数据来源http://1usagov.measuredvoice.com/2013/
代码区域:
path="D:\demo1\usagov_bitly_data2013-05-17-1368832207/usagov_bitly_data2013-05-17-1368832207.txt"
print open(path).readline()result:
{ "a": "Mozilla\/5.0 (Linux; U; Android 4.1.2; en-us; HTC_PN071 Build\/JZO54K) AppleWebKit\/534.30 (KHTML, like Gecko) Version\/4.0 Mobile Safari\/534.30", "c": "US", "nk": 0, "tz": "America\/Los_Angeles", "gr": "CA", "g": "15r91", "h": "10OBm3W", "l": "pontifier", "al": "en-US", "hh": "j.mp", "r": "direct", "u": "http:\/\/www.nsa.gov\/", "t": 1368832205, "hc": 1365701422, "cy": "Anaheim", "ll": [ 33.816101, -117.979401 ] }path="D:\demo1\usagov_bitly_data2013-05-17-1368832207/usagov_bitly_data2013-05-17-1368832207.txt"
import json
record=[json.loads(line) for line in open(path)]#列表推导式
print record[2]result:
{u'a': u'Mozilla/5.0 (Windows NT 6.1; rv:21.0) Gecko/20100101 Firefox/21.0', u'c': u'US', u'nk': 1, u'tz': u'America/Phoenix', u'gr': u'AZ', u'g': u'10DaxOu', u'h': u'10DaxOt', u'cy': u'Fort Huachuca', u'l': u'jaxstrong', u'al': u'en-US,en;q=0.5', u'hh': u'1.usa.gov', u'r': u'http://www.facebook.com/l.php?u=http%3A%2F%2F1.usa.gov%2F10DaxOt&h=4AQHdCPHx&s=1', u'u': u'http://www.saj.usace.army.mil/Media/NewsReleases/tabid/6071/Article/14065/corps-to-continue-water-releases-from-lake-okeechobee.aspx', u't': 1368832209, u'hc': 1368814585, u'll': [31.5273, -110.360703]}对时区进行计数
path="D:\demo1\usagov_bitly_data2013-05-17-1368832207/usagov_bitly_data2013-05-17-1368832207.txt"
import json
record=[json.loads(line) for line in open(path)]#列表推导式
time_zones=[rec['tz'] for rec in record if 'tz' in rec]
print time_zones[:10]#first 10
from collections import defaultdict
def getcounts(sequence):
counts=defaultdict(int)#所有值初始化为0默认字典对象
for x in sequence:
counts[x]+=1
return counts
count=getcounts(time_zones)
print count['America/Phoenix']
'''
前九位时区及计数值
'''
def top_counts(count_dict,n=9):
value_key_pairs=[(count,tz) for tz,count in count_dict.items()]#计数字典的键值对
value_key_pairs.sort()
return value_key_pairs[-n:]#从小到大的排序中最后n个
print top_counts(count)
[u'America/Los_Angeles', u'', u'America/Phoenix', u'America/Chicago', u'', u'America/Indianapolis', u'America/Chicago', u'', u'Australia/NSW', u'']
40
[(50, u'America/Indianapolis'),
(85, u'Europe/London'),
(89, u'America/Denver'),
(102, u'Asia/Tokyo'),
(184, u'America/Puerto_Rico'),
(421, u'America/Los_Angeles'),
(636, u''),
(686, u'America/Chicago'),
(903, u'America/New_York')]用pandas对时区进行计数
from pandas import DataFrame,Series
import pandas as pd
import numpy as py
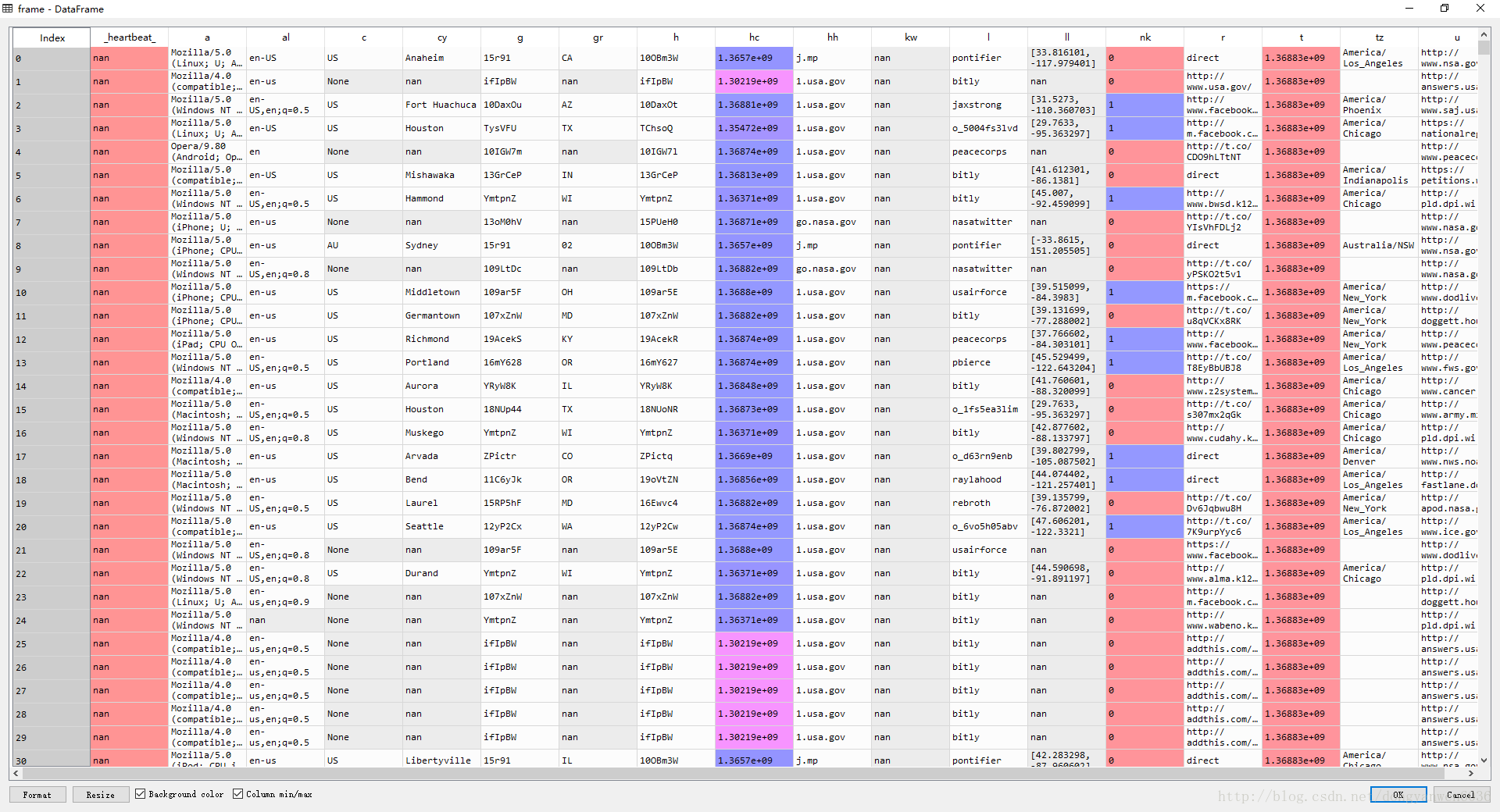
frame=DataFrame(record)
print frame
tz_counts=frame['tz'].value_counts()
print tz_counts[:9]
#我们给缺失的时区添上一个替代值Tianjin,可以通过布尔型数组索引加以替换空字符串
clean_tz=frame['tz'].fillna('Tianjin')#NaN缺失值
clean_tz[clean_tz=='']='Unknown'#空字符串
part_tz_count=clean_tz.value_counts()
print part_tz_count[:9]
tz_counts[:9].plot(kind='barh',rot=2)#rot调节图放大缩小,‘barh’:horizontal bar plotresult
America/New_York 903
America/Chicago 686
636
America/Los_Angeles 421
America/Puerto_Rico 184
Asia/Tokyo 102
America/Denver 89
Europe/London 85
America/Indianapolis 50
Name: tz, dtype: int64
America/New_York 903
America/Chicago 686
Unknown 636
America/Los_Angeles 421
America/Puerto_Rico 184
Tianjin 120
Asia/Tokyo 102
America/Denver 89
Europe/London 85
Name: tz, dtype: int64
Series一维数组对象,下面构造一个
'''
Python split()通过指定分隔符对字符串进行切片,
split(str="", num=string.count(str)).
str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
如果参数num 有指定值,则仅分隔 num 个子字符串.
'''
results=Series([x.split()[0] for x in frame.a.dropna()])#在agent属性中去掉缺失值
print results[:5]
print results.value_counts()[:8]
cframe=frame[frame.a.notnull()]
operating_sys=np.where(cframe['a'].str.contains('Windows'),'Windows','Not Windows')
print operating_sys[:5]
groupby_tz_os=cframe.groupby(['tz',operating_sys])#背后原理靠数据库的concat,现在仅仅是一个GroupBy对象,
#它实际上还没有进行任何计算,只是含有一些有关分组键的中间数据而已,然后我们可以调用GroupBy的size/mean方法来计算分组
#size函数类似于value_counts
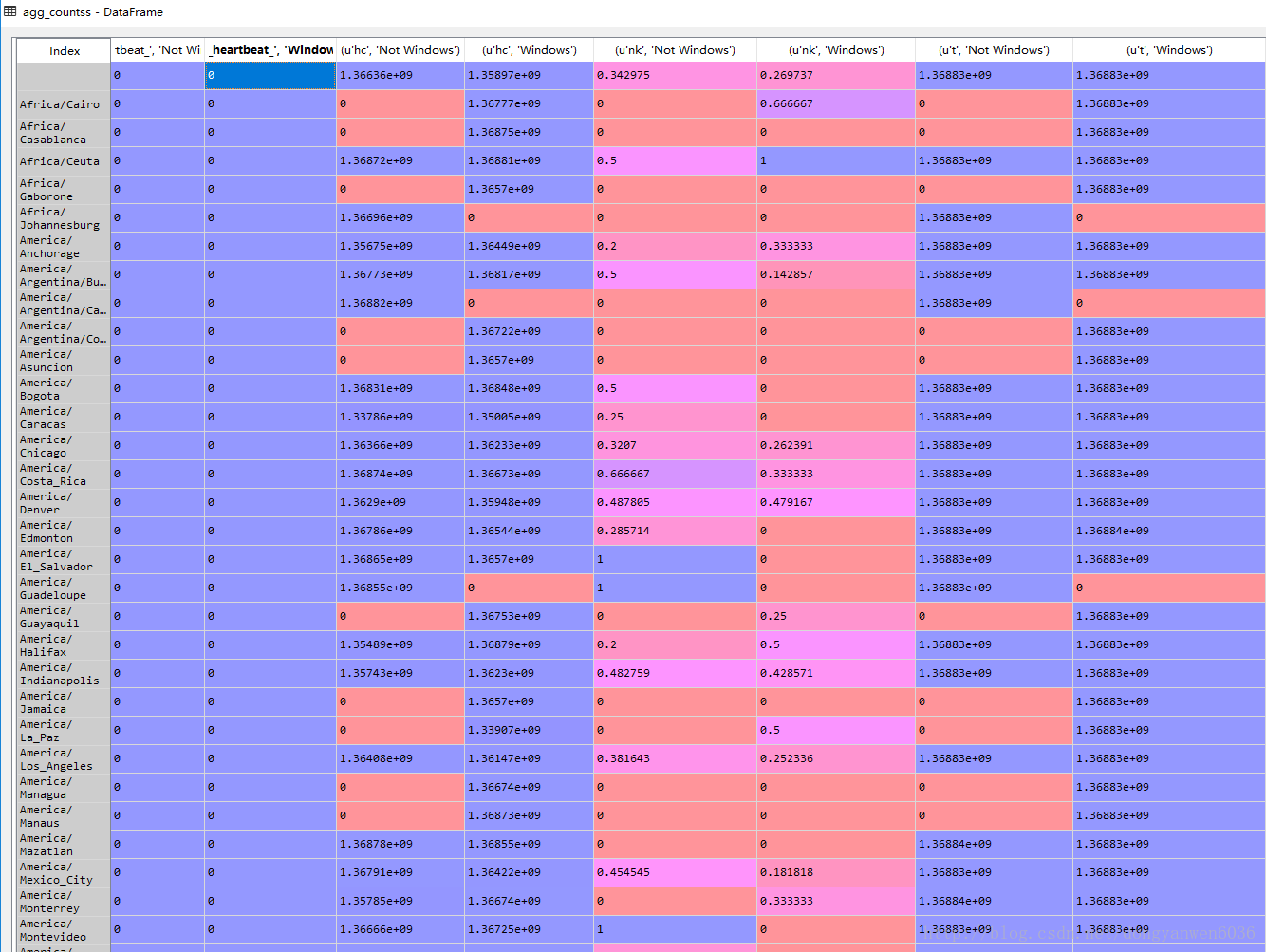
agg_counts=groupby_tz_os.size().unstack().fillna(0)
agg_countss=groupby_tz_os.mean().unstack().fillna(0)
print agg_counts[:5]
print agg_countss[:5]
indexer=agg_counts.sum(1).argsort()#sum(1)是计数行为主,sum(0或空)是计数列属性
print indexer[:10]#argsort()按索引升序
take_subset=agg_counts.take(indexer)[-10:]
print take_subset
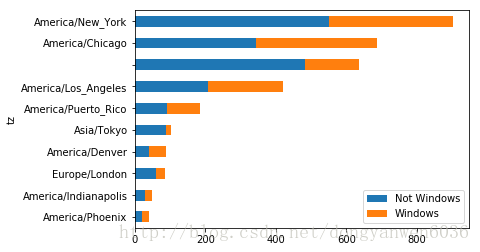
take_subset.plot(kind='barh',stacked=True)
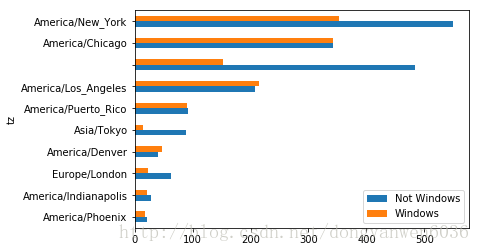
take_subset.plot(kind='barh',stacked=False)
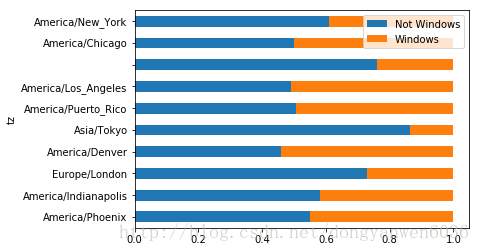
normed_subset=take_subset.div(take_subset.sum(1),axis=0)#如果axis=1Mismatched indices will be unioned together
normed_subset.plot(kind='barh',stacked=True)
result
0 Mozilla/5.0
1 Mozilla/4.0
2 Mozilla/5.0
3 Mozilla/5.0
4 Opera/9.80
dtype: object
Mozilla/5.0 3251
Mozilla/4.0 322
CakePHP 38
ShortLinkTranslate 36
TVersity 30
Opera/9.80 28
Dalvik/1.6.0 19
Xenu 15
dtype: int64
['Not Windows' 'Windows' 'Windows' 'Not Windows' 'Not Windows']
Not Windows Windows
tz
484.0 152.0
Africa/Cairo 0.0 3.0
Africa/Casablanca 0.0 1.0
Africa/Ceuta 4.0 2.0
Africa/Gaborone 0.0 1.0
tz
55
Africa/Cairo 101
Africa/Casablanca 100
Africa/Ceuta 36
Africa/Gaborone 97
Africa/Johannesburg 42
America/Anchorage 43
America/Argentina/Buenos_Aires 44
America/Argentina/Catamarca 47
America/Argentina/Cordoba 50
dtype: int64
其中null没有除去,只是除去了a.null
Not Windows Windows
tz
America/Phoenix 22.0 18.0
America/Indianapolis 29.0 21.0
Europe/London 62.0 23.0
America/Denver 41.0 48.0
Asia/Tokyo 88.0 14.0
America/Puerto_Rico 93.0 91.0
America/Los_Angeles 207.0 214.0
484.0 152.0
America/Chicago 343.0 343.0
America/New_York 550.0 353.0