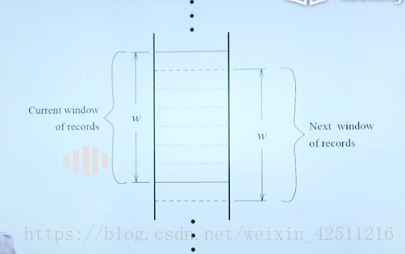
重复信息的比较:窗口化比较
前提:两者所属区域相近,生成的KEY类似。
方法:只和前面所有的信息比较,再输入下一条信息
3.文化信息
由于外国人的姓氏较为多,独一无二,所以可作为Prime key,再用名做deputy key。
数据挖掘:理论与算法 笔记(1)
猜你喜欢
转载自blog.csdn.net/weixin_42511216/article/details/81626159
今日推荐
周排行