4.3目标检测
觉得有用的话,欢迎一起讨论相互学习~Follow Me
3.6交并比intersection over union
- 交并比函数(loU)可以用来评价对象检测算法,可以被用来进一步改善对象检测算法的性能。
- 如何评价一个算法的好坏,即如图中假设红色框线表示 真实的对象所在边界框,紫色框线表示 模型预测的对象所在边界框.通过计算两个边界框交集和并集的比用于评价对象检测算法的好坏。

- 在对象检测的算法中,如果IoU>0.5则认为检测正确。0.5是人为定义的阈值,也可以定义为0.5及以上的值
3.7非极大值抑制Non-max suppression
在以上介绍的对象检测的算法中,存在模型可能对同一个对象做出多次检测的状况。非极大值抑制(non-max suppression)可以确保算法对每个对象仅检测一次。
非极大值抑制算法Non-max suppression
- 对于如图的对象检测,使用\(19*19\)的网格,在进行预测的同时,两辆车中心旁的其他网格也会认为目标对象的中心点在其中。如图绿色和黄色方框中显示。


- 为了清理多余或错误的检测结果,使用非极大值抑制算法Non-max suppression
- 只输出概率最大的分类结果--即挑选出检测\(p_c\)最大的边框,而其余和该边框IoU(交并比)很高的其他边框则会认为是在检测同一对象,则另外的和最大\(P_c\)边框IoU很大的边框都会变暗。

非极大值抑制算法Non-max suppression实现细节
- 假设只检测汽车这一个对象,所以去掉目标标签向量中的\(c_{1},c_{2},c_{3}\)
- 去掉所有\(p_{c}\le0.6\)的边框,抛弃所有概率比较低的输出边界框。
while 还有边界框剩下: - 在剩下的没有被抛弃的边界框中一直挑选\(p_{c}\)最高的边界框
- 在剩下的边界框中将与最高\(p_{c}\)有较大IoU(\(IoU\ge0.5\))的边界框全部抛弃
- 如果要检测的对象不止汽车一个,还有行人和自行车的对象,正确的做法是:独立进行三次非最大值抑制,对每个输出类别都进行一次

3.8Anchor Boxes
先前介绍的方法只能使格子检测出一个对象,如果想要一个格子检测出多个对象-- anchor box
参考文献
Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:779-788.- 使用\(3*3\)的网格检测图中的对象,注意行人的中点和汽车的中点几乎都在同一个地方,两者都落入同一个格子中。使用原先的目标标签,只能选择两个类别中的一个进行识别。

- 此时可以使用Anchor策略--即使用特定形状的Anchor box 作为边界框,则策略需要把预测结果与anchor boxes 关联起来。以处理两个识别对象的中心点落入同一个网格中的情况。
- 则此时边界框的目标标签可以被编码为:
\[\begin{equation} A=\left[ \begin{matrix} p_{c}\\ b_{x}\\ b_{y}\\ b_{h}\\ b_{w}\\ c_{1}\\ c_{2}\\ c_{3}\\ p_{c}\\ b_{x}\\ b_{y}\\ b_{h}\\ b_{w}\\ c_{1}\\ c_{2}\\ c_{3}\\ \end{matrix} \right] \left[ \begin{matrix} anchor box1\\ 使用0和1表示网格中是否有目标物体\\ 边框中心点横坐标值的范围在(0,1)之间\\ 边框中心点纵坐标的范围在(0,1)之间\\ 边框高可以大于1,因为有时候边框会跨越到另一个方格中\\ 边框宽可以大于1,因为有时候边框会跨越到另一个方格中\\ 行人\\ 汽车\\ 摩托车\\ anchor box2\\ 使用0和1表示网格中是否有目标物体\\ 边框中心点横坐标值的范围在(0,1)之间\\ 边框中心点纵坐标的范围在(0,1)之间\\ 边框高可以大于1,因为有时候边框会跨越到另一个方格中\\ 边框宽可以大于1,因为有时候边框会跨越到另一个方格中\\ 行人\\ 汽车\\ 摩托车\\ \end{matrix} \right] \end{equation}\]
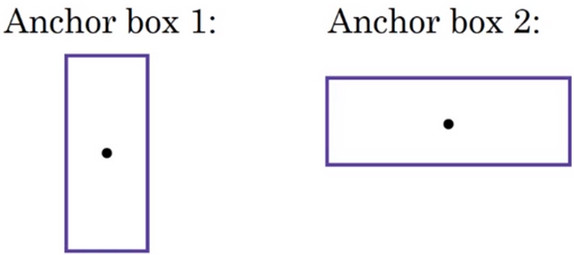

单目标图像检测算法--对于训练集图像中的每个对象,都根据对象的中点的位置,分配到对应的格子中。所以输出y是\(3*3*8\), 使用anchor boxes 策略,每个对象不仅和之前一样被分配到同一个格子中,还被分配到对象形状交并比最高的anchor boxes中,假设只检测图片中的两个对象则输出y为\(3*3*16\)
Note:Anchor boxes算法处理不好的情况
- 两个对象的中点在同一个网格中,并且使用 同一种形状 的Anchor Boxes检测
- 有超过两个的对象的中点在同一个网格中。
3.9YOLO算法
- 参数设置:
- 3种识别类别:1.pedestrianx行人 2.car车 3.motorcycle 摩托车-->\(c_{1},c_{2},c_{3}\)
- \(3*3\)识别网格
- 两种识别anchor boxes-->\(b_{x},b_{y},b_{h},b_{w}\)

- 运行非极大值抑制:
- 使用两个anchor boxes,那么对于9个格子中的任何一个都会有两个预测的边界框。

- 抛弃概率低的预测,即模型认为这个网格中什么都没有的边界框。

- 对于三种检测目标--行人,机动车,摩托车,对于每个类别单独运行非最大值抑制。

- 使用两个anchor boxes,那么对于9个格子中的任何一个都会有两个预测的边界框。