利用Scikit-Learn对以下数据集进行逻辑回归分析。首先进行特征筛选,特征筛选的方法很多,主要包含在Scikit-Learn的feature-selection库中,比较简单的有通过F检验(f_regression)来给出各个特征的F值和p值,从而可以筛选变量(选择F值大的或者p值小的特征)。其次有递归特征消除(Recursive Feature Elimination, RFE)和稳定性选择(Stability Selection)等比较新的方法。这里使用了稳定性选择方法中的随机逻辑回归进行特征筛选,然后利用筛选后的特征建立逻辑回归模型,输出平均正确率,代码如下:
代码来源: Python数据分析与挖掘实战
#-*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression as LR
from sklearn.linear_model import RandomizedLogisticRegression as RLR
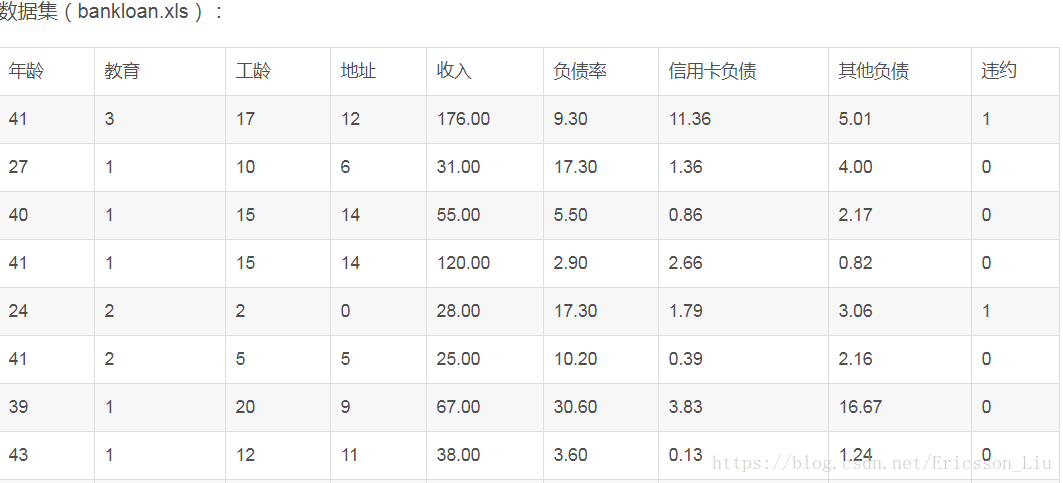
filename = '../data/bankloan.xls'
data = pd.read_excel(filename)
x = data.iloc[:,:8].as_matrix() #自变量;data.iloc[:,:8]取除违约列的数据,官方文档说明as_matrix()方法将会在pandas 0.23.0开始被values()代替,as_matrix()这里将所有记录转换为数组表示
y = data.iloc[:,8].as_matrix() #data[:,8]只取违约列的数据; y在这里做为逻辑回归的因变量,取值只能为0,1
rlr = RLR() #建立随机逻辑回归模型,筛选变量
rlr.fit(x, y) #训练模型
rlr.get_support(indices=True) #获取特征筛选结果:返回为True的索引[2 3 5 6];也可以用.score_方法获取各个特征的分数
print(u'通过随机逻辑回归模型筛选特征结束')
print(u'有效特征为: %s' % ','.join(data.columns[rlr.get_support(indices=True)])) #','.join(...)表示后面的各个元素以逗号分割, data.columns: Index([u'年龄', u'教育', u'工龄', u'地址', u'收入', u'负债率', u'信用卡负债', u'其他负债', u'违约'], dtype='object')
x = data[data.columns[rlr.get_support(indices=True)]].as_matrix() #筛选好特征
lr = LR() #建立逻辑货柜模型
lr.fit(x, y) #用筛选后的特征数据来训练模型
print(u'逻辑回归模型训练结束。')
print(u'模型的平均正确率为: %s' % lr.score(x, y)) #给出模型的平均正确率,本例为81.4%返回值:
通过随机逻辑回归模型筛选特征结束
有效特征为: 工龄,地址,负债率,信用卡负债
逻辑回归模型训练结束。
模型的平均正确率为: 0.8142857142857143