zookeeper的应用场景
订阅发布
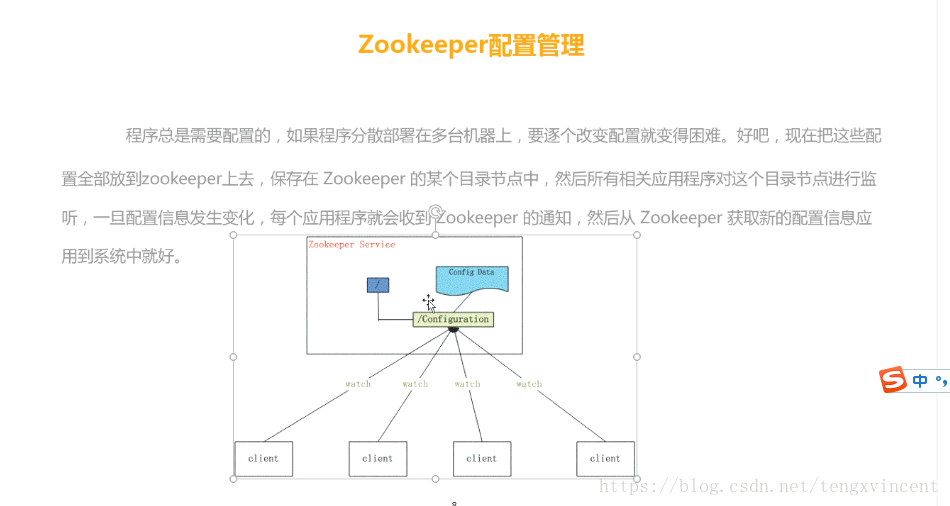
使用watcher机制 统一配置管理(disconf):实现配置信息的集中式管理和数据的动态更新。
实现配置中心的两种模式:push pull
zookeeper采用推拉结合的方式,客户端向服务器端注册自己需要关注的节点,一旦节点数据发生变化,那么服务器就会向客户端发送watcher通知。客户端收到通知后,主动到服务器端获取更新后的数据。
实现配置中心的要求:
1 数据量比较小
2 数据内容在运行是会发生动态变更
3 集群中各个机器共享数据
分布式锁
通常实现分布式有几种方式?
1 redis setNX 存在返回零,不存在返回一
2 数据库方式实现 效率低
a:唯一索引 b:mysql 默认数据库引擎innodb 可以加行锁或表锁。for update
3 zookeeper实现分布式锁
a: 排它锁 写锁
多个客户端同时在zookeeper中的某个节点下创建同名临时节点,由于同一节点下,节点的有唯一性,b机器只有等a机器断开连接,创建的临时节点自动删除后,才能创建节点。
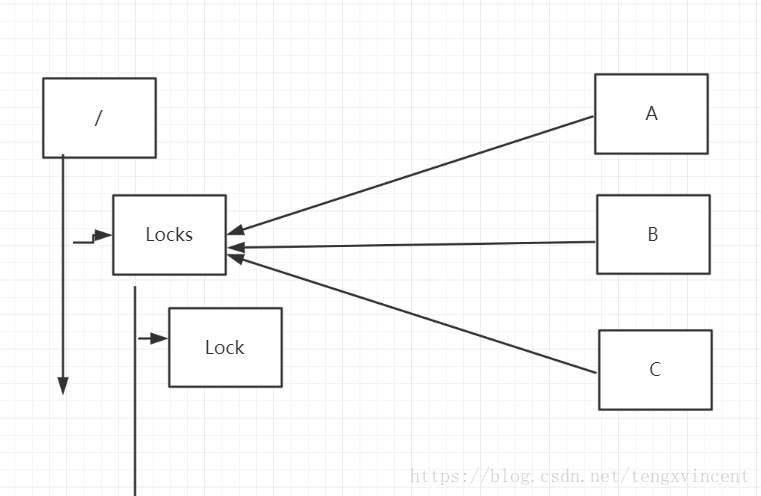
b:共享锁 读锁
算法流程,假设锁空间的根节点为/lock:
-
客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点为/lock/lock-0000000000,第二个为/lock/lock-0000000001,以此类推;
-
客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听刚好在自己之前一位的子节点删除消息,获得子节点变更通知后重复此步骤直至获得锁;
-
执行业务代码;
-
完成业务流程后,删除对应的子节点释放锁。
负载均衡
请求/数据 分摊到多个计算机单元上,zookeeper 的负载均衡需要自己实现
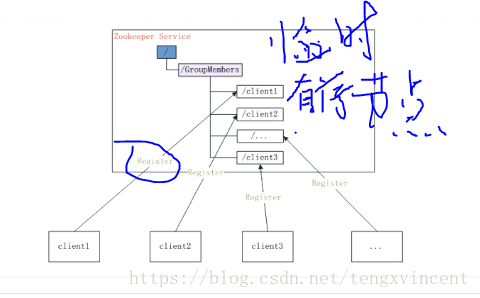
所谓的集群管理无外乎两点:是否有机器退出和加入,选举master。
对于第一点,所有机器约定在zookeeper父目录GroupMembers下创建临时节点,然后注册监听父目录节下点的子节点消息。一旦有机器挂掉,该机器与zookeeper的链接断开,其所创建的临时目录节点被删除,所有其他机器将得到通知:某个兄弟目录被删除了,于是,所有机器都知道,该机器下船了。同理新机器的加入 也是类似,所有机器收到通知 有新的目录加入,highcount又有了。
对于选举master,我们稍微改变一下,所有机器创建有序临时目录节点,每次选取编号最小的机器作为master就好了
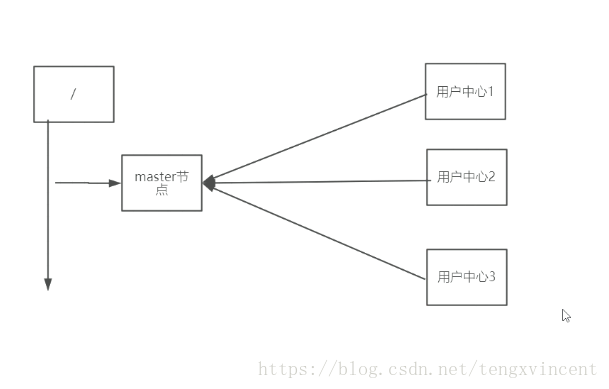
master选举
使用zookeeper 进行master选举类似于排它锁,多个机器server 向zookeeper server的同一节点下 creater同名 临时节点。
根据zk节点特性,不能重名,所以同一时间只有一个用户中心server 注册成功。注册成功的机器serve为master,其他的为slave。
当master 失效,zookeeper与master的连接断开,会话将被删除,由master创建的临时节点也被删除。之后会有新的机器server 创建临时节点成功,成为新的master。
分布式队列
1,先进先出队列
- 通过getChildren获取指定根节点下的所有子节点,子节点就是任务
- 确定自己节点在子节点中的顺序
- 如果自己不是最小的子节点,那么监控比自己小的上一个子节点,否则处于等待
- 接收watcher通知,重复流程
2,Barrier模式 同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
第一类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。
第二类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
统一命名服务
id生成器