运用Python爬虫下载哔哩哔哩上面的视频
前言
之前一直没有时间写博客,从今天开始基本又有时间了,又可以高高兴兴地写博客了。本篇文章纯属于小编原创,未经小编允许禁止转载,还请大家见谅!
目录
1.完成这个项目需要的模块
完成这个项目需要的模块有大家熟悉的requests、bs4、json、urllib.parse 等模块,其中requests模块用于爬取网页数据;bs4模块用于解析爬取的数据,也就是相当于整理数据;urllib.parse模块主要是使用其下urlencode方法,对一个链接的部分信息进行编码;json模块用于处理json数据,也就是字符串数据,只不过处理之后会是字典数据。
2.怎样实现项目
2.1 得到想看的视频资源链接

也就是通过搜索得到内容中,选择一个自己想看的视频资源,得到这个视频资源的链接,我输入的是: python
点击搜索之后,来到的是这个界面:
这个网址为:https://search.bilibili.com/all?keyword=python&from_source=nav_suggest_new
对这个网址进行分析,可以发现基本就是keyword后面就是我刚才输入搜索内容了,只不过需要:urllib.parse.urlencode()进行一下编码,因为输入的是英文,所以编码与没有编码两者之间没有什么区别。
我选择了其中的一个视频资源,也就是第一个,点击进入,就是下面的这个画面了。
代码如下:
def get_url():
# 定有get_url()方法,用于得到读者想下载的视频链接
keyword=input("请输入你想搜索的关键字:")
keyword1=parse.urlencode({'keyword':keyword})
url='https://search.bilibili.com/all?{}'.format(keyword1)
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'}
response=requests.get(url=url,headers=headers)
soup=BeautifulSoup(response.text,'lxml')
urls=soup.select('ul.video-list.clearfix>li>a') # 搜索得到的列表
for i in range(len(urls)):
urls[i]=['https:'+urls[i]['href'],urls[i]['title']]
print('---->【{}】{}'.format(i+1,urls[i][1]))
id=int(input('请输入你想下载的视频序号:'))
return urls[id-1][0] # 视频链接
2.2 得到视频资源下面的所有视频的请求链接
通过多次观察发现,选择不同的视频播放,这个播放链接会改变,并且最终的请求链接也在这个播放链接下面。
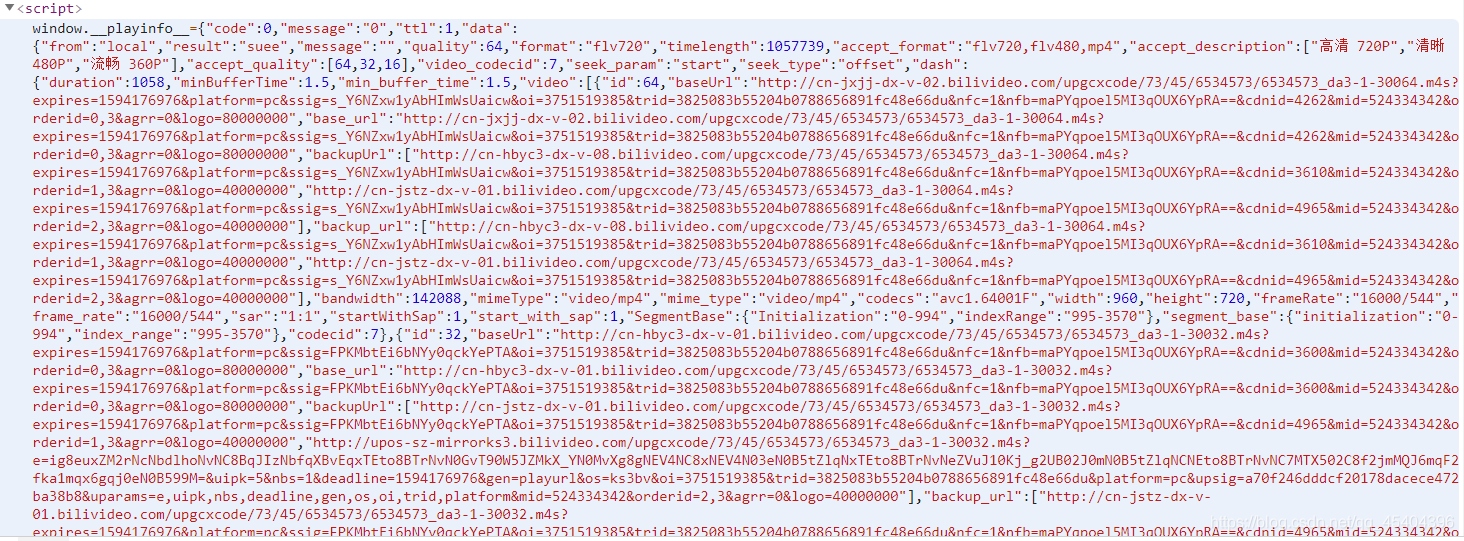
这个视频的请求链接分为三种画质,分别是 高清 720P、清晰 480P 、流畅 360P ,而且音频也分了两种,我对于音频不了解很多,我就选择了第一个,认为第一个应该比较好。

因为视频的画质也是第一个比较好,是 720P 的画质。
我们得到上述视频和音频的请求链接之后,就可以来到接下来的操作了。
代码如下:
def get_info(url):
# 得到所有视频的链接和名称
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'}
response=requests.get(url=url,headers=headers)
soup=BeautifulSoup(response.text,'lxml')
list_1=soup.select('script')
info=str(list_1[3]) # 字符出格式的数据
info=info[info.find('{'):info.rfind('};(function()')+1]
# 将这个字符串的数据转化为字典格式的数据
dicInfo=json.loads(info)
listInfo=dicInfo['videoData']['pages']
listPage=[] # 定义一个存储页码的列表
for i in range(len(listInfo)):
listPage.append(listInfo[i]['page'])
listInfo[i]=listInfo[i]['part'] # 视频的名称
for i in range(len(listPage)):
listPage[i]=url[:url.rfind('?')]+'?p={}'.format(listPage[i])
return listPage,listInfo
def get_info1(listPage):
print('*' * 56)
print('现在是得到所有视频和音频的请求链接的过程!')
# 得到所有视频和音频的请求链接
urlsList=[]
ipsList=get_ips()
# 得到ip
ip = ipsList.pop()
for url in listPage:
page=url[url.find('?p=')+3:]
print('正在爬取页码为{}的数据:'.format(page))
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'}
while(True):
try:
print('正在使用代理的ip:{}'.format(ip))
proxies={'http':ip}
response = requests.get(url=url, headers=headers,proxies=proxies)
if response.status_code==200:
soup = BeautifulSoup(response.text, 'lxml')
list_1 = soup.select('script')
## 视频和音频的网址
info1 = str(list_1[2])
info1 = info1[info1.find('{'):info1.rfind('}') + 1]
info1 = json.loads(info1)
url1 = info1['data']['dash']['video'][0]['baseUrl'] # 视频的请求链接,选择第一个链接的原因是这个视频的清晰度最高
url2 = info1['data']['dash']['audio'][0]['baseUrl'] # 音频的请求链接
urlsList.append([url1, url2,page])
break
# 推出while循环
else:
# 状态码不为200和报错情况下,换一个ip
ip=ipsList.pop()
except Exception as e:
print('ip:{}无效'.format(ip))
ip=ipsList.pop()
return urlsList
2.3 得到视频和音频的下载链接
我们选择其中的一个视频播放,然后按电脑键盘的F12键,点击network,点击xhr,找到下面这个网址,视频或者音频的下载链接就在这个网址下面。
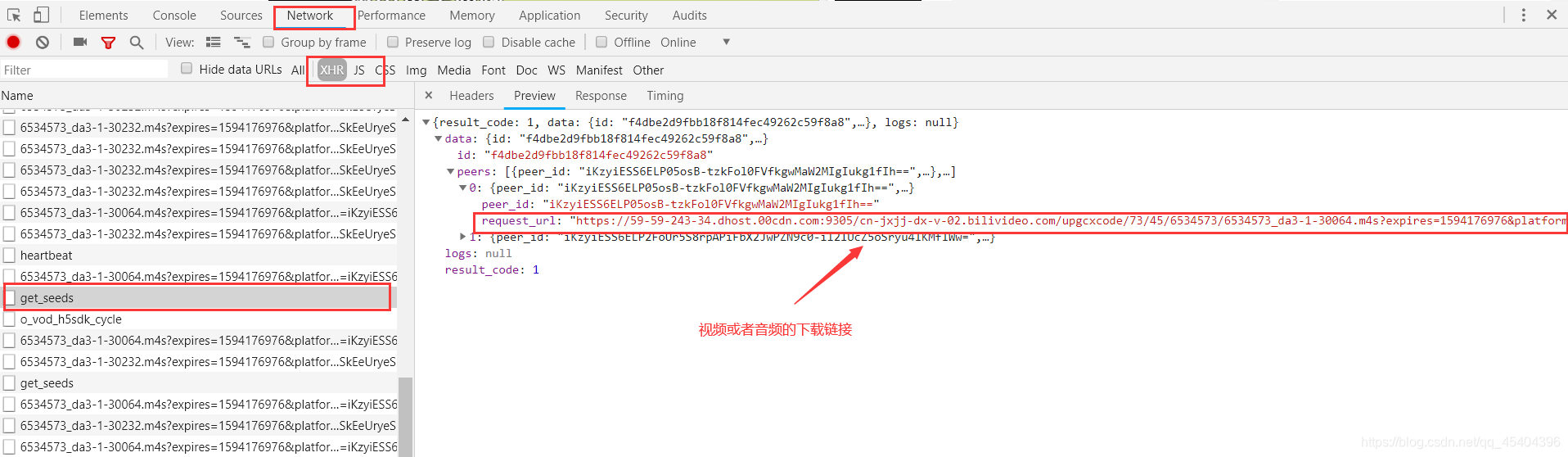
点击headers,看到下面的这个画面
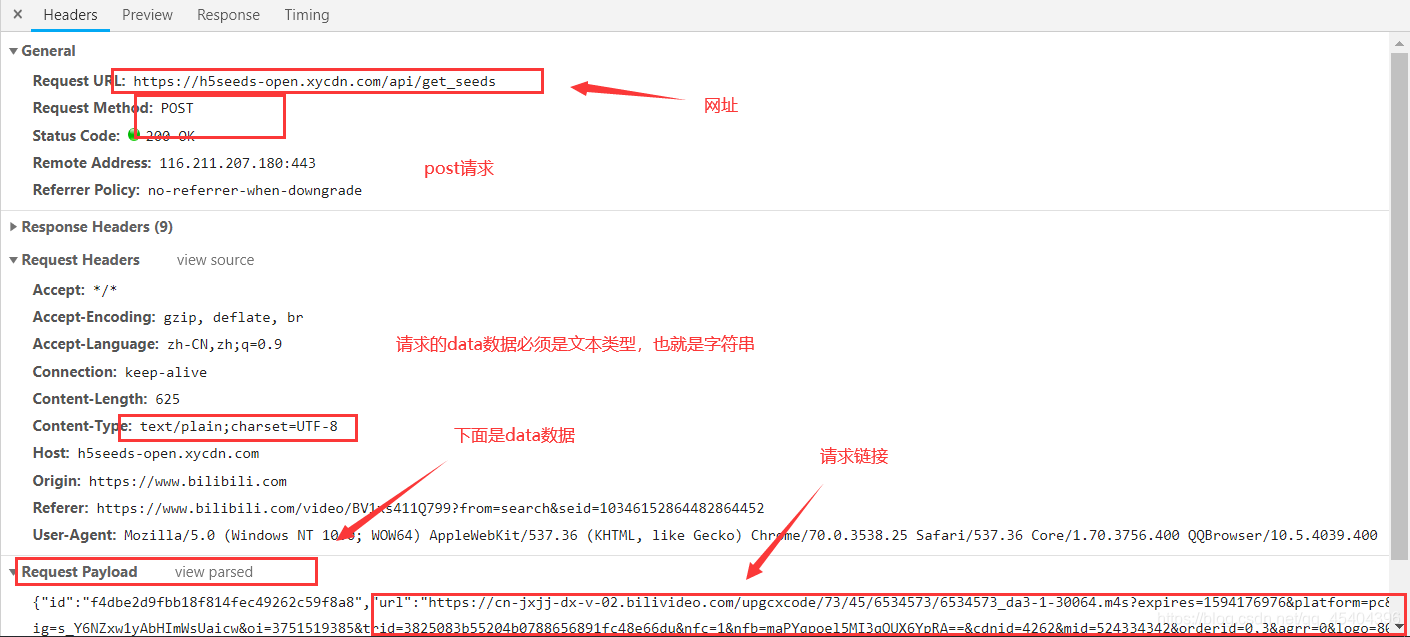
那个请求链接就是上面我所说的请求链接,因为请求的data数据必须是文本类型,所以如果data={字典数据} ,这样是得不到数据的,还必须通过json.dumps() 方法,将字典数据转化成字符串数据才行。
这样我们就得到了视频和音频的下载链接。
代码如下:
def get_info2(urlsList):
print('*'*56)
print('---->现在是得到所有视频和音频下载链接的过程!')
url = 'https://h5seeds-open.xycdn.com/api/get_seeds'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400"}
ipsList=get_ips() # 得到IP
ip=ipsList.pop()
infos=[]
for i in range(len(urlsList)):
proxies={'http':ip}
print('正在使用ip:{}爬取{}页内容'.format(ip,urlsList[i][2]))
while True:
try:
data1={'url':urlsList[i][0]}
response1 = requests.post(url=url, data=json.dumps(data1), headers=headers,proxies=proxies)
data2 = {'url': urlsList[i][1]}
response2 = requests.post(url=url, data=json.dumps(data2), headers=headers, proxies=proxies)
if response1.status_code==200 and response2.status_code==200:
dict1 = json.loads(response1.text)
dict2=json.loads(response2.text)
url_1=dict1['data']['peers'][0]['request_url'] # 视频或者音频的下载链接
url_2 = dict2['data']['peers'][0]['request_url']
infos.append([url_1,url_2,urlsList[i][2]])
break
else:
# 状态码不为200和报错情况下,换一个ip
ip=ipsList.pop()
except Exception as e:
print('错误原因:{}'.format(e))
print('ip:{}无效'.format(ip))
ip = ipsList.pop()
return infos
2.4 下载所有的视频和音频
本来我是打算用上多线程和ip代理的,但是因为速度过快,结果报错了,后面我用上了ip代理,结果大部分代理都没用了,原本很多都可用的,这样的结果用完所有的ip之后,才成功下载了几个视频和音频,运行结果如下:
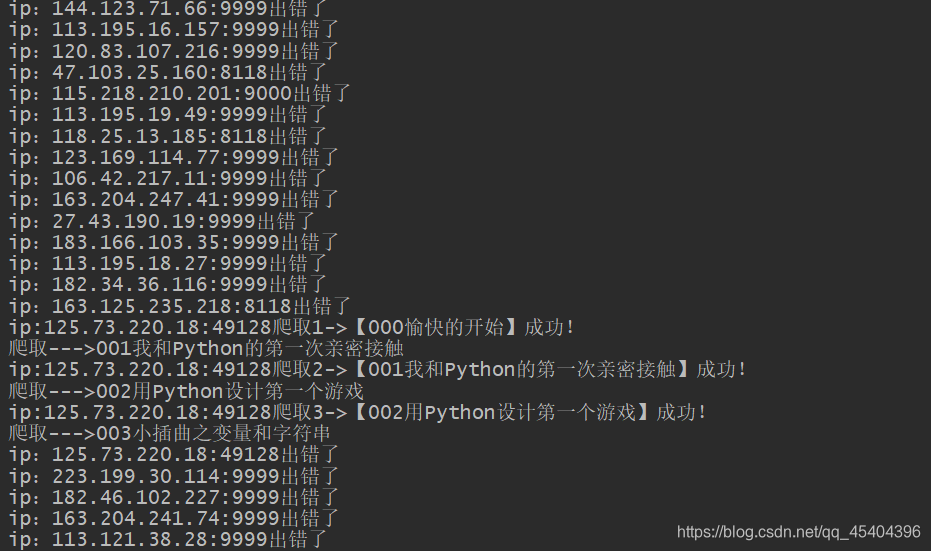

当然,在前面的几个过程当中,我还是应用了ip代理的,代码我已经上传到github了,链接为:ip2.py,另外,也可以看看我的这篇文章,也是讲ip代理的,只不过前面我是爬取 快代理,这里我爬取的是西祠代理。
文章链接为:运用Python做一个ip代理池
这两个程序代码运行完成之后,在同一个文件夹下面会多出一个ip文件,里面就是可用的ip代理了。
最后下载还是不用ip代理了。

3.最终代码和运行结果
代码我已经上传到github上了,链接为:bilibili.py
下载是很慢的,读者可以自行将相应的下载链接得到,然后下载。改动代码如下:
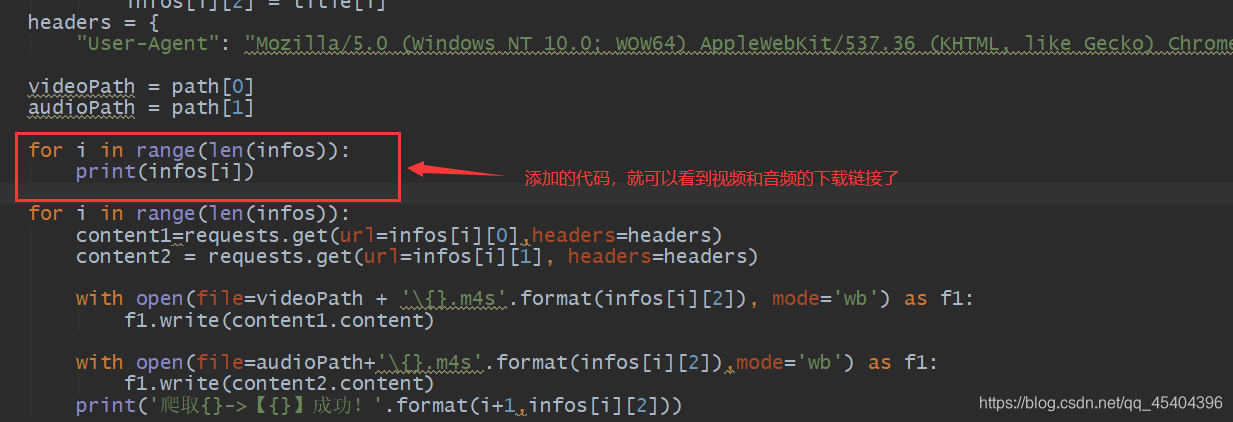 运行结果:
运行结果:
Python爬虫下载哔哩哔哩上面的视频
注意:最好多准备点ip,否则会出错;另外,运行次数过多的情况下,会出现412错误,查了一下资料,才知道,这是headers的错误,最好多准备多个不同的headers,当然,也可以等待一段时间即可。小编没有对视频和音频进行合并,所以如果有需求的读者可以自行查找资料进行合并,当然,如果有读者知道怎样进行合并,欢迎在评论区留言。
4.总结
这个程序代码是小编运行一天时间写的,读者也知道,爬取哔哩哔哩比较繁琐的。当然对于大牛来说,或许太简单了。看了小编这篇文章的读者,如果觉得小编的这篇文章写的还不错,记得点赞,谢谢,如果读者对于小编的这篇文章有什么建议或者疑问,欢迎在评论区留言,或许小编回复的时间不会很准时,希望读者链接。