requests+bs4模块–简单的爬虫实例–哔哩哔哩专栏图片篇
文章目录
section1:声明
1、所爬取的图片均为能在哔哩哔哩平台免费下载的图片。
2、自己的学习笔记,不会商用,我自己爬取了2个g的图片后,选了几张作为备用壁纸后,已全部删除。
3、本文如有侵权,可联系我删除文章。
section2:下载链接分析
由于B站专栏很多,我进行搜索了一下,选择“鬼灭之刃弥豆子壁纸”,然后总共有4页,本文只爬取第一页内容。
效果图如下:
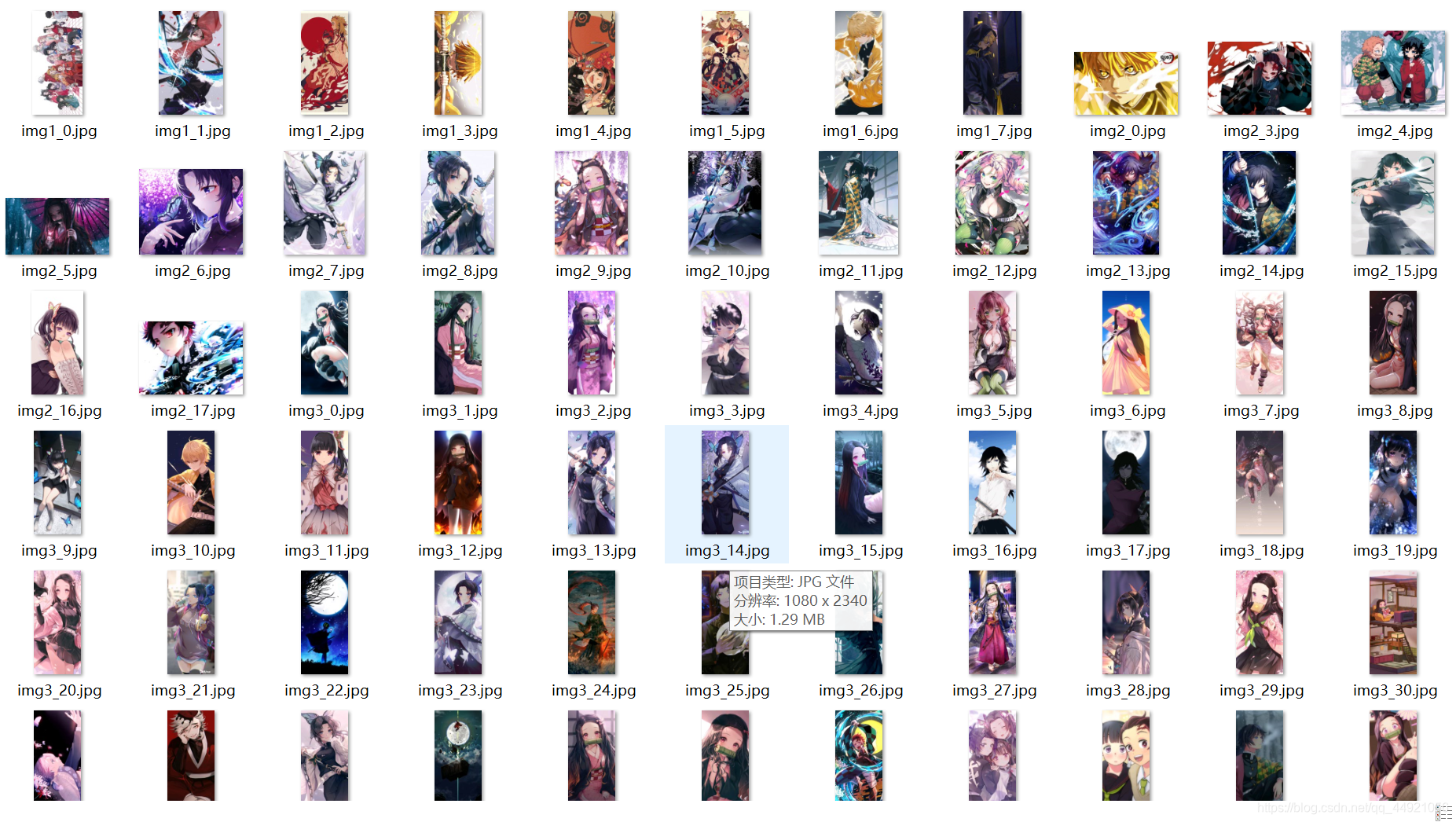

首先,找到我们想要爬取的详情页 鬼灭之刃弥豆子壁纸
然后进行源代码分析:
(以第一篇文章为例)

找到href标签处的超链接,点击查看一下
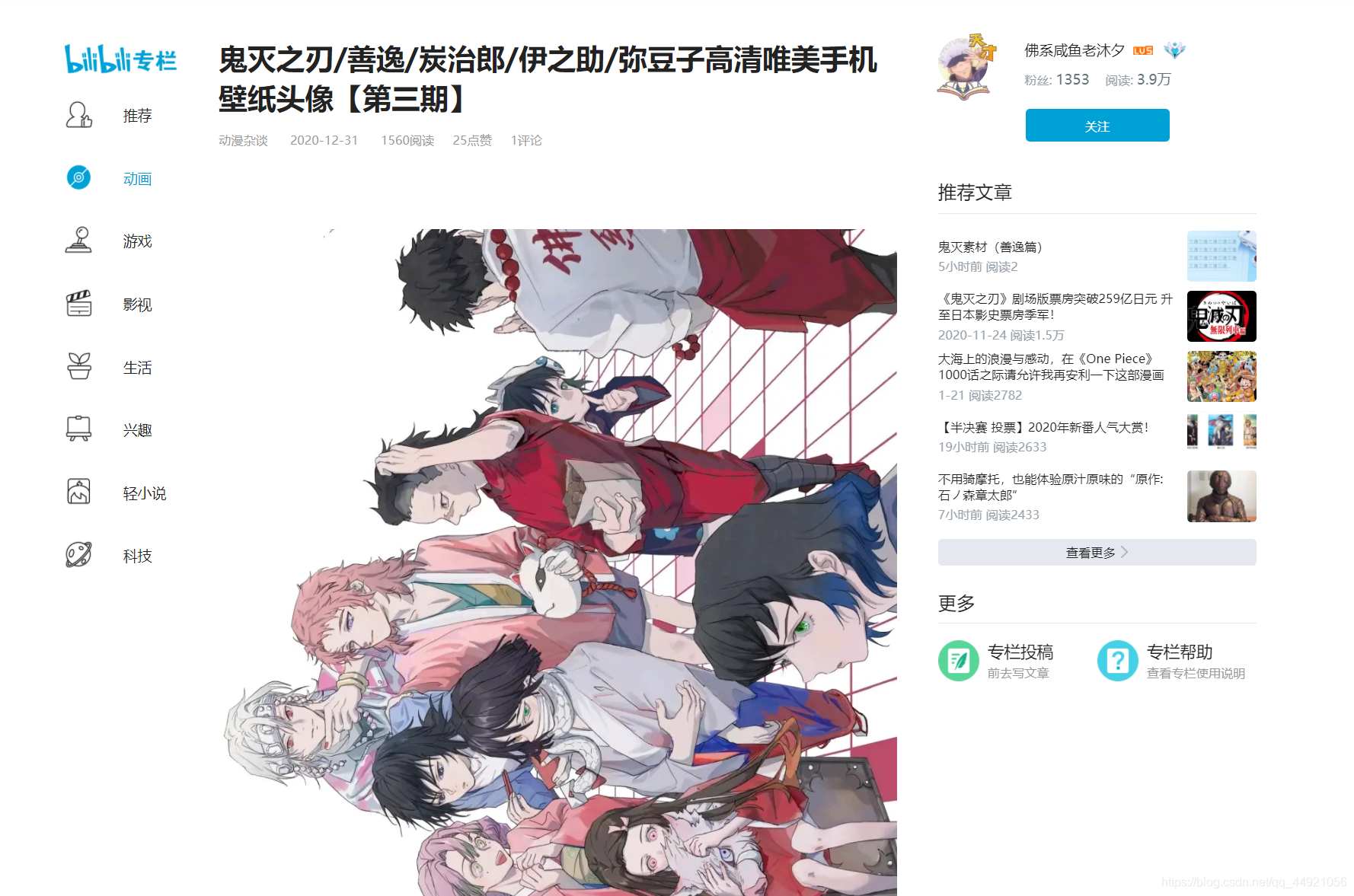
是我们想要的文章。但是爬取的时候需要和**“https:”**组合一下。
接着对文章中出现的图片进行源代码分析:
(以第一张图片为例)

每一个figure标签,含有一张图片的URL。那么提取处data-src的内容即可。(但实际上并不是,用代码获取文本的时候,是没有这个内容的,后面可以看一下)
section3:代码编写
1、导入板块
import requests
import re
import bs4
import os
2、加一个请求头
headers = {
'user - agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.116Safari / 537.36'
}
3、创建文件夹
if not os.path.exists('D:/鬼灭之刃'):
os.mkdir('D:/鬼灭之刃')
4、封装函数
def get_first_url(url): #得到第一个url,即每一篇文章的url,结果是未遍历的
res_1=requests.get(url=url,headers=headers)
html_1=res_1.text
first_url=re.findall('<li.*?<a.*?"(//w.*?search)"',html_1,re.S)
return first_url
这个函数的作用是对一开始访问的详情页进行分析,提取出能构成文章链接的内容
(是用正则表达式提取的)
我之前也写过一篇关于正则表达式的文章嗷
def get_second_url(url): #得到第二个url,即文章中每个图片的url,结果是未遍历的
res_2 = requests.get(url=url,headers=headers)
html_2=res_2.text
soup=bs4.BeautifulSoup(html_2,'html.parser')
picture_list = soup.select('.img-box img')
return picture_list
这个函数的作用是对文章内容进行分析,提取出能构成图片链接的内容
(使用bs4提取的)
def download_picture(url,num1,i): #下载图片
res_3=requests.get(url=url,headers=headers)
picture_data=res_3.content
picture_name='img{}_{}.jpg'.format(num1,i)
picture_path='D:/鬼灭之刃/'+picture_name
with open(picture_path,'wb') as f:
f.write(picture_data)
print(picture_path,'打印成功')
这个函数的作用是下载图片,并打印进度条
(我喜欢先写main函数,然后补充这个函数)
def main():
base_url='https://search.bilibili.com/article?keyword=%E9%AC%BC%E7%81%AD%E4%B9%8B%E5%88%83%E5%BC%A5%E8%B1%86%E5%AD%90%E5%A3%81%E7%BA%B8'
fist_urls=get_first_url(base_url)
num1=1
for first_url in fist_urls:
first_url='https:'+first_url
second_url=get_second_url(first_url)
for i in range(len(second_url)):
picture_urls=second_url[i].get('data-src')
picture_url='https:'+picture_urls
download_picture(picture_url,num1,i)
num1+=1
5、完整代码
import requests
import re
import bs4
import os
headers = {
'user - agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.116Safari / 537.36'
}
#创建文件夹
if not os.path.exists('D:/鬼灭之刃'):
os.mkdir('D:/鬼灭之刃')
def get_first_url(url): #得到第一个url,即每一篇文章的url,结果是未遍历的
res_1=requests.get(url=url,headers=headers)
html_1=res_1.text
first_url=re.findall('<li.*?<a.*?"(//w.*?search)"',html_1,re.S)
return first_url
def get_second_url(url): #得到第二个url,即文章中每个图片的url,结果是未遍历的
res_2 = requests.get(url=url,headers=headers)
html_2=res_2.text
soup=bs4.BeautifulSoup(html_2,'html.parser')
picture_list = soup.select('.img-box img')
return picture_list
def download_picture(url,num1,i): #下载图片
res_3=requests.get(url=url,headers=headers)
picture_data=res_3.content
picture_name='img{}_{}.jpg'.format(num1,i)
picture_path='D:/鬼灭之刃/'+picture_name
with open(picture_path,'wb') as f:
f.write(picture_data)
print(picture_path,'打印成功')
def main():
base_url='https://search.bilibili.com/article?keyword=%E9%AC%BC%E7%81%AD%E4%B9%8B%E5%88%83%E5%BC%A5%E8%B1%86%E5%AD%90%E5%A3%81%E7%BA%B8'
fist_urls=get_first_url(base_url)
num1=1
for first_url in fist_urls:
first_url='https:'+first_url
second_url=get_second_url(first_url)
for i in range(len(second_url)):
picture_urls=second_url[i].get('data-src')
picture_url='https:'+picture_urls
download_picture(picture_url,num1,i)
num1+=1
if __name__ =='__main__' :
main()
section4:补充
到这里,文本就接近尾声啦,下面来看一下,上面留下来的那个小问题。
这个是解析出来的结果
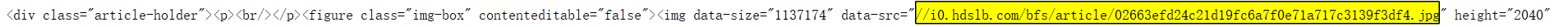
这个是‘检查’网页的结果

仔细看一下是有区别的嗷,还是要以解析出来的结果为准嗷。
section5:参考博文
初次接触bs4,还请多多指教!