相对今上午的面试,本次面试一上来就是一波三折,各种视频电话各种无法接通,后来终于接通了,感觉面试官的语气就很不耐烦,反正感觉心情很糟糕,一种爱面不面的口气。。。。。。整个面试过程持续了15分钟,整个面试过程感觉相当被动,让我有种有劲发不出来的感觉,算了,不说了,还是说说面试题吧。
1、你都遇到过哪些反爬虫措施?
这里就不列举我实际遇到的了,简单陈述一下实际开发过程中常见的发爬虫措施:
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度
1)、通过Headers反爬虫。从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。
解决措施:如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
2)、基于用户行为反爬虫。还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作
解决措施:(代理IP池)
对于第一种情况,使用IP代理就可以解决。可以专门写一个爬虫,爬取网上公开的代理ip,检测后全部保存起来。这样的代理ip爬虫经常会用到,最好自己准备一个。有了大量代理ip后可以每请求几次更换一个ip,这在requests或者urllib2中很容易做到,这样就能很容易的绕过第一种反爬虫。
对于第二种情况,可以在每次请求后随机间隔几秒再进行下一次请求。有些有逻辑漏洞的网站,可以通过请求几次,退出登录,重新登录,继续请求来绕过同一账号短时间内不能多次进行相同请求的限制
3)、动态页面的反爬虫。我们需要爬取的数据是通过ajax请求得到,或者通过JavaScript生成的。
解决措施:
首先用Firebug或者HttpFox对网络请求进行分析。如果能够找到ajax请求,也能分析出具体的参数和响应的具体含义,我们就能采用上面的方法,直接利用requests或者urllib2模拟ajax请求,对响应的json进行分析得到需要的数据。
能够直接模拟ajax请求获取数据固然是极好的,但是有些网站把ajax请求的所有参数全部加密了。我们根本没办法构造自己所需要的数据的请求。遇到这样的网站,可以采用selenium+phantomJS框架,调用浏览器内核,并利用phantomJS执行js来模拟人为操作以及触发页面中的js脚本。从填写表单到点击按钮再到滚动页面,全部都可以模拟,不考虑具体的请求和响应过程,只是完完整整的把人浏览页面获取数据的过程模拟一遍。
利用 selenium+phantomJS能干很多事情,例如识别点触式(12306)或者滑动式的验证码,对页面表单进行暴力破解等等。它在自动化渗透中还 会大展身手,以后还会提到这个。
2、你在做12306过程中都用到了那些库?用什么库进行的网页解析。。。
re/ lxml/ beautifulsoup/
3、你在做“TB数据爬虫分析可视化”的过程中,用到了那些库?
这个问题就不做阐述了!
4、简单解释一下scrapy框架的执行流程?
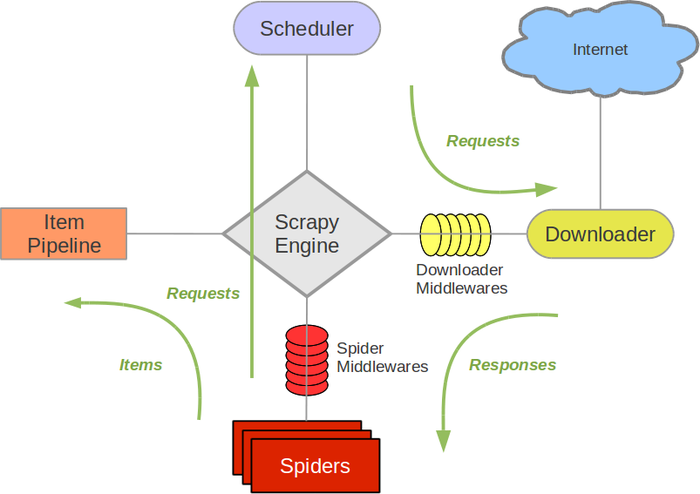
首先是spider产生request并发送request,之后scrapyEngine将请求交给Schedule进行入队列,调度器将队列中请求按照先进先出的原则交给Downloader下载指定的网页,获取的response交给Spiders进行网页解析,解析完之后,如果是request,就将其交给Scheduler,如果是items,就交给Item Pipeline进行数据的存储和进一步处理。
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
5、scrapy框架和requests库在爬虫方面的不同点?
requests 是库,主要是构造网络请求,获取网页内容,后续的解析、存储都要另行解决。 scrapy 是框架,可以说是爬虫的打包方案,除了上述构造请求、拿内容、解析、存储外,还可以做分布式爬虫,挂代理,等等一大堆功能。
区别就是,假如是要做一个特别复杂的爬虫,可以用 scrapy。假如是临时小需求,可能学会配置 scrapy 的时间,已经足够用 requests 抓完数据了。换句话说就是scrapy的效率要远高于request的效率。
(区别不仅仅这些,还有待补充。。。。。)
6、如果用scrapy框架进行爬取数据,中途突然中断了,如何实现对已经爬取过的网址进行去重?
参考该文章:Python进阶之爬虫url去重
7、你遇到过哪些验证码问题?如何解决的?
8、既然你的项目没有实际用TB级数据进行测试,那你认为
对于这个项目来说?
9、你还有什么问我的?
。。。。。。具体的解析先不写了,之后马上更新。。。先去准备笔试了。。。。