之前三个爬取示例:都是简单爬取(直接将网络请求到的内容反馈出来),没有用到正则表达式;本文我们学习如何使用正则表达式。
学习链接:Python正则表达式|菜鸟教程
一、re正则表达式
(一)常用符号
| 常用符号 | 点号,星号,问号与括号(小括号) |
|---|---|
. |
匹配任意字符,换行符\n除外 |
* |
匹配前一个字符0次或无限次 |
? |
匹配前一个字符0次或1次 |
.* |
贪心算法 |
.*? |
非贪心算法 |
() |
括号内的数据作为结果返回 |
常用符号 举例:
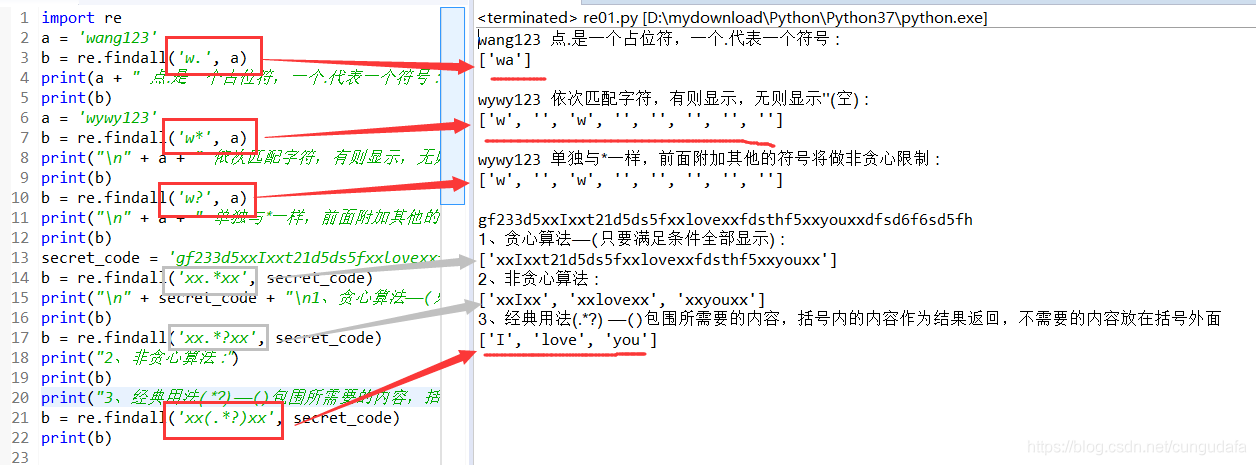
源码:
import re
a = 'wang123'
b = re.findall('w.', a)
print(a + " 点.是一个占位符,一个.代表一个符号 :")
print(b)
a = 'wywy123'
b = re.findall('w*', a)
print("\n" + a + " 依次匹配字符,有则显示,无则显示''(空) :")
print(b)
b = re.findall('w?', a)
print("\n" + a + " 单独与*一样,前面附加其他的符号将做非贪心限制 :")
print(b)
secret_code = 'gf233d5xxIxxt21d5ds5fxxlovexxfdsthf5xxyouxxdfsd6f6sd5fh'
b = re.findall('xx.*xx', secret_code)
print("\n" + secret_code + "\n1、贪心算法——(只要满足条件全部显示) :")
print(b)
b = re.findall('xx.*?xx', secret_code)
print("2、非贪心算法 :")
print(b)
print("3、经典用法(.*?) ——()包围所需要的内容,括号内的内容作为结果返回,不需要的内容放在括号外面")
b = re.findall('xx(.*?)xx', secret_code)
print(b)
\s : 匹配空格符
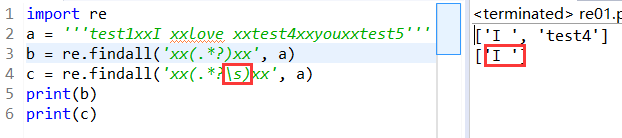
import re
a = '''test1xxI xxlove xxtest4xxyouxxtest5'''
b = re.findall('xx(.*?)xx', a)
c = re.findall('xx(.*?\s)xx', a)
print(b)
print(c)
\d+ : 匹配纯数字
举例:

源码:
import re
a = '''test1xxIxxlovexxtest4xxyouxxtest5'''
b = re.findall('(\d+)', a)
print(b)
re.S :让.匹配所有行,包括了换行符(以\n的形式出现)
举例:
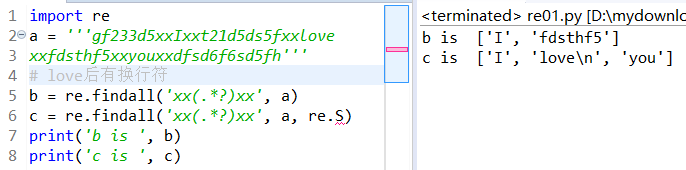
源码:
import re
a = '''gf233d5xxIxxt21d5ds5fxxlove
xxfdsthf5xxyouxxdfsd6f6sd5fh'''
# love后有换行符
b = re.findall('xx(.*?)xx', a)
c = re.findall('xx(.*?)xx', a, re.S)
print('b is ', b)
print('c is ', c)
更多(略)
(二)常用方法
| 常用方法 | findall, search, sub |
|---|---|
| findall | 匹配所有符合规律的内容,返回包含结果的列表 |
| search | 匹配并提取第一个规律的内容,返回一个正则表达式对象(object) |
| sub | 替换符合规律的内容,返回替换后的值 |
常用方法 举例:
findall:(每一个匹配项为第一级列表,括号为二级列表)
举例:

源码:
import re
a = '''test1xxIxxlovexxtest4xxyouxxtest5'''
f2 = re.findall('xx(.*?)xx(.*?)xx', a, re.S)
print(f2[0][1])
search:(group是按括号顺序匹配)
search 找到一个后返回,不继续,客大大提高效率
findall遍历全部,找到尽可能多的项
举例:
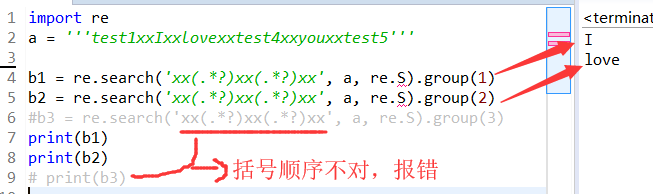
源码:
import re
a = '''test1xxIxxlovexxtest4xxyouxxtest5'''
b1 = re.search('xx(.*?)xx(.*?)xx', a, re.S).group(1)
b2 = re.search('xx(.*?)xx(.*?)xx', a, re.S).group(2)
#b3 = re.search('xx(.*?)xx(.*?)xx', a, re.S).group(3)
print(b1)
print(b2)
# print(b3)
sub:(sub将符合条件的()内内容提换)
举例:

源码:
import re
a = '''test1xxIxxlovexxtest4xxyouxxtest5'''
output = re.sub('xx(.*?)xx', '666', a)
print(output)
二、实战
(一)分析网页结构
进入我的博客:https://blog.csdn.net/cungudafa
按F12打开程序猿开发工具,进入Elements可以看到整篇网页信息:

找到文章列表模块红框所示,最新一章博客结构蓝框所示:
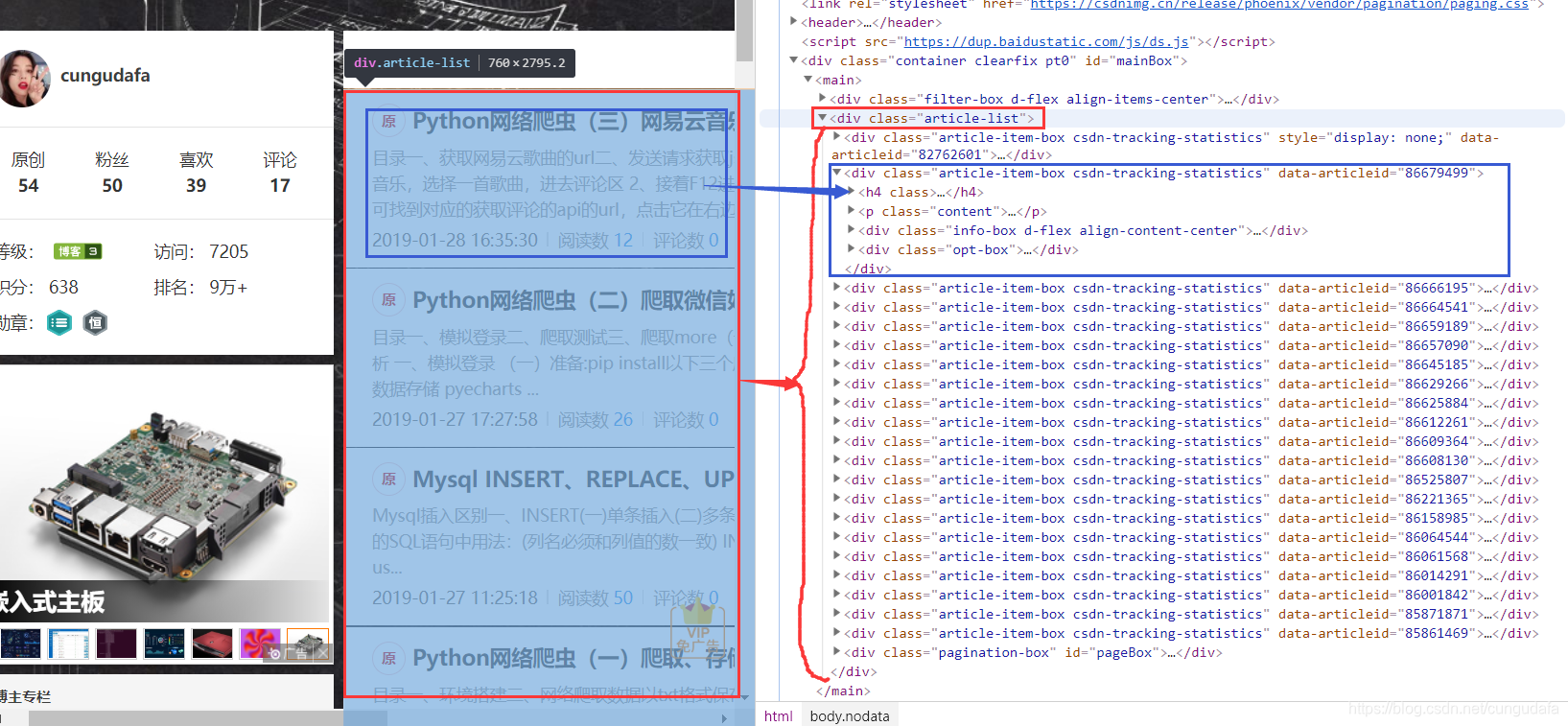
打开蓝框,可以发现结构部署:
| 结构 | 内容 |
|---|---|
| 标题 title | 文章链接;文章类型(原、转);文章名称 |
| 内容content | 文章链接;文章前部分内容 |
| 博客标签indo-box | 发布时间、阅读数、评论数 |
| 操作opt-box | 编辑、删除、置顶等(陌生人访问时,没有这一项) |

(二)爬取CSDN博客Demo
1. 获取全部html
(写入到同目录text.txt中)
# -*- coding:UTF-8 -*-
import requests
def main():
target = 'https://blog.csdn.net/cungudafa'
req = requests.get(url=target)
try:
# 读写文件
with open('text.txt', 'a+', encoding='utf-8') as f:
f.write(str(req.text)) # 记录
print("成功")
except Exception as e:
print("失败")
if __name__ == '__main__':
main()
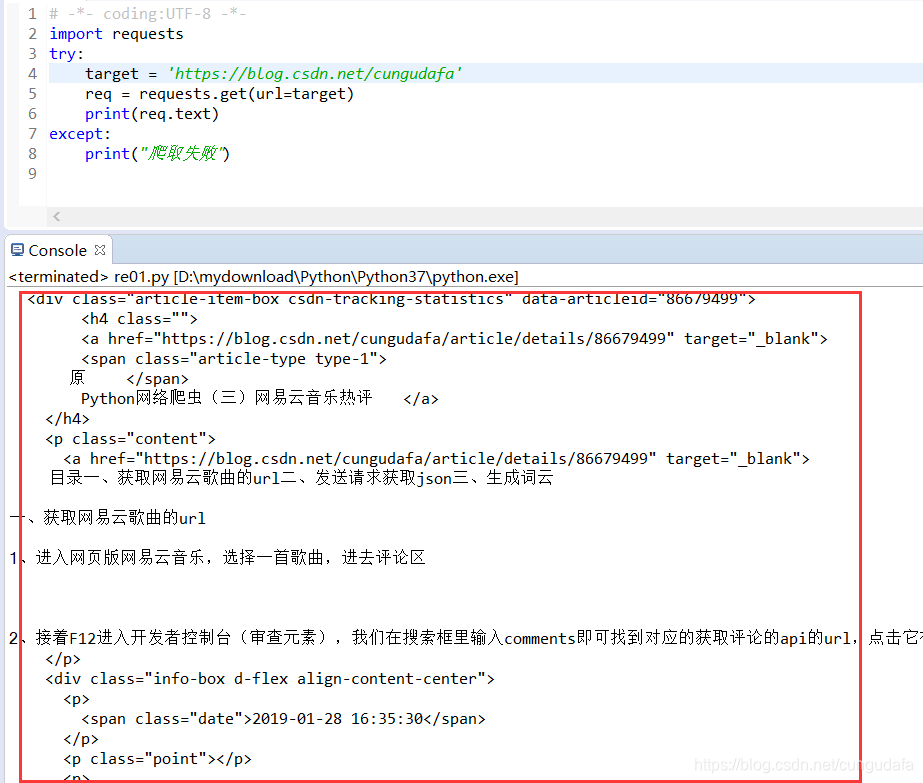
2. 匹配正则表达式
1、
根据txt文档找出正则表达式匹配的语句:(这一步最重要!!!!)
2、然后匹配打印输出就行
举例:打印出博客链接
1、 根据txt文档找出正则表达式匹配的语句:(图中为博客链接位置所在!!!!)
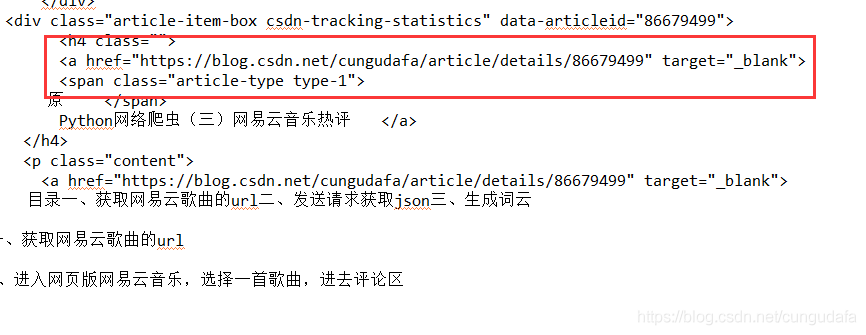
2、打印效果:
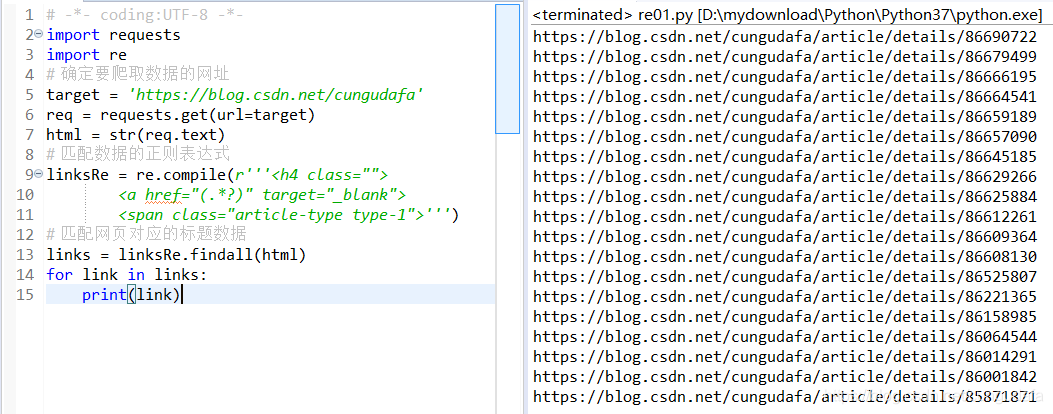
源码:
# -*- coding:UTF-8 -*-
import requests
import re
# 确定要爬取数据的网址
target = 'https://blog.csdn.net/cungudafa'
req = requests.get(url=target)
html = str(req.text)
# 匹配数据的正则表达式
linksRe = re.compile(r'''<h4 class="">
<a href="(.*?)" target="_blank">
<span class="article-type type-1">''')
# 匹配网页对应的标题数据
links = linksRe.findall(html)
for link in links:
print(link)
3. more

全部源码:
# -*- coding:UTF-8 -*-
import requests
import re
def getdata(i):
# 确定要爬取数据的网址
target = 'https://blog.csdn.net/cungudafa'
req = requests.get(url=target)
html = str(req.text)
# 匹配数据的正则表达式
linksRe = re.compile(r'''<h4 class="">
<a href="(.*?)" target="_blank">
<span class="article-type type-1">''')
titleRe = re.compile(r'''<span class="article-type type-1">
原 </span>
(.*?) </a>
</h4>''')
timeRe = re.compile(r'''<span class="date">(.*?)</span>''')
readnumsRe = re.compile(r'''<p class="point"></p>
<p>
<span class="read-num">(.*?) <span class="num">(.*?)</span> </span>
</p>''')
# 匹配网页对应的标题数据
links = linksRe.findall(html)
titles = titleRe.findall(html)
time = timeRe.findall(html)
readnums = readnumsRe.findall(html)
# 打印格式
print("---------------------------------")
print("标题: " + titles[i])
print("发布时间:" + time[i])
print("博客链接: " + links[i])
print(str(readnums[i]))
if __name__ == '__main__':
for i in range(1, 10): # 打印10条
getdata(i)