艺术 文化遗产 VQA parper阅读
A Dataset and Baselines for Visual Question Answering on Art
前言
QA与艺术作品(绘画)有关的问题是一项困难的任务,因为这意味着不仅要理解图片所显示的视觉信息,而且要通过艺术史的研究获得上下文知识。在这项工作中,我们首次尝试建立一个新的数据集,创造了AQUA(艺术问题回答)。基于现有艺术理解数据集中提供的绘画和评论,使用最先进的问题生成方法自动生成问答(QA)对。QA组由众包工作人员在语法正确性、可回答性和答案正确性方面进行清理。AQUA数据集本质上由视觉(基于绘画)和知识(基于评论)问题组成。我们还提出了一个双分支模型作为基线,其中视觉和知识问题是独立处理的。我们将我们的基线模型与最先进的问题回答模型进行了广泛的比较,并对艺术视觉问题回答的挑战和潜在的未来方向进行了全面的研究。
贡献点
•首先,我们提出了一项新的艺术答题任务,它本质上涉及对绘画的视觉理解和知识。后者可以被视为文本理解,因为这类知识可以在书籍和在线文档中找到,如维基百科。回答需要视觉和文本模式的问题迄今为止还没有很好地探索过。
•其次,我们建立了一个初步的数据集AQUA,并将其公开QA对由众包工作人员手动清理,以确保每个问题的可答性、语法正确性以及答案的正确性。
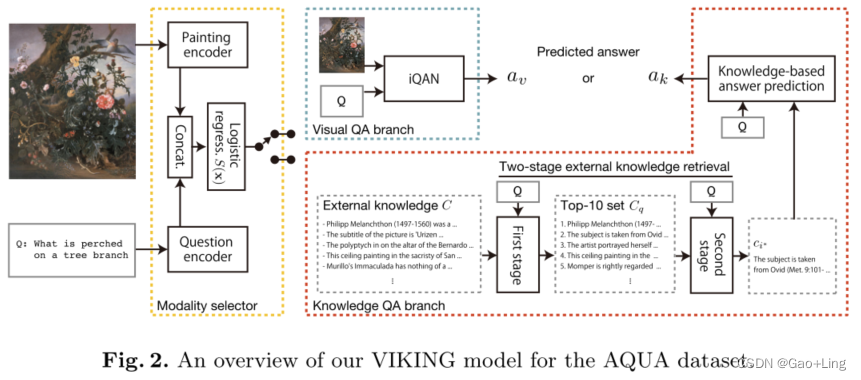
•第三,我们提出了一个名为VIKING的基线模型,用于我们的art QA任务。
除了问题之外,基线模型还使用从知识库中检索到的绘画和段落来预测与问题和绘画相关的答案。
AQUA Dataset
我们使用SemArt数据集[14]它最初是为语义艺术理解而设计的 作为生成QA对的来源。SemArt数据集包含绘画和相关的评论,其中评论是文本块,有时包括关于绘画的元数据,如作者姓名和创作年份。他们也可以写几句关于画中的故事和创作时的背景,如社会和作者的个人情况。这些评论就是知识。为了展示AI技术理解绘画的潜力,重要的是探索不仅适用于绘画本身的视觉内容,而且适用于其周围思想的技术。因此,我们用各自的问题生成方法从视觉和知识模式中生成QA对。
任务定义
对于AQUA数据集,可以有几种可能的任务定义。在这篇论文中,我们关注的是所有与绘画相关的评论都是可用的。更具体地说,设C = {ci|i = 1,…, N}表示所有注释的集合。AQUA任务的目的是在给定绘画v的情况下用C回答问题q,而v和C中的特定注释之间没有明确的关联。在这个任务中,C可以被视为一个外部知识来源,包含在正确检索与q相关的注释时回答问题所需的信息。
这个任务的一个更具挑战性的扩展是不使用C而是使用其他的知识来源,例如维基百科。使用这种扩展,性能还取决于源的质量及其与原始源的亲和性。我们将扩展作为未来的工作。