主要参考书目《统计学习方法》第2版,清华大学出版社
参考书目 Machine Learning in Action, Peter Harrington
用于考研复试笔记,所以写的很简洁,自己能看懂就行。有学习需求请绕道,参考吴恩达机器学习或以上书籍,讲得比大多数博客好。
概念
感知机(perceptron)是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1,-1二值。
f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign(w·x+b) f(x)=sign(w⋅x+b)
其中, s i g n ( x ) = { + 1 , x ≥ 0 − 1 , x < 0 sign(x)= \left\{ \begin{aligned} +1, && x \ge 0\\ -1, && x < 0 \end{aligned} \right. sign(x)={
+1,−1,x≥0x<0
对于一个特征空间 R n R^n Rn中的一个超平面 S S S,其中 w w w是超平面的法向量, b b b是超平面的截距
, S S S称为分离超平面(separating hyperplane)
线性可分数据集(linearly separable data set)
被划分在超平面的两侧。
原理
感知机的学习策略
首先写出输入空间 R n R^n Rn中任一点 x 0 x_0 x0到超平面 S S S的距离
1 ∣ ∣ w ∣ ∣ ∣ w ⋅ x 0 + b ∣ \frac{1}{||w||}|w·x_0+b| ∣∣w∣∣1∣w⋅x0+b∣
书上扯淡说了个二范数,就是距离公式而已,拓展到n维空间
不考虑 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣感知机学习的损失函数
L ( x , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(x,b)=-\sum\limits_{x_i \in M}y_i(w·x_i+b) L(x,b)=−xi∈M∑yi(w⋅xi+b)
其中 M M M为误分类点的集合
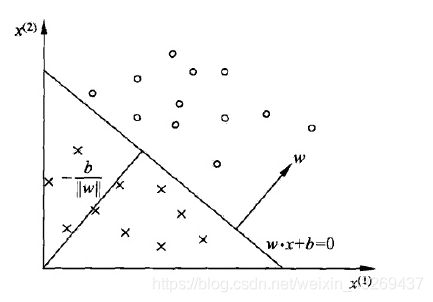
为什么这里有一个-号?,因为认为 w ∗ x i + b > 0 , y i = − 1 w*x_i+b>0,y_i=-1 w∗xi+b>0,yi=−1其>0时,为+1,
比如这个图,认为超平面(分类的这根线)上面为+1,下面为-1 。 所以损失函数大于0的时候是分类正确的时候,小于或等于0则分类错误。
找到使损失函数最小的参数 w 、 b w、b w、b就是感知机模型。
随机梯度下降法(stochastic gradient descent)
输入:训练集数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={
(x1,y1),(x2,y2),...,(xN,yN)},其中 x i ∈ χ = R n , y i ∈ Y = { − 1 , + 1 } , i = 1 , 2 , . . . , N x_i \in \chi=R^n,y_i \in Y=\{-1,+1\}, i = 1,2,...,N xi∈χ=Rn,yi∈Y={
−1,+1},i=1,2,...,N学习率(learning rate)为 η ( 0 < η ≤ 1 ) \eta(0<\eta \leq1) η(0<η≤1)
输入: w 、 b w、b w、b 感知机模型为 f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign(w·x+b) f(x)=sign(w⋅x+b)
(1)选取初值为 w 0 , b 0 w_0,b_0 w0,b0
(2)在训练集中选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
(3)如果 y i ( w ⋅ x i + b ) ≤ 0 y_i(w·x_i+b) \leq 0 yi(w⋅xi+b)≤0, // 小于等于0的时候说明分类错误,上面有提到
w ← w + η y i x i w \leftarrow w + \eta y_i x_i w←w+ηyixi
b ← b + η y i b \leftarrow b + \eta y_i b←b+ηyi
turn to (2) until 训练集中没有误分类点
此处《统计学习方法》是每一轮选择一个点进行随机梯度下降,但是记得在Andrew Ng的课上说是,没更新一次都要跑一边数据集,我当时的理解是用所有数据来更新一次权值。此处应该如何,还有待考察。
如何理解?
w ← w + η y i x i w \leftarrow w + \eta y_i x_i w←w+ηyixi
b ← b + η y i b \leftarrow b + \eta y_i b←b+ηyi
y i x i y_i x_i yixi y i y_i yi分别是损失函数对 w 、 b w、b w、b的偏导,沿着梯度方向迭代。
就比如 b b b,如果 y i > 0 ( y i = 1 ) y_i>0 (y_i=1) yi>0(yi=1)认为是错的,说明这个点在超平面上方, b b b更新后会变大,联想 y = a x + b y=ax+b y=ax+b,那超平面就会稍微往上移动,试图把 ( x i , y i ) (x_i,y_i) (xi,yi)包括进去。
定理2.1(Novikoff)
设数据集 T = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) T={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)} T=(x1,y1),(x2,y2),...,(xN,yN)是线性可分的,其中 x i ∈ χ = R n , y i ∈ { − 1 , + 1 } , i = 1 , 2 , . . . , N x_i \in \chi = R^n, y_i \in \{-1,+1\},i=1,2,...,N xi∈χ=Rn,yi∈{
−1,+1},i=1,2,...,N,则
(1)存在满足条件 ∣ ∣ w ^ o p t ∣ ∣ = 1 ||\hat{w}_{opt}||=1 ∣∣w^opt∣∣=1的超平面 w ^ o p t ⋅ x ^ = w o p t ⋅ x + b o p t = 0 \hat{w}_{opt}·\hat{x}=w_{opt}·x+b_{opt}=0 w^opt⋅x^=wopt⋅x+bopt=0将训练集完全分开;且存在 γ > 0 \gamma>0 γ>0,对所有 i = 1 , 2 , . . . , N i=1,2,...,N i=1,2,...,N
y i ( w ^ o p t ⋅ x ^ i ) = y i ( w o p t ⋅ x i + b o p t ) ≥ γ y_i(\hat{w}_{opt}·\hat{x}_i)=y_i(w_{opt}·x_i+b_{opt})\geq\gamma yi(w^opt⋅x^i)=yi(wopt⋅xi+bopt)≥γ
(2)令 R = max 1 ≤ i ≤ N ∣ ∣ x i ^ ∣ ∣ R=\max\limits_{1\leq i \leq N}||\hat{x_i}|| R=1≤i≤Nmax∣∣xi^∣∣,则感知机算法2.1在训练数据集上的误分类次数k满足不等式 k ≤ ( R γ ) 2 k\leq(\frac{R}{\gamma})^2 k≤(γR)2
扯了一堆,无非就是想说
(1)如果数据集是可分这一事实的前提下,那么他一定可分,如果可分,那么一定能找到这样的超平面
(2)误分类次数是有上界的,随机梯度下降一定收敛。
关于感知机的对偶形式,请绕道
https://www.zhihu.com/question/26526858/answer/131591887

课后习题
21.为什么感知机不能表示亦或。

代码
用C++写的,以后再也不用C++写机器学习的算法了。。
算个向量都得手算。。。
偷懒维度直接写的2,认真看应该不难看懂
#include <iostream>
using namespace std;
const double eta = 1;
const double eps = 1e-5;
struct point {
double x[3];
int y;
};
int cnt = 1;
void pcpt_train(point* p, double* w, double &b, int n) {
for (int i = 1; i <= n; i++) {
double sum = 0;
for (int j = 1; j <= 2; j++)
sum += w[j] * p[i].x[j];
sum += b;
if (p[i].y * sum < eps) {
for (int j = 1; j <= 2; j++)
w[j] += p[i].y * p[i].x[j] * eta;
b += p[i].y * eta;
cout << cnt++ << "\t\tx" << i << "\t\t(" << w[1] << " " << w[2] << ")\t" << b << "\t" << w[1] << "x(1)+" << w[2] << "x(2)+" << b << endl;
pcpt_train(p, w, b, n);
return;
}
}
}
int main() {
point p[10];
p[1].y = p[2].y = 1, p[3].y = -1;
p[1].x[1] = p[1].x[2] = 3;
p[2].x[1] = 4, p[2].x[2] = 3;
p[3].x[1] = 1, p[3].x[2] = 1;
double w[10] = {
0 }; double b = 0;
int n = 3;
cout << "迭代次数\t误分类点数\tw\tb\tw*x+b" << endl;
pcpt_train(p, w, b, n);
cout << w[1] << " " << w[2] << " " << b << endl;
return 0;
}