在进行正式开始爬虫之旅前,我们要认识几个Python库:
- urllib2:Python标准库,该库中提供了一系列针对url的操作方法
- re:Python标准库,提供了一系列针对字符串匹配的方法
- BeautifulSoup4:最主要的功能是从网页抓取数据(可以通过pip install BeautifulSoup4安装)
接下来,就可以开始愉快的爬虫了~~
首先,我们先获取要爬取的网页:
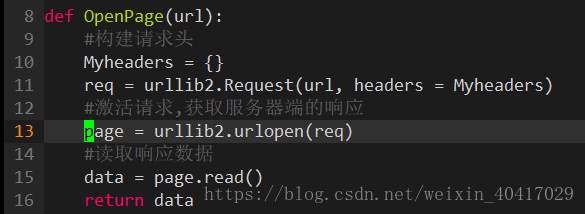
将结果打印出来或者直接在网页上,分析爬取的页面:
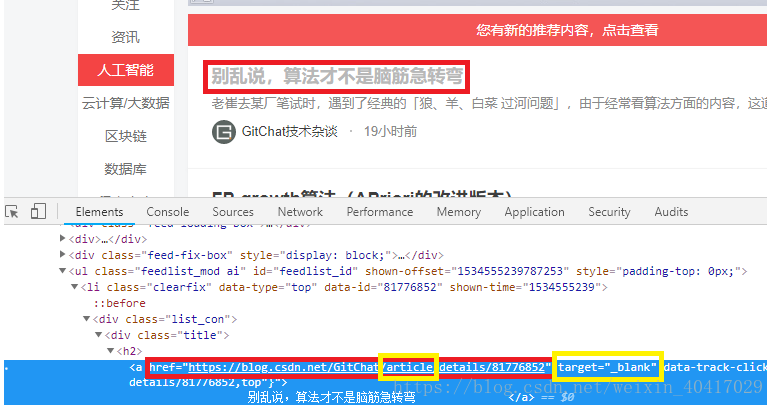
发现每一篇文章的链接中都有article字段,并且target=“_blank”,根据以上特点,分析该页面,获取到每一篇文章的地址:

将获取到的结果打印出来:

接下来,就是想办法获取每篇文章的标题和内容了,打开一篇文章,一样是分析页面:

发现,每一篇文章的标题都在class=“title-article”的标签中,文章内容都在article标签中,所以根据每一篇文章的url构造Beautiful Soup对象,然后使用该对象的find_all方法查找符合条件的内容,就是我们要的结果了!

使用一个url测试:

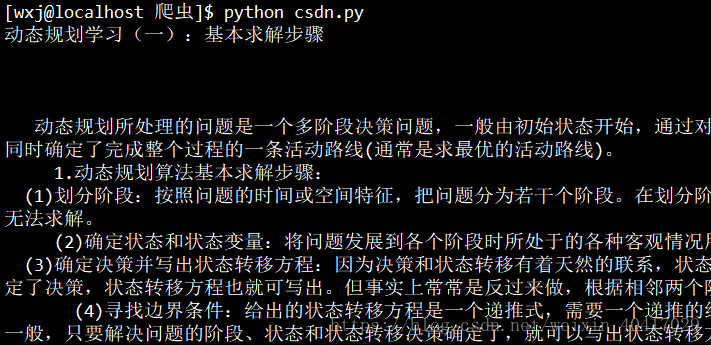
成功打印出了我们想要的内容。接下来将获取到的文章保存到文件中,每一篇文章都存入一个TXT文件

可以看到,爬取文章成功了~~~^-^
