VQA综述类论文的阅读
VQA综述类论文的阅读
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
A Survey on VQA: Datasets and Approaches
Y. Zou 和 Q. Xie,“A Survey on VQA: Datasets and Approaches”,2020 年第二届信息技术与计算机应用 (ITCA) 国际会议,2020 年,第 289-297 页,doi: 10.1109/ITCA52113.2020.00069。
回顾和分析为VQA任务提出的现有数据集、度量和模型。
介绍
VQA的子任务可以分为两类:
- 一类是利用图像中的ground truth信息完成的任务
包括细粒度识别(例如,“披萨上有什么奶酪?”)、
场景识别(例如,“今天天气怎么样?”)、
活动识别(例如,“这个女孩在走路吗?”)、
物体检测(例如,“图像中有树吗?”)、
属性分类(例如,“她的眼睛是什么颜色?”)
计数(例如,“图像中有多少只鸟?”)。 - 另一类则需要根据图像之外的知识进行推理
包括基于知识的推理(例如,“这是一个素食三明治吗?”)、
常识推理(例如,“她为什么哭?”)
空间关系识别(例如,“狗在房子前面吗?”)。
数据集
近年来,随着VQA任务越来越受到研究者的重视,可视化答题数据集的多样性不断增加。例如,提出了VQA v2[18]和VQA-CP[19]来消除语言先验,增强模型的视觉理解能力。
与VQA[20]、Visual Genome[21]、Flickr30k[22]等内容比较全面的数据集相比,也发布了一些专注于特定场景的数据集。FigureQA[7]是一个由科学图表组成的图像数据集,旨在推动对统计数字的可视化理解的研究。
Social-IQ [23]是一个视频数据集,旨在增强模型的情感检测。
此外,基于知识的推理任务和常识推理任务受到越来越多的关注,知识型数据集也应运而生。因此,R-VQA [24], FVQA [25], KVQA[26]等被提出。
在图像数据集被广泛开发的同时,视频数据集也被发布,如MovieQA[3]、PororoQA[27]、TVQA[28]等。
【数据集收集】用于视觉问答VQA常用的数据集(持续更新,最后更新时间2019-09)
图像类数据集
- DAQUAR[29]
基于NYU-Depth V2数据集[30],真实世界的图像问答数据集被构建。通过人工和机器生成两种方法对数据进行了标注。生成的问答对是根据模板自动生成的,而人工问答对是由内部参与者收集的。对于人类生成的问答对,由于注意机制导致人们将注意力集中在图像中突出的对象上,因此存在偏差。 - Flickr30k entities[22]
在Flickr30k数据集成为被广泛接受的可视化问题回答任务基准之后,Flickr30k entities得到了扩充,以便训练和测试。Flickr30k entities包含31783张图片,主要聚焦于人和动物,每张图片平均有5个英文注释。它识别出相同图像的哪些注释指向同一组实体。因此,生成了244,035个会议链和275,775个提取图像中实体的边界框。 - **VQA[**20]
VQA是一个综合数据集,包含来自MS COCO[31]的204,721张图像和来自抽象数据集[32]的50,000个场景。VQA任务收集了开放式和多项选择的问答对。在这个数据集中,几个问题回答对被分配到一个图像。回答VQA数据集中的任何问题都需要常识,而许多问题只要求基本事实的答案。它已经成为VQA任务的标准基准。 - Visual Genome[21]
视觉基因组旨在促进认知任务的进展,特别是空间关系推理。该数据集包含超过108,000张图像,平均有35个对象、26个属性和21个对象之间的成对关系。它重视标注空间中的关系和属性,因为它们是视觉理解的基本要素。因此,它在这个数据集中为图像的不同组件收集了50多个描述。 - ** Visual7W[33]
Visual7W应用6个W问题(what, where, when, who, why, how)来系统地检查模型的视觉理解能力,并附加“which”问题类别。数据集中的问题被标准化为多项选择题格式。每道题有四个候选人,只有一个候选人是正确答案。 - Visual Madlibs[34]
Visual Madlibs是一个包含360,001个目标描述的数据集,这些描述来自12种不同类型的模板及其对应的图像。有了这个数据集,可以生成更细粒度和更具体的描述,以便向模型提出更详细的问题。此外,关于超出GT信息范围的问题也被描述在图像中。 - FM-IQA[35]
FM-IQA是一个大规模的多语言可视化问答数据集。它是由MS COCO[31]生成的。共有158,392张图片,中文问答对和英文翻译有316,193对。每个图像至少有两个问答对作为注释。问题和答案的平均长度分别为7.38和3.82。将1000对问答对及其对应的图像随机添加到测试集中。
Balanced VQA
数据集中存在的统计偏差和语言先验会干扰性能评估,因为模型可以利用问题的语言结构和答案的相应统计模式进行欺骗以获得更好的结果。例如,在VQA[20]数据集中,以“多少”[18]开头的问题中,“2”是39%的正确答案。通过这种技巧,在具有语言先验和统计偏差的数据集上训练的模型可以在不理解图像的情况下回答问题。为了解决这一问题,提出了一些数据集,如VQA2.0[18]。
- 基于抽象场景的二元视觉问答[36]
该数据集通过创建成对的互补场景并将问题转换为总结两个对象之间关系的元组,消除了二进制可视化问题回答任务中的统计偏差和语言先验。因此,回答二进制问题的任务被转化为可视化验证,因为模型只需要检测图像中是否存在一个对象并返回“是”或“否”。在这个数据集上,一些先进模型的性能比VQA差。这一现象证明了语言优先导致一些先进模型的性能被高估了。 - VQA v2.0[18]
VQA v2.0建立在一个假设之上,即一个平衡的数据集将迫使模型专注于视觉信息。它通过从VQA数据集中给出一个(图像、问题、答案)三元组(I、Q、A),并要求人们识别一个图像I“与I相似,但问题Q的答案变成A”,来平衡VQA[20]数据集。因此,模型将被迫理解图像中包含的信息,因为相同的问题对两个不同的图像有两个不同的答案。VQA v2.0包含110万个(图像、问题)对和1300万个相关答案。与二进制VQA数据集[36]相比,VQA v2.0更加全面,因为它从MS COCO[31]生成了平衡的真实世界图像,而不是只关注抽象的场景,并且将问题从二进制问题扩展到所有问题。 - VQA- cp v1 & VQA- cp v2[5]
创建VQA- cp v1和VQA CP-CP v2分割,通过改变每种题型在训练集和测试集中的答案分布,来减少答案中存在的统计偏差的影响。他们分别用问题分组和贪婪再分裂的方法对VQA v1和VQA v2数据集中的数据进行分裂和重组。在问题分组中,为同一任务生成的、对应于同一GT答案的问题被分组在一起。例如,(“狗是什么颜色”,白色)和(“鸟是什么颜色”,白色)被分组在一起,而(“狗是什么颜色”,白色)和(“狗是什么颜色”,黄色)被分到不同的组。随后,设计了一种贪心方法,将数据重新分配到训练集和测试集,考虑到概念的数量最大化,并防止组在训练集和测试集之间重复。
VQA-CP v1的训练集由118K图像、245K问题和250万答案组成,测试集由87K图像、125K问题和130万答案组成。在VQA-CP v2中,有121K图像、438K问题和440万个答案用于训练,98K图像、220K问题和220万个答案用于测试。baseline模型在VQA- cp上的性能下降表明该数据集为VQA模型提供了一个相对平衡的环境。
Datasets of Statistical Figures统计数字数据集
近年来,许多集中于科学数字的数据集的出现,推动了对图表中所包含的统计性质的理解研究。图表可视化问答任务与一般可视化问答任务有许多不同之处。一个区别是物体的属性对于自然图像和科学图像有不同的重要性,尤其是颜色和面积。颜色和面积都是影响自然图像中物体性质问题的唯一属性,而它们在科学图解中具有独特的意义。例如,柱状图中相同的颜色表示同一类别的对象,柱状图的面积对应同一类别下的对象数量。
因此,发表的科学图表数据集提供了一个机会来开发关于统计数字唯一性的模型。
- DVQA[6]
- FigureQA[7]
- LEAF-QA[37]
Knowledge-based Datasets
由于视觉答题任务被认为是评估系统理解能力的一个代理,现有的VQA工作专注于生成GT的答案,这对于“AI-complete”任务是不够的。例如,传统的视觉答疑系统可以识别出图像中的红色物体是消防栓,但不知道消防栓是用来阻止火势蔓延的。
与传统的VQA任务相比,Knowledge-based VQA任务更具挑战性。它要求模型识别必要的知识,在知识库中找到必要的知识,并结合知识、图像特征和问题表示来回答问题。一些基于知识的数据集被提出,以促进基于知识的推理任务的发展,并为评估提供基准。
-
KBVQA数据集
KBVQA数据集的目标是在提供外部知识的情况下,构建一个评价VQA模型在高知识水平问题和显式推理任务上表现的基准。为了构建数据集,在MS COCO[31]中选择了700张图像,包括大约150个对象类和100个场景类。对于图像,人工提问者生成了2402个问题回答对,从物体识别问题、属性检测问题到常识推理问题(即不需要引用外部来源)和基于知识的推理问题(如“这幅图像中的家电是什么时候发明的?”) -
FVQA[25]
除了图像和问答对,基于事实的VQA数据集还提供了支持事实,这是存储在外部KBs中的知识的结构化表示,对于回答给定的视觉问题不可或缺。该数据集从MS COCO[31]中采样了2190张图像,并提取了三种类型的对象:对象(即命名实体,如人、狗和树),场景(如办公室、卧室和海滩)和动作(如游泳、跳跃和冲浪)。知识提取自DBpedia[38], ConceptNet[39]和WebChild[40]。共收集了5826个问题对应的4216个独特事实。 -
KVQA[26]
知识感知型VQA(Knowledge-aware VQA)数据集包含183,007个问题-答案对,在24,602张图像中包含约18,000人。回答KVQA数据集中的问题需要多实体、多关系和多跳推理。
与KB-VQA和FVQA相比,KVQA不仅拥有更大的尺寸,而且导致了视觉实体链接的问题,其中的任务是将出现在图像中的命名实体named entity链接到Wikidata中的一个实体。它提供了一个支持集support set,其中包含来自Wikidata的69000人的参考图像,从而实现了可视化的命名实体链接。 -
R-VQA[24]
Relation-VQA建立在Visual Genome[21]数据集上。它包含33.5万个数据样本,每个样本由(图像、问题、答案)对和对齐的支持关系事实组成。关系事实包括三种不同的类型:实体概念(there, is, object),实体属性(subject, is, attribute),以及实体的关系(subject, relation, object),基于视觉基因组中概念、属性和关系的注释语义数据。 -
OK-VQA[41]
Outside Knowledge, VQA数据集包括12,951个独特的问题,总共14,055个,14,031张图片从MS COCO[31]中选择。本数据集所包含的知识是常识知识,包括十个类别:车辆与交通;品牌;公司和产品;对象;材料和服装;体育和娱乐;烹饪和食物;地理位置;历史;语言和文化;人与日常生活;植物和动物;科学技术和天气气候。
Datasets of Videos
近年来,研究者试图将视觉答题任务从离散图像扩展到连续视频。与图像相比,视频问答任务对理解能力和多模态信息融合能力的要求更高,特别是在复杂场景中。为了加强视频VQA任务的开发,提出了几个数据集,从电影、戏剧和社会场景与现实环境高度相关,到抽象卡通。
- MovieQA[42]
- TVQA[2]
- TVQA+[28]
- PororoQA[27]
- Social-IQ[23]
- KnowIT VQA[43]
推理能力诊断数据集
首先利用CLEVR[44]数据集对视觉系统的推理能力进行了系统分析,该数据集包含10万张图像和999968个问题。在CLEVR中,图像是简单的三维图形,每张图像所包含的信息是难以捉摸和完整的。数据集的这些特征促使具有较强推理能力的模型被提出。随后,RAVEN[45]在2019年被提出,以推动推理能力进化到更高的水平。它由1120,000张图像和70000个RPM问题组成,这些问题被广泛认为与真实智能高度相关。此外,这些问题被标记为树形结构,数据集中总共包含1120,000个标签。此外,设计了5个规则控制属性和2个噪声属性,以攻击视觉系统在短时记忆和成分推理方面的主要弱点。
评估方法
Accuracy
可视化问题回答数据集中的问题可以分为两类:
- 需要用自然语言回答的开放式问题
- 需要模型从候选答案中选择一个正确答案的多项选择问题。
对于选择题,通过计算正确答案与总答案的比例,利用简单的准确性来评价模型的性能是有效的。
准确性也可以用于评估开放式问题,但它可能会导致一些问题。这是因为惩罚不能反映语义差异的大小。例如,“大海里有什么?”可能是三文鱼。如果一个模型生成的答案是“鱼”,它将与答案“否”一样被扣分。为此,提出了一些改进指标的方法,以提高指标的精度。
Modified WUPS Score [29]
提出了Modified WUPS Score(改进的WUPS评分)来衡量模型生成的答案与人工标注者提供的标签之间的语义差异。它建立在模糊集(Fuzzy Sets[46] )和WUP评分[47]上。WUP评分通过遍历语义树,计算两个词之间路径上的节点数量,并计算共同的subsumer来评估两个词的相似度。
之后,一个0到1之间的分数将分配给单词对。例如,(窗帘,百叶窗)对的WUP得分是0.94。分数越大,两个词越相似。在这个度量下,答案在语义上与标签更相似,因此受到的惩罚会更少。WUPS评分定义如下:
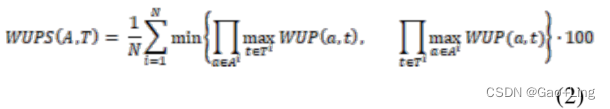
然而,在这个标准下,距离较远的单词会得到相对较高的分数。因此,设置阈值来决定何时降低WUP评分的权重。如果WUP评分低于阈值,则权重将通过乘以一个因子(建议为0.1)来缩小。将Modified WUPS Score应用于DAQUAR数据集上的模型评估。
然而,它也有一些缺点。
- 它可以给高分的答案,语义相似的标签,但有不同的含义。
- 该方法对属性检测任务有负面影响。例如,红色和粉色在语义上是相似的,但是对于一个要求模型识别红色消防栓颜色的问题,粉色的答案不应该得到高分。
- 此外,WUPS评分只能用于评价离散概念之间的相似性。它不能应用于答案是短语或句子的问题,如“为什么”问题。
Consensus [48]共识,一致性
提出这个指标是为了给更多人工注释者喜欢的答案分配更高的优先级。对DAQUAR[29]数据集提出了两个共识。一个是平均共识[48],另一个是最小共识[48]。
平均共识被定义为:
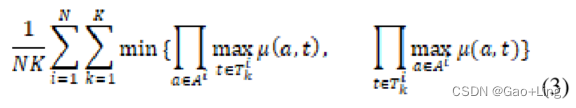
最小共识定义为:
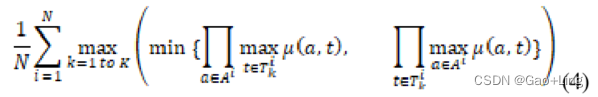
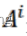 :第i个问题的答案
:第i个问题的答案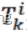 对于第i个问题,人类提供的第k个答案。
对于第i个问题,人类提供的第k个答案。
与平均共识相比,平均共识是根据人工注释者的受欢迎程度来排序的,最小共识,最小共识只需要一个人工注释者的答案就能达到共识。
Manual Test 手动测试
手动测试是指所有的答案都由人工进行评估。例如,数据集FMIQA[35]上的模型由人类进行评估,每个人为每个答案提供从0到2的分数,以对他们的正确程度进行排名。与上述指标相比,手工测试可以处理语义复杂性和固有模糊性相对较高的答案,但在时间、金钱和其他资源上的成本也较高。虽然已经提出了许多评价开放式问题可视化问答模型性能的指标,但所有指标都存在优势和劣势。研究人员应该根据数据集的特征、数据集中存在的偏差和他们能够承担的费用来选择指标,并在现有工作的基础上更加注意设计更好的指标。
Models
提高性能
- BLOCK模型[13]
双线性模型是在线性模型基础上的扩展,它支持两种输入,是目前最流行的方法之一。然而,当输入维度急剧增长时,由于输入参数的数量翻倍,学习变得困难。
BLOCK的思想是将原始输入分解成更小的块项block-terms,这些块项只包含原始输入的一小部分,以减少参数的数量。然后,将块项block-terms与块超对角张量参数化的融合进行合并。块项block-terms可以广泛应用于现有的VQA模型。
在实际应用中,BLOCK模型在时间复杂度和精度方面均优于MCB[49]、MFB[50]和MFH[51]等已有模型。此外,BLOCK模型在VRD领域也有较好的性能。 - 网格特征方法[14]
在VQA领域,众所周知的**自底向上注意力机制 bottom-up attention **已经超越了传统的基于网格的卷积特征,但区域的贡献度仍不确定。
网格特征方法旨在将区域特征转换为网格。具体来说,在Faster R-CNN模型中,我们没有使用1414 RoIPool-ed的特征,而是使用了11 RoIPool,它将三维张量分解为单个向量。此外,为了使预先训练的卷积层对输入的变化仍然有效,只保留ResNet[52] C5 以下的部分。
在实践中,使用默认情况下在ImageNet上预训练的ResNet-50 backbone的Faster R-CNN和使用Pythia[53,54]实现的联合注意力模型作为设置。与使用广泛的自底向上区域特征的模型相比,改进后的网格特征模型具有更高的精度和更少的时间消耗。 - Differential Adaptive Computation Time差分自适应计算时间[55]
差分自适应计算时间(DACT)是一种新兴的基于注意力的算法,它实现了端到端可微的特性。为了实现这些特性,模型的需求被限制在那些可以分解成一系列子模型的需求上。与一般过程不同的是,对于每个子模型,为了防止后续模型改变答案的影响,在目标输出的同时,还输出sigmoidal output,并根据sigmoidal output计算概率。然后,通过“概率惩罚”将前一子模型的输出与当前子模型的输出相结合,得到每个累积子输出。递归地,在最后的子模型中观察最终输出。
在实际应用中,DACT应用于CLEVR数据集。与MAC网络相比,DACT模型在计算成本相近的情况下优于MAC网络。然而,这样的性能只在12次迭代中保持。此外,当问题相对简单时,DACT迭代的次数要少得多,而在其他情况下则要多。
提高预测准确率
-
PLAC model [56]
近年来VQA研究的大部分进展都是基于rnn的,值得关注。虽然取得了显著的成功,但长期消耗仍然是一个问题,而且由于RNN模型的性质,建模长期依赖关系的困难仍然没有得到解决。
带协同注意力的位置自注意力(PLAC)模型的新思想有助于提高计算效率和获得长期依赖关系。PLAC模型由基于视频的位置自注意力块(VPSA)、基于**问题的位置自注意力块(QPSA)和基于视频问题的位置自注意力块(VQ-Co)**三个关键部分组成。VPSA和QPSA分别进行视频预处理和问题预处理。
因此,VPSA获得帧特征,QPSA获得词级和字符级特征。最后,利用VQ-Co提高答题效率。在实践中,PLAC模型提高了高级概念词检测器的性能,生成了一个概念词列表。 -
VQA中的对抗性学习[57]
在过去的几年中,提高VQA准确率的重点是在模型层面;换句话说,减少学习中的偏见是目标。对于VQA中数据增强问题的研究缺失,可能会阻碍VQA的进一步发展。
最近研究的针对VQA问题的对抗学习的目标是在输入中加入最少的例子以达到期望的错误分类。为了避免答案的影响,只对原始输入(图像和答案)进行操作。在处理图像时,使用IFGSM[11],这可能会产生有害的对抗示例。考虑到破坏语法和语义的风险,改述模型[12]应用于文本输入。然后将这些对抗样本作为训练样本,用损失函数进行训练,以控制对抗样本的相对权重。 -
TRRNet Model [58]
TRRNet模型是一个遵循一般VQA训练过程的基于注意力的模型。模型由TRR单元连接,TRR单元由四个部分组成:根注意力root attention、根对留注意力传递root to leave attention passing、叶注意力leaf attention和消息传递模块message passing module。
首先利用图像特征集、边界框特征集和问题特征集生成root attention,生成基于语言的对象层面视觉特征注意映射,生成融合的视觉特征。
然后在到叶注意的传递处处理从root attention到leaf attention的输出,生成两两关系,其中涉及到多头硬注意[59],以选择相关对象。
然后,利用 leaf attention 对前面的对象关系推理进行处理,得到一个注意力映射和一个合并的关系特征。
最后,在消息传递模块中,融合了上一步中的关系特征和root attentions 中的对象层面特征。
读出层Readout layer将有助于生成最终答案。
在实践中,该模型应用于GQA[60]、VQAv2和CLEVR数据集,并预先训练了fast - rcnn、Bert词嵌入和GRU。与基本的注意模型相比,TRRNet模型在强注意力模型和弱注意力模型下都表现更好,Y/N问题的准确性有显著提高。
降低 Bias
- RUBi学习策略[61]
尽管VQA近年来取得了很大进展,但不使用图像信息而提供正确答案的单模态偏差一直是一个问题。当评估与训练过的数据集不同的数据集时,这种偏差可能会导致模型的性能下降。
受纯问题模型启发的RUBi学习策略有助于减少VQA模型中的偏差。
与传统的直接合并两种输入模式的方法不同,RUBi学习策略只采用两种输入模式中的一种作为输入,并采用了只针对问题的分支来捕获问题偏差。然后,来自纯问题分支的输出将与一个掩码合并,以平衡答案的得分。因此,对于有偏差的例子,损失会降低。
在实践中,与VQA-CP v2数据集上的其他相对传统模型(如UpDn[62]、MuRel)相比,采用RUBi学习策略训练的Bilinear BLOCK融合体系结构提高了平均总体精度,降低了标准差。 - VCTREE Model [63]
除了传统的基于rnn的训练模型外,基于tree的模型也对VQA任务的领域做出了贡献。VCTREE的提议在解释对象之间的并行和层次关系以及允许对象之间传递特定于任务的消息方面具有显著的优势。
VCTREE模型包括四个关键步骤。
首先利用fast - rcnn对视觉特征进行检测。
然后,利用对象对之间的近似任务依赖有效性的可学习矩阵构建VCTREE,并进一步利用双树LSTM对上下文线索进行编码。
最后,通过VQA模型对编码后的上下文进行解码。
在实践中,VCTREE在VQA 2.0数据集上的性能要优于之前发现的其他方法(例如Count、MLB)。然而,当数据集包含偏差时,模型产生的错误率仍然是未来需要解决的问题。 - Visually-Grounded Question Encoder [64] 基于视觉的问题编码器VGQE
VGQE源自于VQA中采用的基于RNN的问题编码方案,折衷了VGW (visual - grounded Word)嵌入部分和传统的RNN单元两部分。在VGW阶段,它预先进行问题的词嵌入,找到对应的图像的相关视觉特征,生成一个基于视觉的问题词嵌入向量。然后,将输出的向量送入RNN中,进一步对序列信息进行编码。在实践中,VGQE与VQA-CPv2中最先进的偏置减少技术进行了测试。总体的准确性,特别是在涉及基于数字的答案的问题中,与RUBi模型的结果类似。 - Counterfactual Samples Synthesizing Training
Scheme 反事实样本综合训练方案[65] CSS
CSS训练方案折衷了三个步骤:用原始模型训练VQA模型,生成反事实样本,再用反事实样本训练模型VQA模型。
生成反事实样本需要两个步骤:
(1)使用V-CSS或Q-CSS[65]计算每个对象特征对GT答案的贡献;
(2)利用CO_SEL和DA_ASS[65]将反事实的视觉输入与原始问题相结合,生成反事实样本。
在实践中,CSS训练方案应用于模型为UpDn[66]、PoE[23]、RUBi[61]和LMH的VQA-CP数据集。结果表明,四种模型的精度均有明显提高。当将该方法应用于模型为LMH的VQA-CP v1数据集时,可以得到类似且更显著的结果。
应用
ROLL
模型ROLL的灵感来自于人类通过电影故事情节不断推理交流和行动的行为,旨在利用对话理解、场景推理和故事情节回忆的任务,通过访问外部资源来检索上下文信息。
Location Aware Graph Convolution Network 位置感知图卷积网络
ISVQA[9]
总结
综上所述,本文回顾了2018年以后的数据集、度量和模型,发现VQA的研究范围已经从静态的、离散的图像扩展到动态的、连续的视频,甚至360度的图片和科学图表也得到了研究者的探索。同时,模型的推理能力也引起了研究者的关注。
虽然VQA工作取得了一定的成效,但仍存在一些问题。首先,语言先验对视觉问题的回答仍有负面影响。此外,统计偏差很难减少。此外,对于不同类型的问题,现有的指标是不充分的。此外,多模态融合机制还有待完善。视觉答题仍然是一个值得探索的领域。