图文匹配以及图像的QA是图像与文本多模态融合,是计算机视觉与自然语言处理的交叉。
图文匹配:将图像与文本都映射到一个相同的语义空间,然后通过距离对他们的相似度进行判断。
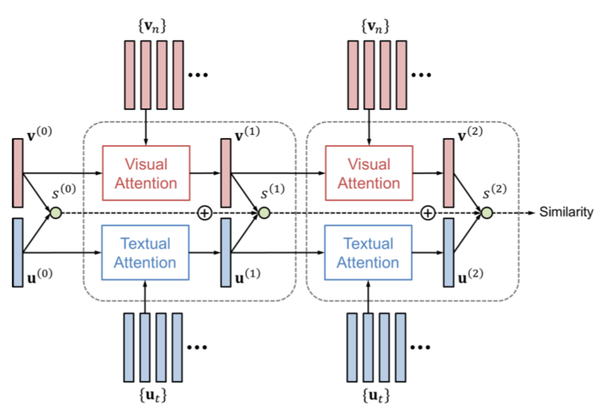
图文匹配问题与VQA最大的不同就是,需要比对两种特征之间的距离。将文本和图像分别做attention,DAN计算每一步attention后的文本和图像向量相似度累加得到similarity.
VQA:给定一张图像和一个关于该图像内容的文字问题,视觉问答旨在从若干候选文字回答中选出正确的答案,本质上是一个分类问题,其核心思想是让图像的Attention的位置随着问题进行变化。
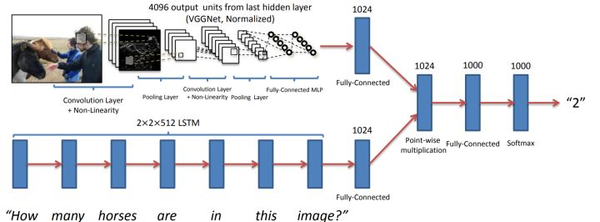
使用CNN从图像中提取图像特征,用RNN从文字问题中提取文本特征,融合视觉和文本特征,最后通过全连接层进行分类。该任务的关键是如何融合这两个模态的特征。 直接融合的方法几种:视觉和文本特征向量拼接、逐元素相加或相乘、内积、外积。
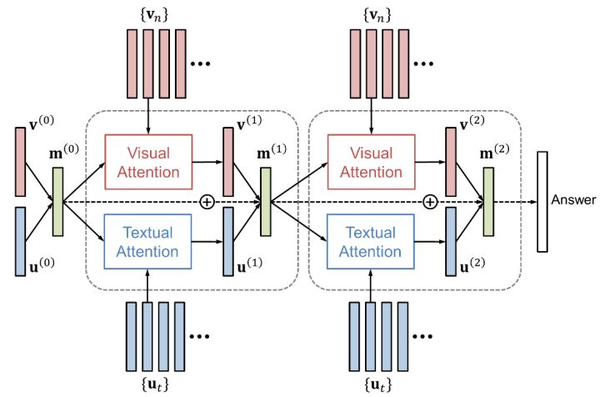
注意力机制包括视觉注意力(“看哪里”)和文本注意力(“关注哪个词”)两者。DAN将视觉和文本的注意力结果映射到一个相同的空间,并据此同时产生下一步的视觉和文本注意力。

通过视觉特征向量和文本特征向量的外积,可以捕获这两个模态特征各维之间的交互关系。
总结
1.最基本的是文本和图像的encoder模型都要足够的好
2.特征的融合
目前有两种融合特征的方式,一个是前融合一个是后融合。 前融合将图像信息与文本信息输入到一个网络进行进一步的encoder,最后再使用任务相关的网络;后融合就是图像文本的encoder出来的特征直接concat,然后输入到任务相关的网络,一般来说前融合的网络要好于后融合。
3.图文匹配是一个全部句子与全部图像的匹配问题,直接去解这个问题可能相对来说比较困难, 所以一个最基本的想法就是把这个问题分为多个元素。
Text由不同的单词构成,Image由不同的区域构成,如果能把Text的单词与Image的区域进行一个匹配,那么这个问题就会变得比较简单。
4.模型训练中可以有很多的trick