参考博客:https://www.cnblogs.com/pinard/p/6307064.html
一、FP树的建立
(1)建立项头表
扫描事务数据集一遍,记录每个项出现的次数,根据给定的最小支持度计数或者最小支持度筛选得到频繁1项集及它们的支持度计数,按照它们的支持度计数从大到小排序得到项头表。
如:
事务数据集(每行为一个事务):

在给定最小支持度计数为2得到项头表如下:
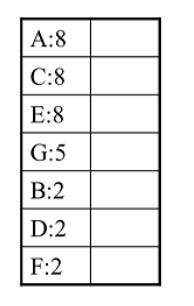
(2)过滤并排序事务数据集
因为原始的事务数据集中的事务可能包含频繁1项集中没有的项,所以对于每个事务要把非频繁1项集中的项过滤掉,同时为了方便FP树的建立我们需要把每个事务中的项(过滤后)按照其支持度大小排序,得到新事务数据集。
新事物数据集(右侧)如下:
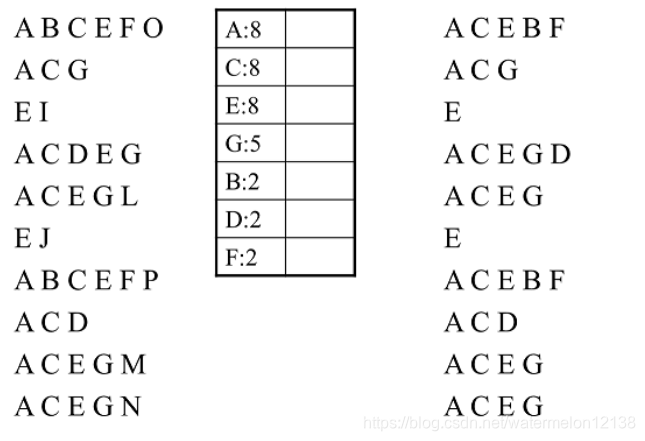
注释:
图中的右侧为过滤排序后的新事务数据集。
过滤排序:将左侧的事务数据集中的每一个事务(每一行)删除项头表中没有的项,并且剩下项按照项头表中每一项的支持度计数从大到小排序。
(3)构建FP树
①FP树的根节点默认为null
②将新事务数据集中的每个事务变成FP树中的一条路径,并统计每个项出现的次数
③对于后插入的路事务先从树的根节点开始找与其相同的部分,从第一个不重合的项开始建立一个新的分支。
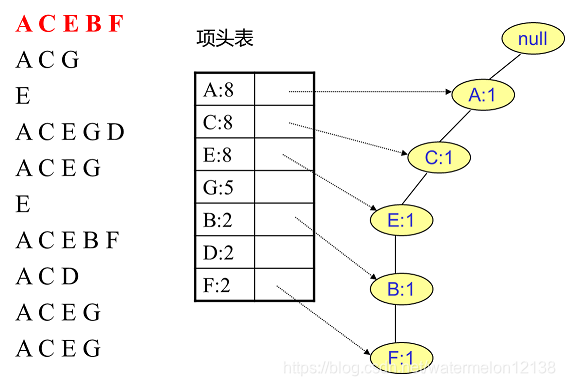
FP树中插入第1个事务:
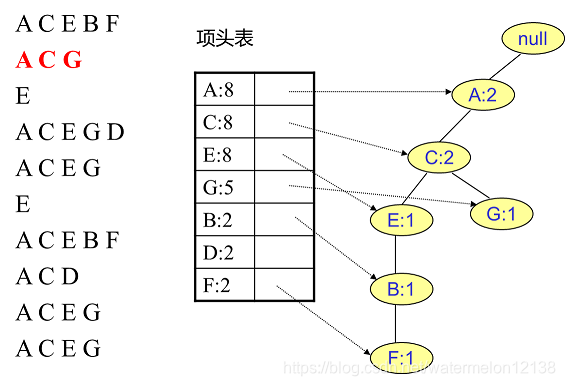
FP树中插入第2个事务:
FP树中插入第3个事务:
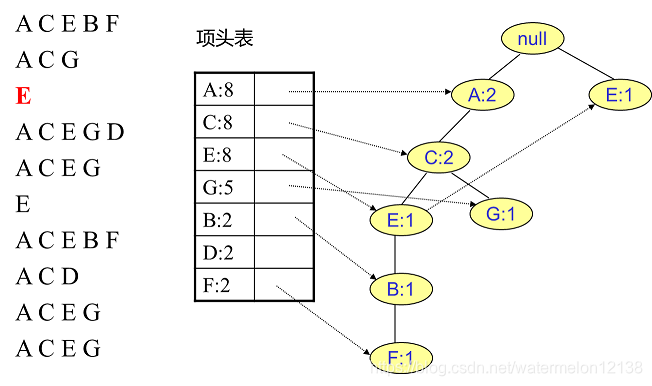
FP树中插入第4个事务:
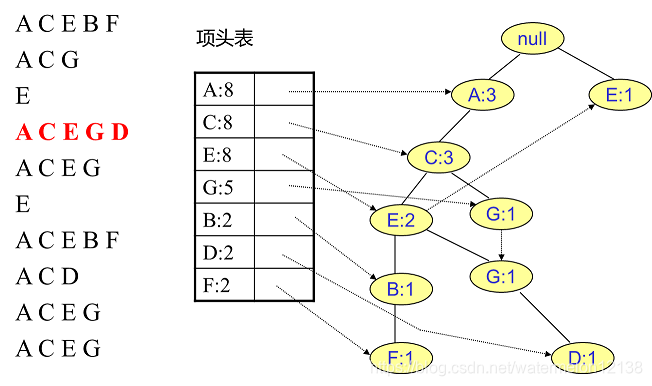
FP树中插入第5个事务:
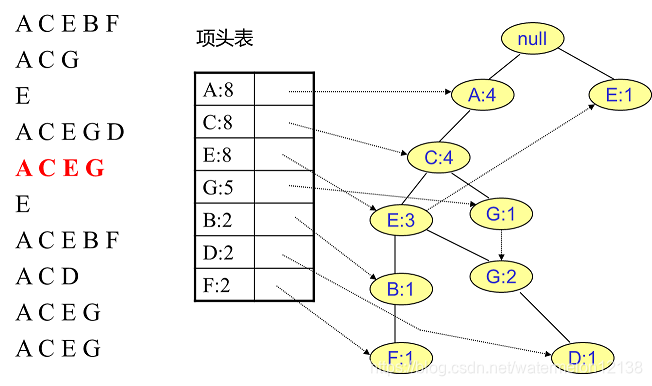
FP树中插入第6个事务:
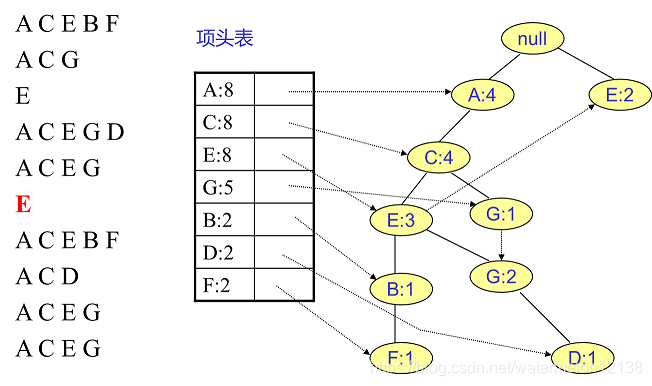
FP树中插入第7个事务:
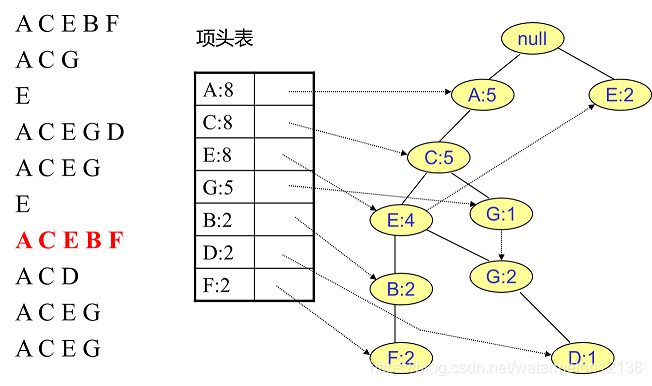
FP树中插入第8个事务:
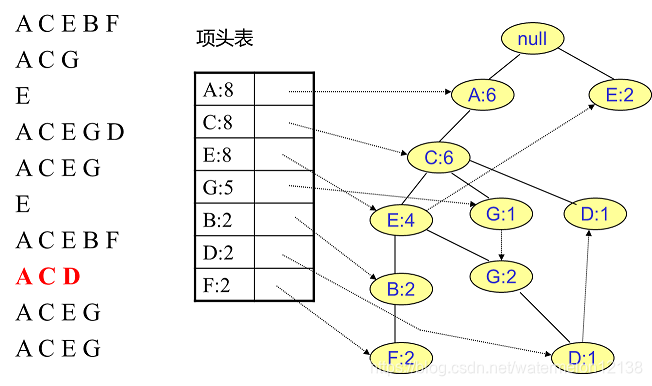
FP树中插入第9个事务:
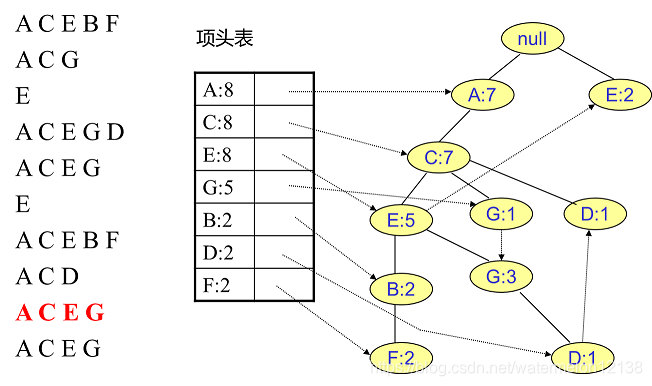
FP树中插入第10个事务:
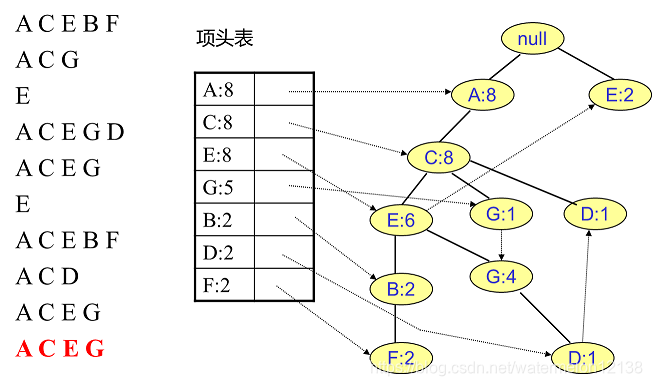
一、FP树的挖掘
通过建立的FP树,从项头表的最后一项从下到上开始挖掘频繁项集。
步骤:
从项头表的最后一项从下到上开始,如当前项为i
①得到以 i 结尾的所有路径的前缀路径,前缀路径是指每个路径删掉该项后的路径。通常前缀路径的最后一项是一个数字,用来记录该路径出现的次数,该数字以项 i 的计数为准。
如:项F的前缀路径为(A,C,E,B,2),由以项F结尾的路径(A,C,E,B,F)删掉F得到,并且项F的计数为2,所以(A,C,E,B,F)路径出现的次数为2。
②根据项 i 的所有前缀路径得到条件模式基,条件模式基是将项 i 的所有前缀路径根据计数合并,过滤掉小于最小支持度的项。
如:项D的前缀路径为(A,C,E,G,1),(A,C,1),根据D的前缀路径最后的计数很容得到前缀路径中每一项出现的次数(A:1,C:1,E:1,G:1),(A:1,C:1),然后将所有的前缀路径合并得到(A:2,C:2,E:1,G:1)因为E和G的计数小于最小支持度计数2,所以将其过滤得到最终的条件模式基(A:2,C:2)
③根据项 i 的条件模式基画出项 i 的条件FP树。
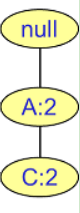
如项D的条件FP树为:
④根据项 i 的条件FP树得到项 i 的频繁项集。从左到右遍历项 i 的条件FP树的每一条路径,用路径中的每单个节点和项 i 组合得到项 i 的频繁2项集,用路径中每2个节点与项 i 组合得到频繁3项集,以此类推用路径中的每k个节点与项 i 组合得到项 i 的频繁k+1项集。
如项D的频繁项集为:
频繁2项集:(A,D,2),(C,D,2)
频繁3项集:(A,C,D,2)
例子:
(继续上文中的例子)
- 挖掘项F的频繁项集
F的前缀路径:(A,C,E,B,2)
F的条件模式基:(A:2,C:2,E:2,B:2)
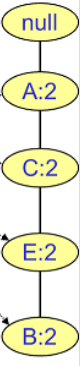
F的条件FP树:
F的频繁项集:
频繁2项集为(A,F,2),(C,F,2),(E,F,2),(B,F,2)
频繁3项集为(A,C,F,2),(A,E,F,2),(A,B,F,2),(C,E,F,2),(C,B,F,2),(E,B,F,2)
频繁4项集为(A,C,E,B,F,2) - 挖掘项D的频繁项集
D的前缀路径:(A,C,E,G,1),(A,C,1)
D的条件模式基:(A:2,C:2,E:1,G:1)过滤掉E和G为(A:2,C:2)
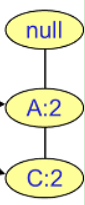
D的条件FP树:
D的频繁项集:
频繁2项集为(A,D,2),(C,D,2)
频繁3项集为(A,C,D,2) - 挖掘项B的频繁项集
B的前缀路径:(A,C,E,2)
B的条件模式基:(A:2,C:2,E:2)
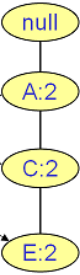
B的条件FP树:
B的频繁项集:
频繁2项集为(A,B,2),(C,B,2),(E,B,2)
频繁3项集为(A,C,B,2),(A,E,B,2),(C,E,B,2)
频繁4项集为(A,C,E,B,2) - 挖掘项G的频繁项集
G的前缀路径:(A,C,E,4),(A,C,1)
G的条件模式基:(A,:5,C:5,E:4)
G的条件FP树:

G的频繁项集:
G的频繁2项集为(A,G,5),(A,C,5),(E,G,4)
G的频繁3项集为(A,C,G,5),(A,E,G,4),(C,E,G,4)
G的频繁4项集为(A,C,E,G,4) - 挖掘项E的频繁项集
E的前缀路径:(A,C,6)
E的条件模式基:(A:6,C:6)
E的条件FP树:
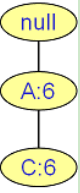
E的频繁项集:
E的频繁2项集为(A,E,6),(C,E,6)
E的频繁3项集为(A,C,E,6) - 挖掘项C的频繁项集
C的前缀路径:(A,8)
C的条件模式基:(A:8)
C的条件FP树:
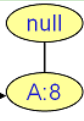
C的频繁项集:
C的频繁2项集为(A,C,8) - 挖掘项A的频繁项集
A的前缀路径:无
A的条件模式基:无
A的条件FP树:无
A的频繁项集:无