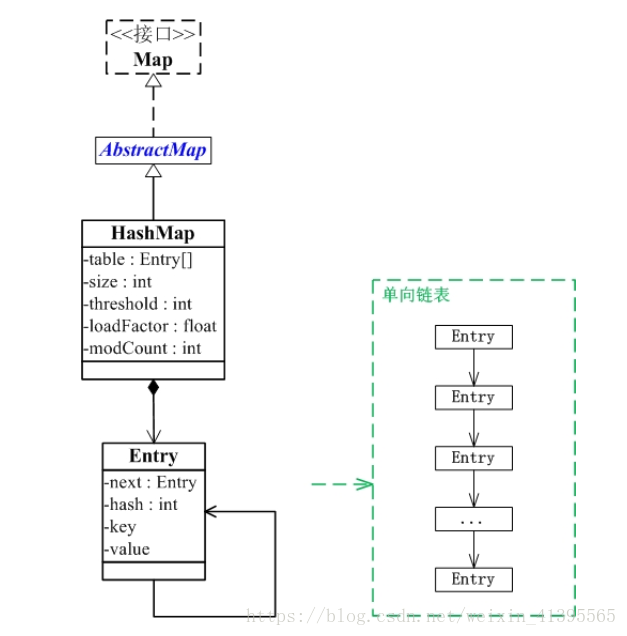
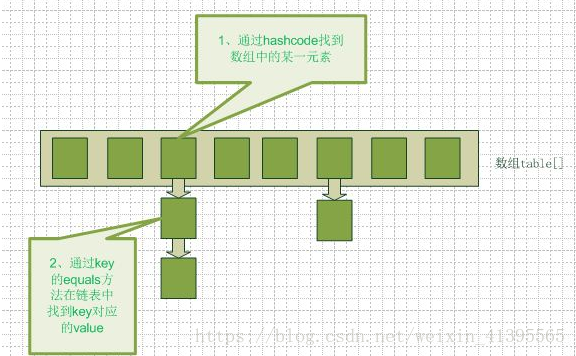
Hashmap实际上是一个数组和链表的结合体(在数据结构中,一般称之为“链表散列“),请看下图(横排表示数组,纵排表示数组元素【实际上是一个链表】)
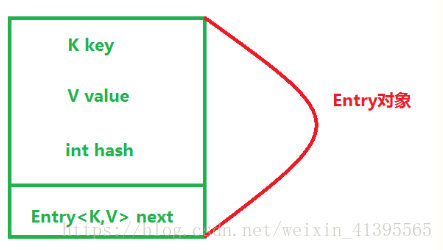
属性
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认容量16
static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认负载因子0.75
static final int TREEIFY_THRESHOLD = 8; // 链表节点转换红黑树节点的阈值, 9个节点转
static final int UNTREEIFY_THRESHOLD = 6; // 红黑树节点转换链表节点的阈值, 6个节点转
static final int MIN_TREEIFY_CAPACITY = 64; // 转红黑树时, table的最小长度定位数组位置
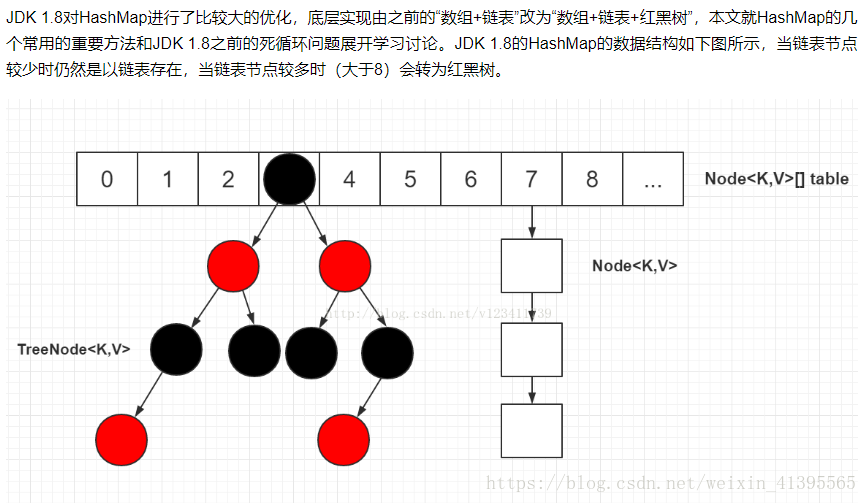
不管增加、删除、查找键值对,定位到哈希桶数组的位置都是很关键的第一步。前面说过HashMap的数据结构是“数组+链表+红黑树”的结合,所以我们当然希望这个HashMap里面的元素位置尽量分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,不用遍历链表/红黑树,大大优化了查询的效率。HashMap定位数组索引位置,直接决定了hash方法的离散性能。下面是定位哈希桶数组的源码:
// 代码1
static final int hash(Object key) { // 计算key的hash值
int h;
// 1.先拿到key的hashCode值; 2.将hashCode的高16位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 代码2
int n = tab.length;
// 将(tab.length - 1) 与 hash值进行&运算
int index = (n - 1) & hash;
整个过程本质上就是三步:
- 拿到key的hashCode值
- 将hashCode的高位参与运算,重新计算hash值
- 将计算出来的hash值与(table.length - 1)进行&运算
get()方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// table不为空 && table长度大于0 && table索引位置(根据hash值计算出)不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first; // first的key等于传入的key则返回first对象
if ((e = first.next) != null) { // 向下遍历
if (first instanceof TreeNode) // 判断是否为TreeNode
// 如果是红黑树节点,则调用红黑树的查找目标节点方法getTreeNode
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 走到这代表节点为链表节点
do { // 向下遍历链表, 直至找到节点的key和传入的key相等时,返回该节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null; // 找不到符合的返回空
}
- 先对table进行校验,校验是否为空,length是否大于0
- 使用table.length - 1和hash值进行位与运算,得出在table上的索引位置,将该索引位置的节点赋值给first节点,校验该索引位置是否为空
- 检查first节点的hash值和key是否和入参的一样,如果一样则first即为目标节点,直接返回first节点
- 如果first的next节点不为空则继续遍历
- 如果first节点为TreeNode,则调用getTreeNode方法(见下文代码块1)查找目标节点
- 如果first节点不为TreeNode,则调用普通的遍历链表方法查找目标节点
- 如果查找不到目标节点则返回空
getTreeNode()方法
final TreeNode<K,V> getTreeNode(int h, Object k) {
// 使用根结点调用find方法
return ((parent != null) ? root() : this).find(h, k, null);
}
HashMap扩容机制 resize()
虽然在hashmap的原理里面有这段,但是这个单独拿出来讲rehash或者resize()也是极好的。
什么时候扩容:当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值(知道这个阈字怎么念吗?不念fa值,念yu值四声)---即当前数组的长度乘以加载因子的值的时候,就要自动扩容啦。
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
先看一下什么时候,resize();
resize
我们分析下resize的源码,鉴于JDK1.8融入了红黑树,较复杂,为了便于理解我们仍然使用JDK1.7的代码,好理解一些,本质上区别不大,具体区别后文再说。
