抓取面筋哥的视频弹幕,在哔哩哔哩搜索'面筋哥',随便进入一个结果:
视频链接: https://www.bilibili.com/video/av21037939?from=search&seid=1951415484277324635
第一步:找到弹幕的链接

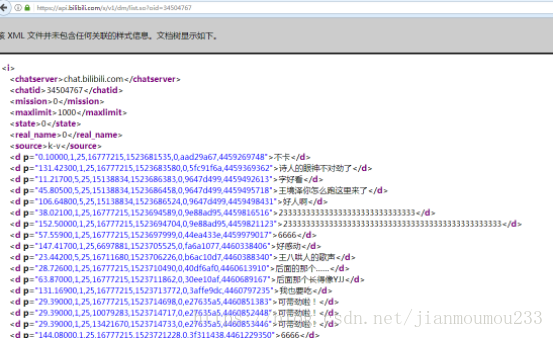
第二步:打开链接:
https://api.bilibili.com/x/v1/dm/list.so?oid=34504767
第三步:撸代码:
# coding: utf-8
from parsel import Selector
import requests
def get(url):
headers = {
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0"
}
body = requests.get(url, headers=headers).content
# 我擦, 居然出现乱码;
xbody = Selector(text=str(body, encoding='utf-8'))
lists = xbody.xpath("//d")
count = xbody.xpath("//maxlimit/text()").extract_first()
print("共有%s条弹幕" % count)
for li in lists:
content = li.xpath("./text()").extract_first()
par = li.xpath("./@p").extract_first()
print(content, ":::::", par)
if __name__ == '__main__':
url = "https://api.bilibili.com/x/v1/dm/list.so?oid=34504767"
get(url)
结果:
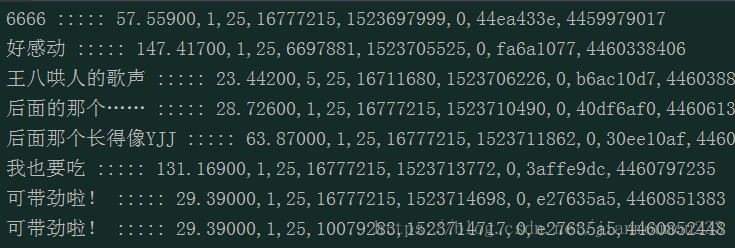
数字的含义,我也不懂 就知道一个时间戳和 一个用户名;其他的自行查找