zookeeper —— 分布式服务协调框架
一、Zookeeper概述
1、Zookeeper的基本概念
- Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
- Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式
- Zookeeper = 文件系统 + 通知机制
2、Zookeeper的特点
- Zookeeper:一个领导者(leader),多个跟随者(follower)组成的集群。
- Leader负责进行投票的发起和决议,更新系统状态
- Follower用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票
- 群中只要有半数以上节点存活,Zookeeper集群就能正常服务。
- 全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的。
- 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行。
- 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,client能读到最新数据。
3、Zookeeper的数据结构
- ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。

- Zookeeper集群自身维护了一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,我们称之为"znode",不同于树的节点,Znode的引用方式是路径引用,类似于文件路径:/znode1/leaf1
- 这样的层级结构,让每一个Znode节点拥有唯一的路径,就像命名空间一样对不同信息作出清晰的隔离。
- ZooKeeper的节点是通过像树一样的结构来进行维护的,并且每一个节点通过路径来标示以及访问。
- 除此之外,每一个节点还拥有自身的一些信息,包括:数据、数据长度、创建时间、修改时间等等。
- 从这样一类既含有数据,又作为路径表标示的节点的特点中,可以看出,ZooKeeper的节点既可以被看做是一个文件,又可以被看做是一个目录,它同时具有二者的特点。为了便于表达,今后我们将使用Znode来表示所讨论的ZooKeeper节点。
- 每一个znode默认能够存储1MB的数据
- znode是由客户端创建的,它和创建它的客户端的内在联系,决定了它的存在性,一般存在四种类型节点:
- PERSISTENT-持久化节点:创建本节点的客户端在与zookeeper服务的连接断开后,这个节点也不会被删除(除非使用API强制删除)
- PERSISTENT_SEQUENTIAL-持久化顺序编号节点:当客户端请求创建这个节点A后,zookeeper会根据parent-znode的zxid状态,为这个A节点编写一个全目录唯一的编号(这个编号只会一直增长)。当客户端与zookeeper服务的连接断开后,这个节点也不会被删除。
- EPHEMERAL-临时目录节点:创建本节点的客户端在与zookeeper服务的连接断开后,这个节点(还有涉及到的子节点)就会被删除。
- EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点:当客户端请求创建这个节点A后,zookeeper会根据parent-znode的zxid状态,为这个A节点编写一个全目录唯一的编号(这个编号只会一直增长)。当创建这个节点的客户端与zookeeper服务的连接断开后,这个节点被删除。
- 【注意】:无论是EPHEMERAL还是EPHEMERAL_SEQUENTIAL节点类型,在zookeeper的client异常终止后,节点也会被删除。
二、Zookeeper的安装部署
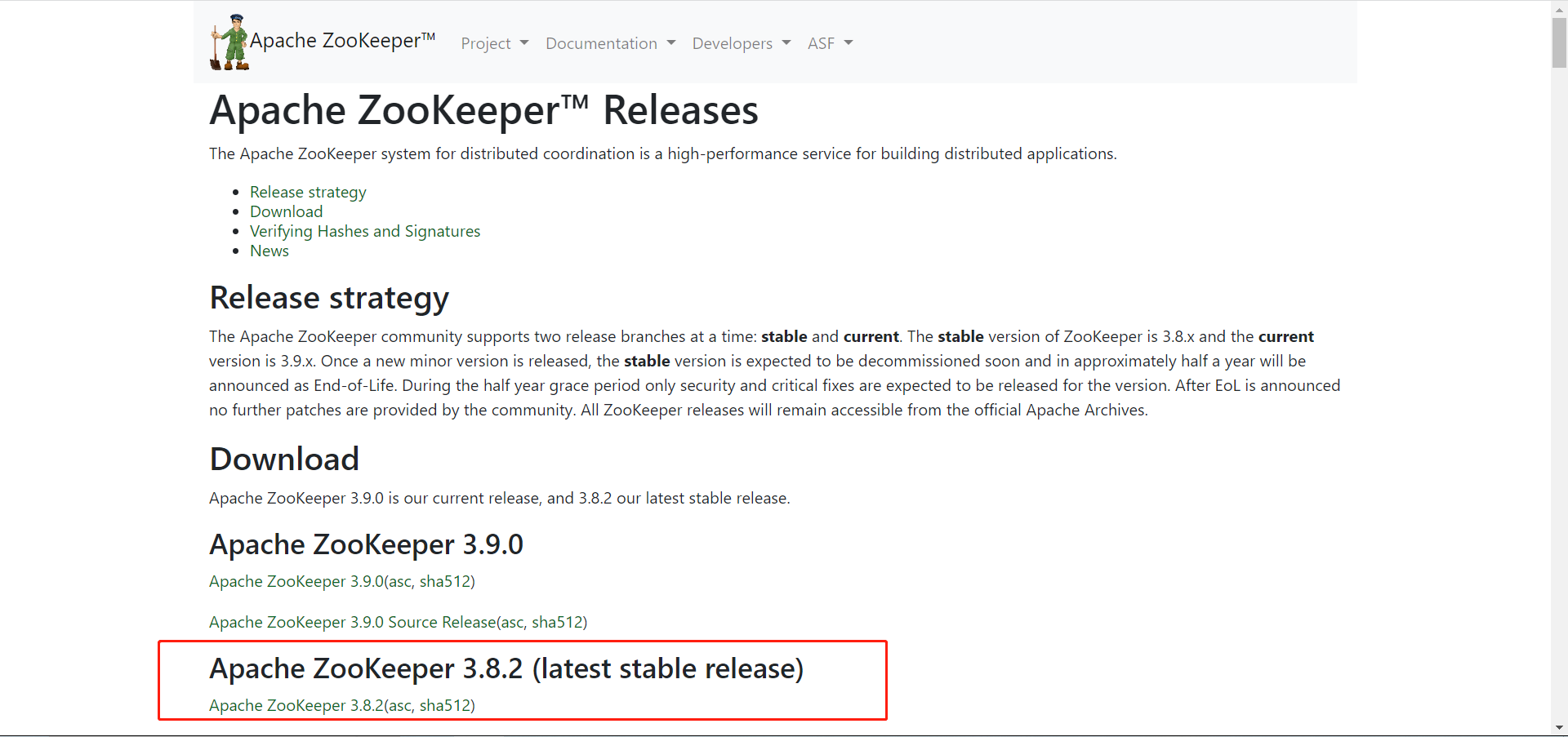
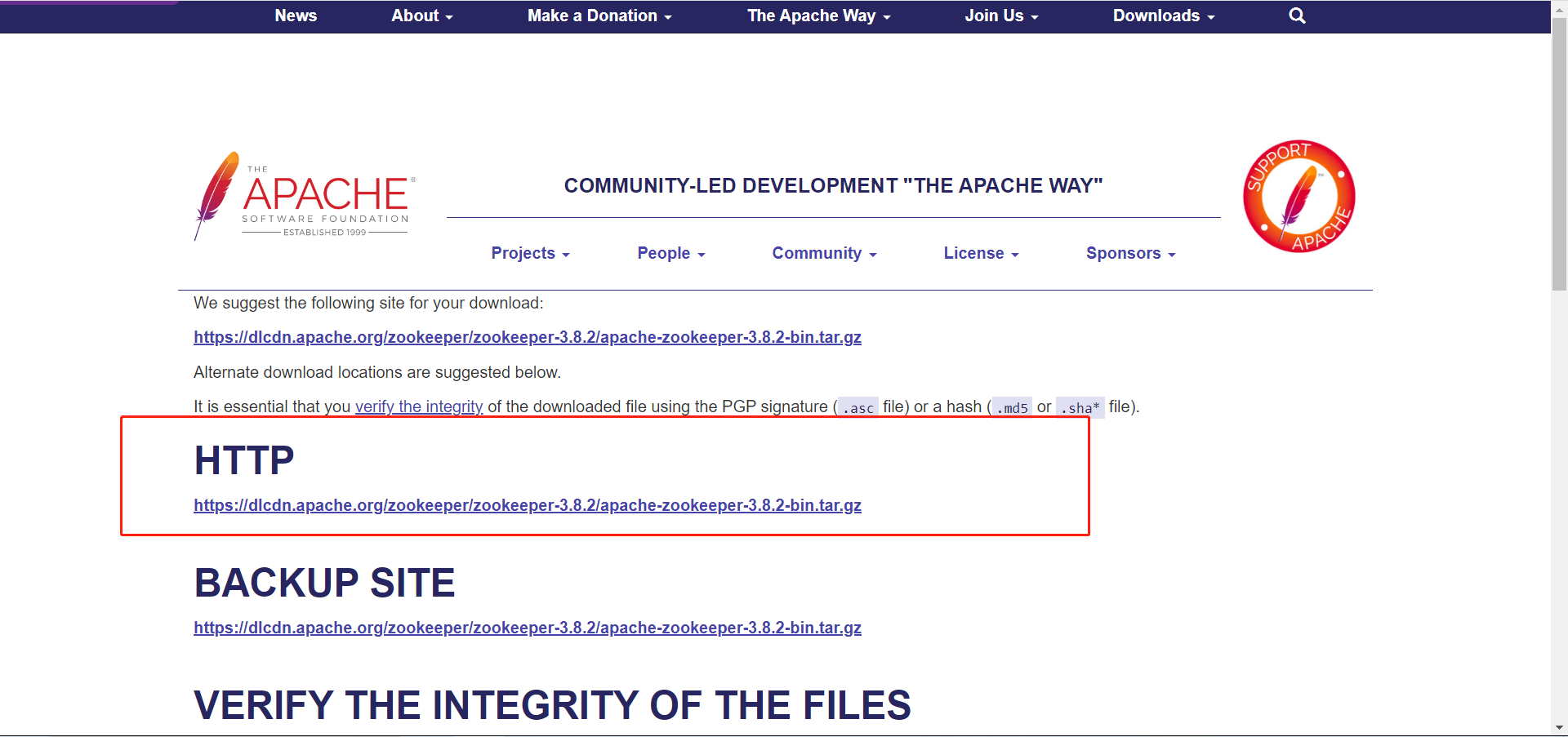
1、Zookeeper的下载
在Zookeeper官网,选择你需要的版本进行下载,以下是我下载的版本。
2、Zookeeper的安装
本地模式(单机模式standalone)安装部署
Step1:将下载好的压缩包上传到虚拟机的指定目录下,我上传到了/opt/software/
Step2:将压缩包进行解压到指定目录下,我解压到了/opt/app/下
tar -zxvf apache-zookeeper-3.8.2-bin.tar.gz -C /opt/app/
Step3:将zookeeper的文件夹进行重命名
mv apache-zookeeper-3.8.2-bin/ zookeeper-3.8.2
Step4:配置环境变量,并进行source使配置文件生效
vim /etc/profile source /etc/profile

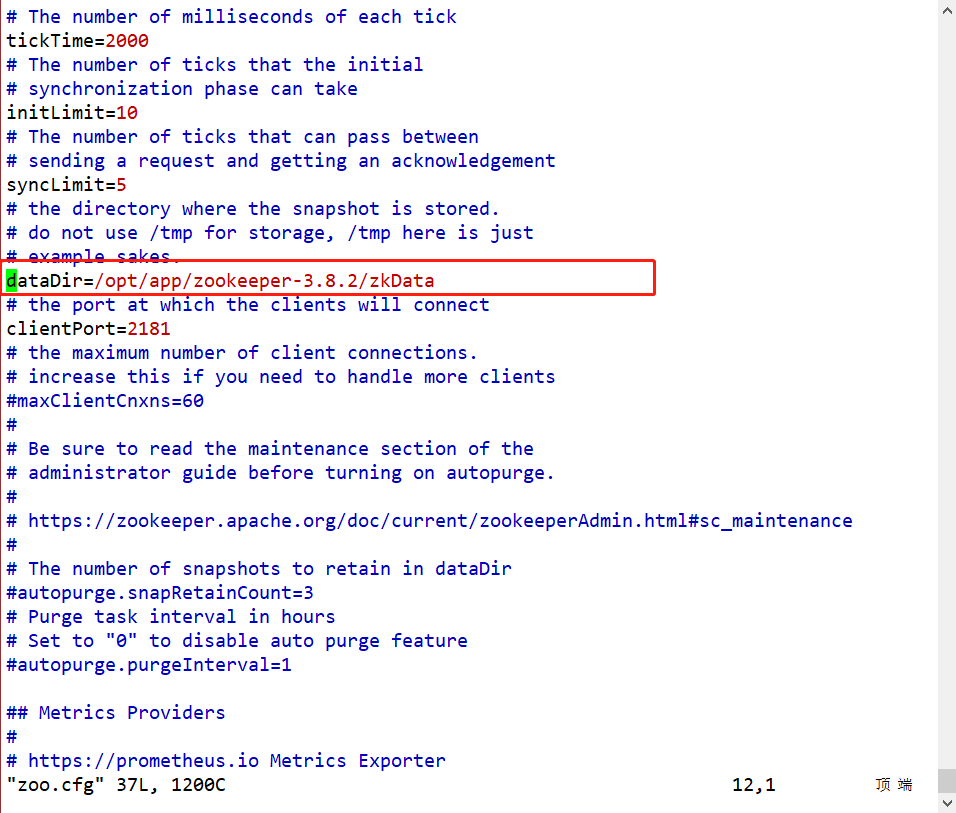
Step5:进入/opt/app/zookeeper-3.8.2/conf目录下,将此配置文件进行重命名mv zoo_sample.cfg zoo.cfg,然后进行编辑。并且在/opt/app/zookeeper-3.8.2/新建目录touch zkData
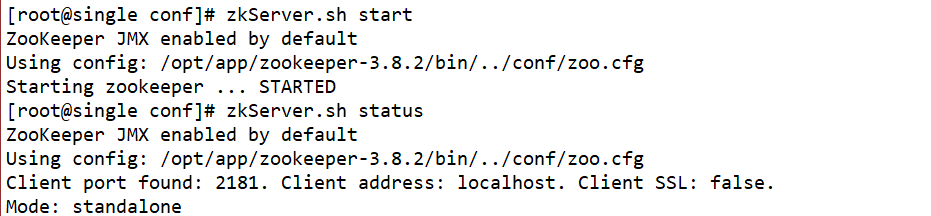
Step6:使用命令zkServer.sh start启动zookeeper,使用命令zkServer.sh status查看zookeeper状态,使用命令netstat -untlp查看端口号
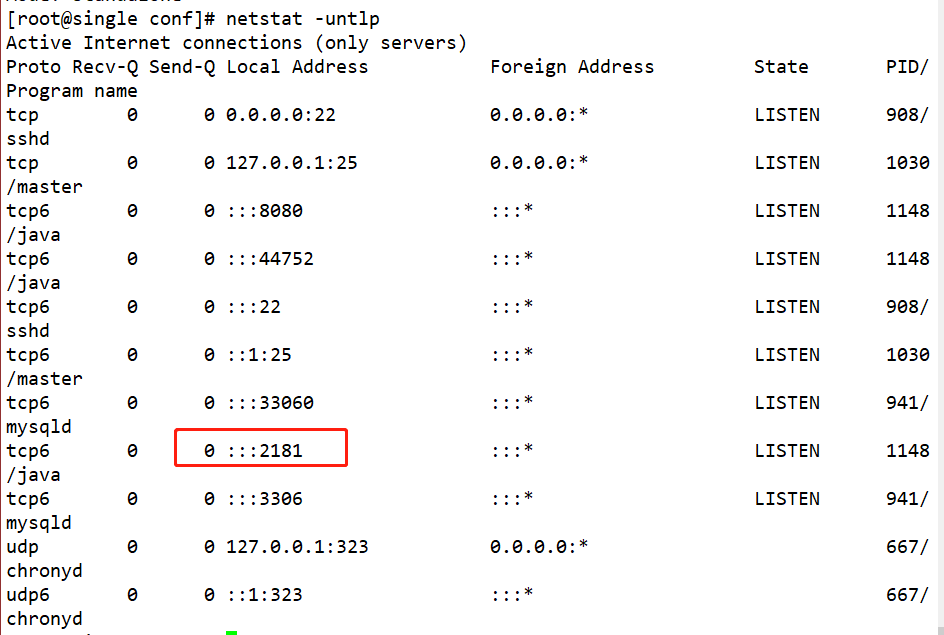
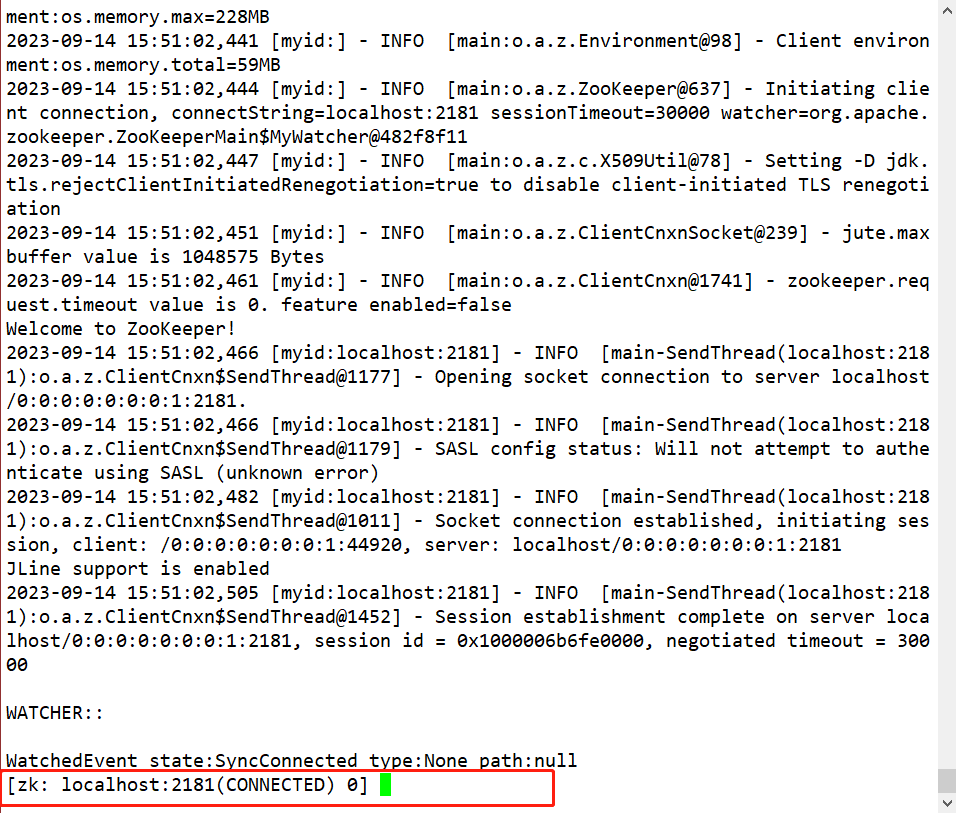
Step7:使用命令zkCli.sh -server localhost:2181,进入客户端
Step8:使用命令zkServer.sh stop退出

分布式(集群模式cluster)安装部署
-
集群规划
-
在node1、node2、node3三个节点上部署Zookeeper。
-
-
先选择node1节点进行解压安装步骤和本地模式安装部署一样
-
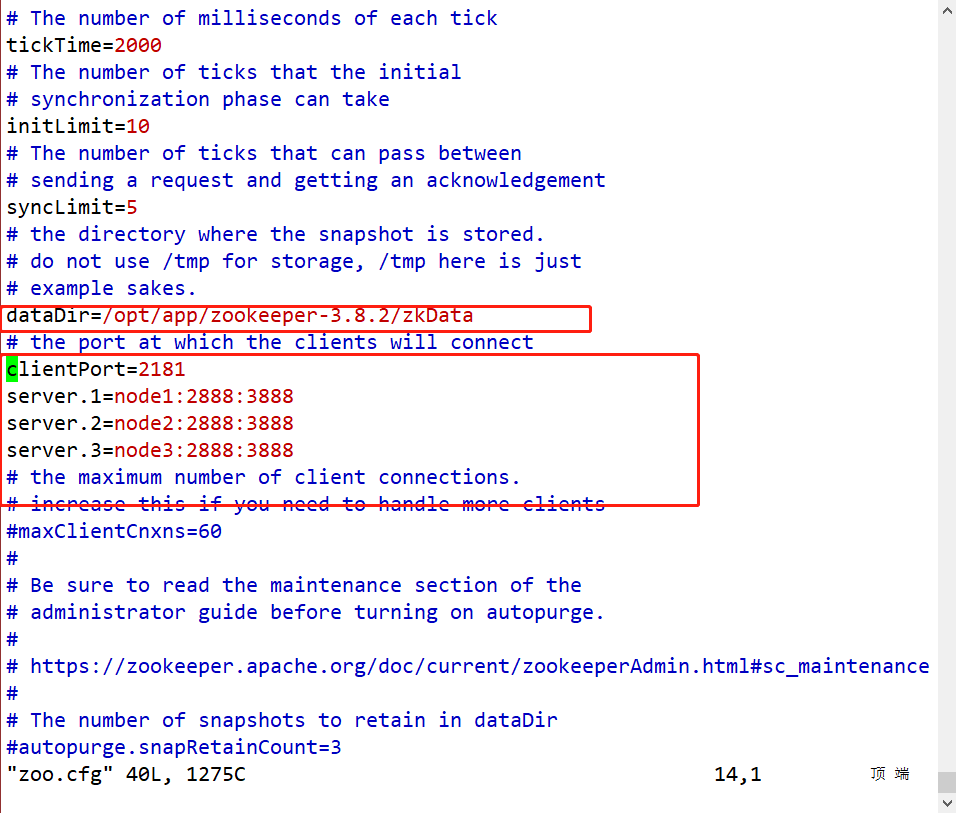
修改配置文件zoo.cfg
[root@node1 software]# vim /opt/app/zookeeper/conf/zoo.cfg
#修改dataDir数据目录
dataDir=/opt/module/zookeeper-3.8.2/zkData
#在文件最后增加如下配置
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
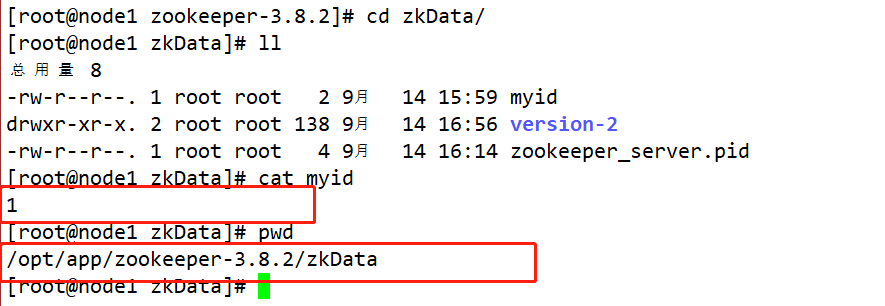
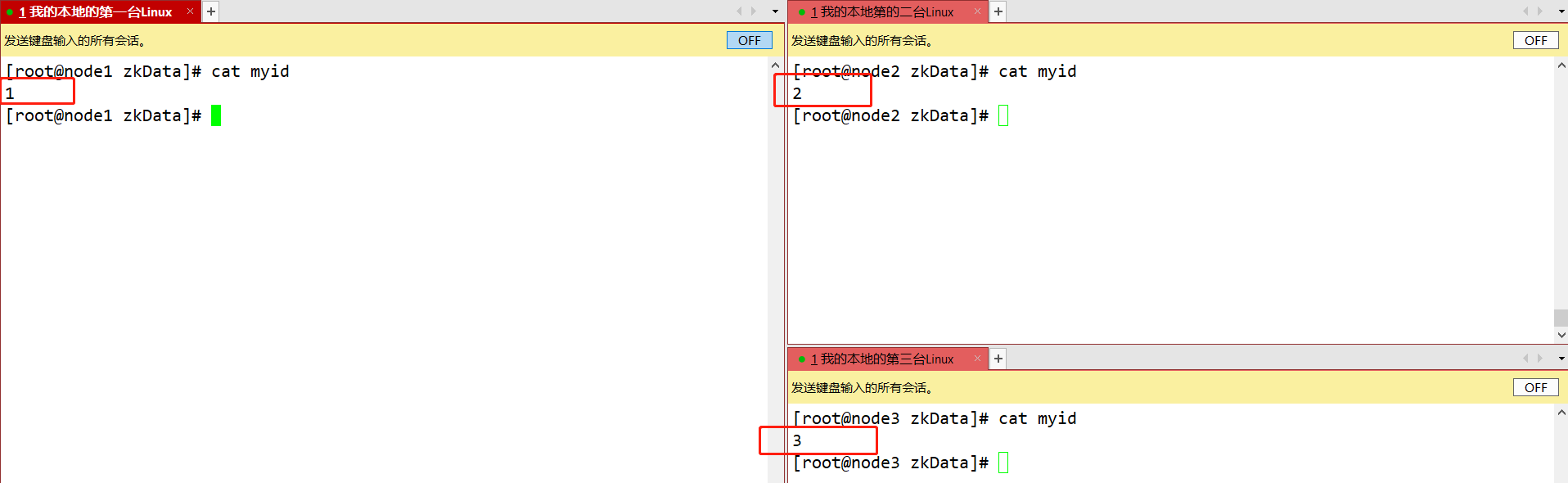
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
- 在
/opt/app/zookeeper-3.8.2下创建一个文件夹mkdir zkData,再进入此目录创建文件touch myid定义当前主机的编号。
#在配置zoo.cfg的时候配置了server.1/2/3这个配置项中 数字123代表的就是第几号服务器
#其中这个数字必须在zookeeper的zkData的myid文件中定义 并且定义的时候必须和配置项对应的IP相互匹配
[root@node1 zookeeper]# touch /opt/app/zookeeper/zkData/myid
[root@node1 zookeeper]# vim /opt/app/zookeeper/zkData/myid
#文件中写入当前主机对应的数字 然后保存退出即可 例 node1节点的myid写入1 node2节点的myid写入:2 node3节点的myid写入:3
-
拷贝配置好的zookeeper到其他机器上
scp -r /opt/app/zookeeper-3.8.2/ root@node2:/opt/app/ scp -r /opt/app/zookeeper-3.8.2/ root@node3:/opt/app/ 并分别修改myid文件中内容为2、3
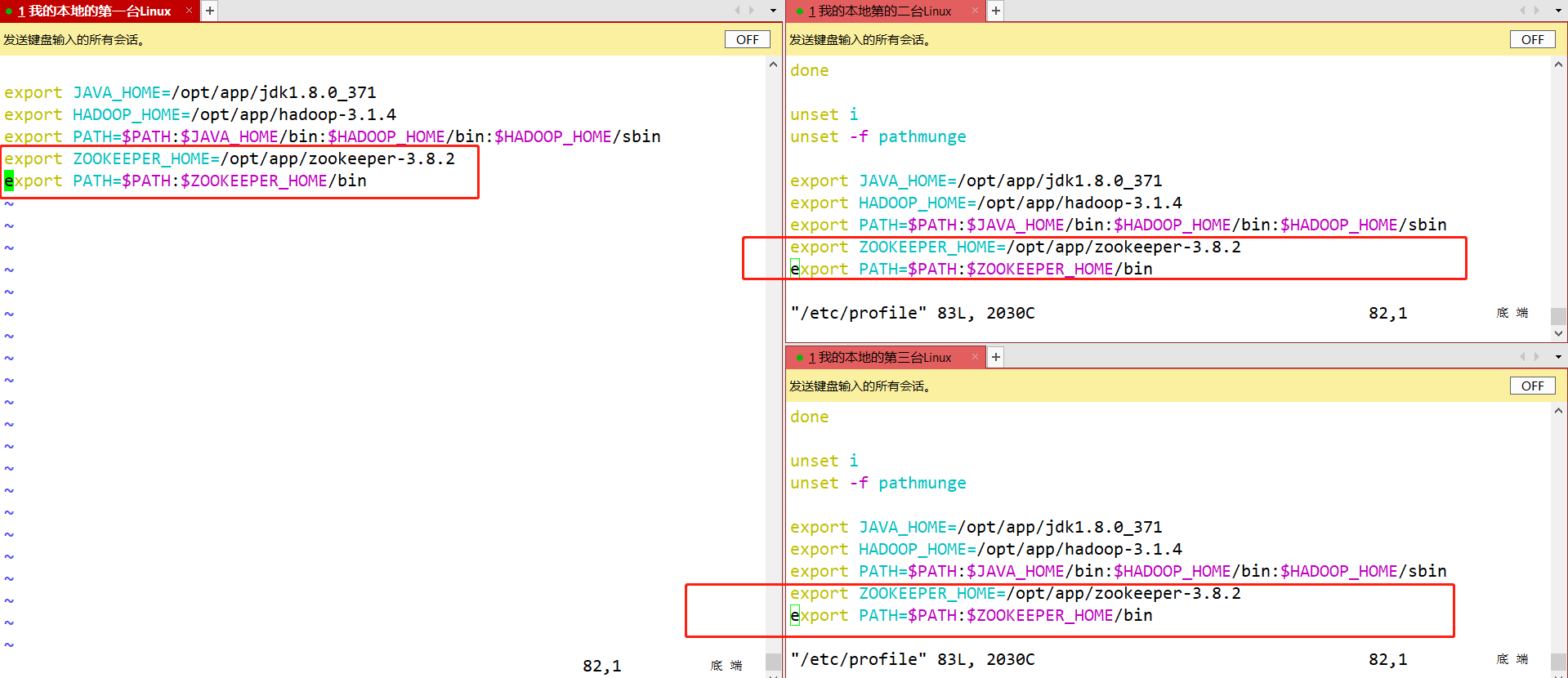
- 将node2、node3节点上的zookeeper所需的环境变量进行配置。
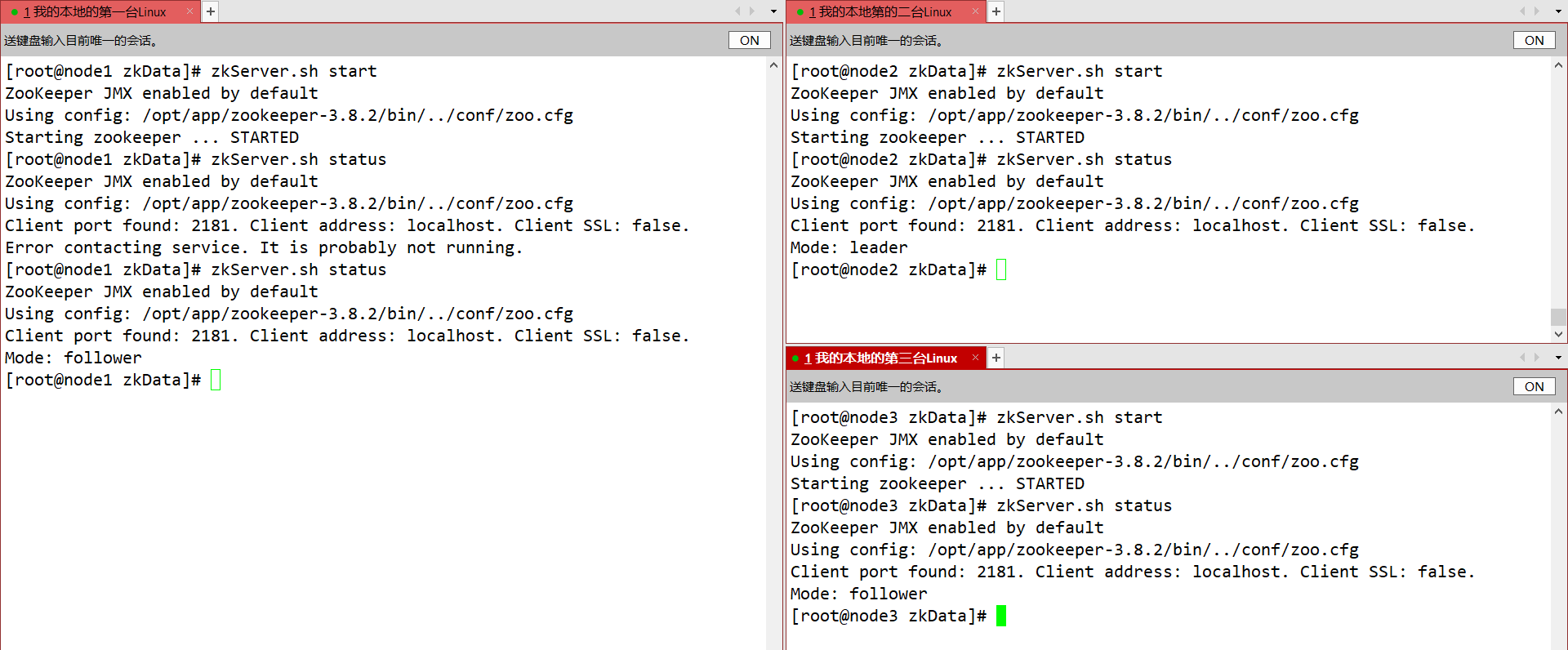
- 分别启动zookeeper并查看状态
三、zookeeper的内部实现原理
1、选举机制
- 半数机制(Paxos协议):集群中半数以上机器存活,集群可用。所以zookeeper适合装在奇数台机器上。
- Zookeeper虽然在配置文件中并没有指定master和slave。但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通过内部的选举机制临时产生的
1、Zookeeper第一次启动的选举机制
-
Zookeeper的内部选举机制
-
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动, 他们内部的实现过程如图所示
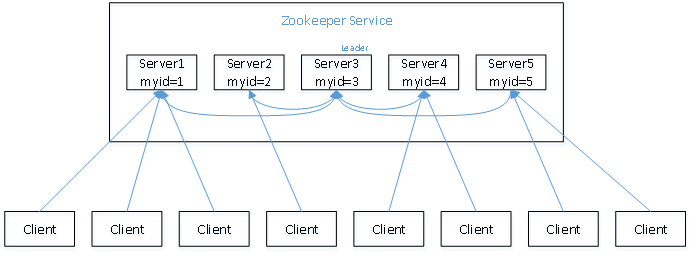
- 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态。
- 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
- 服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader。
- 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
- 服务器5启动,同4一样当小弟。
-
2、zookeeper非第一次启动的选举机制
- SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
- ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。
- Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加

2、Zookeeper写数据流程
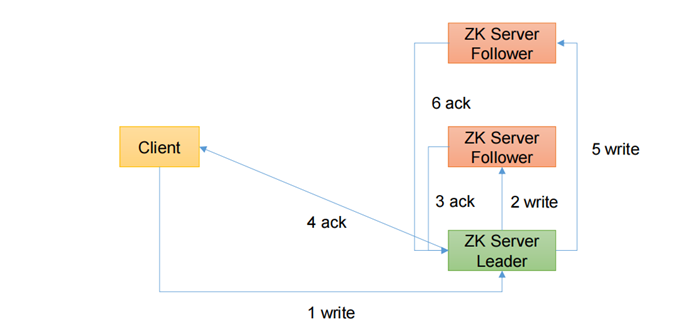
1、直接写Leader节点的流程
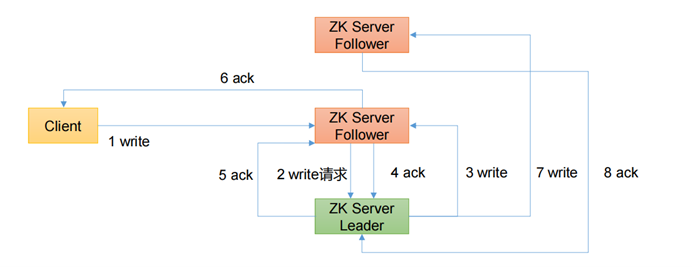
2、直接写Follower的流程
3、写数据流程的详细概述
- 比如 Client 向 ZooKeeper 的 Server1 上写数据,发送一个写请求。
- 如果Server1不是Leader,那么Server1 会把接受到的请求进一步转发给Leader,因为每个ZooKeeper的Server里面有一个是Leader这个Leader 会将写请求广播给各个Server,比如Server1和Server2, 各个Server写成功后就会通知Leader。
- 当Leader收到大多数 Server 数据写成功了,那么就说明数据写成功了。如果这里三个节点的话,只要有两个节点数据写成功了,那么认为数据写成功了。写成功之后,Leader会告诉Server1数据写成功了。
- Server1会进一步通知 Client 数据写成功了,这时就认为整个写操作成功。ZooKeeper 整个写数据流程就是这样的。
四、Zookeeper的客户端命令行操作
- 使用命令,连接zookeeper集群
zkCli.sh -server node:2181,node2:2181,node3:2181
1、命令行语法
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path [watch] | 使用 ls 命令来查看当前znode中所包含的内容 |
| ls -s path [watch] | 查看当前节点信息 |
| create [-e] [-s] | 创建节点 -s 含有序列 -e 临时(重启或者超时消失) |
| get path [watch] | 获得节点的值 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| rmr/deleteall | 递归删除节点 |
2、命令行基本操作
-
启动命令行客户端
zkCli.sh -server node1:2181,node2:2181,node3:2181
-
显示所有操作命令
help

-
查看znode节点信息
ls /
-
查看znode某节点的详细信息
[zk: node1:2181(CONNECTED) 5] ls -s / [zookeeper]cZxid = 0x0 ctime = Thu Jan 01 08:00:00 CST 1970 mZxid = 0x0 mtime = Thu Jan 01 08:00:00 CST 1970 pZxid = 0x0 cversion = -1 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 1 (1)czxid:创建节点的事务 zxid 每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。事务 ID 是 ZooKeeper 中所 有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之前发生。 (2)ctime:znode 被创建的毫秒数(从 1970 年开始) (3)mzxid:znode 最后更新的事务 zxid (4)mtime:znode 最后修改的毫秒数(从 1970 年开始) (5)pZxid:znode 最后更新的子节点 zxid (6)cversion:znode 子节点变化号,znode 子节点修改次数 (7)dataversion:znode 数据变化号 (8)aclVersion:znode 访问控制列表的变化号 (9)ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是 临时节点则是 0。 (10)dataLength:znode 的数据长度 (11)numChildren:znode 子节点数量 -
创建普通节点(永久节点 + 不带序号)
create /sanguo "weishuwu"
-
获得节点的值
get -s /test -
创建带序号的节点(永久节点 + 带序号)
create -s /a create -s /a create /a 如果原来没有序号节点,序号从 0 开始依次递增。如果原节点下已有 2 个节点,则再排序时从 2 开始,以此类推。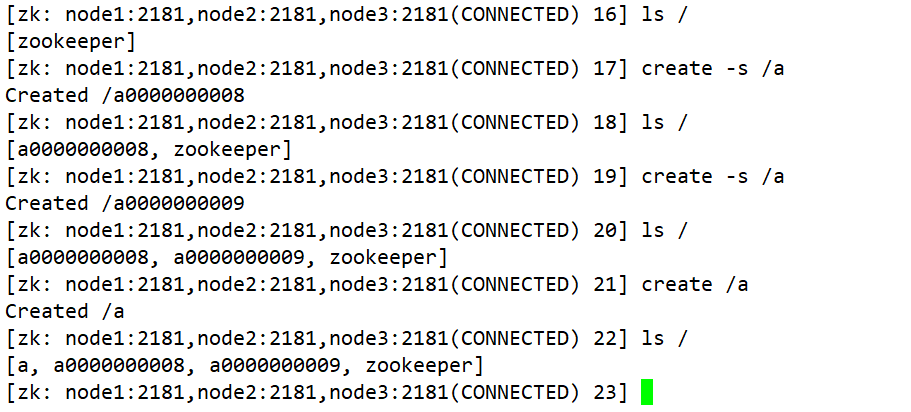
-
创建短暂节点(短暂节点 + 不带序号 or 带序号)
(1)创建短暂的不带序号的节点 create -e /b (2)创建短暂的带序号的节点 create -e -s /b (3)在当前客户端是能查看到的 ls / (4)退出当前客户端然后再重启客户端 [zk: node1:2181(CONNECTED) 12] quit [root@node1 zookeeper-3.5.7]$ bin/zkCli.sh (5)再次查看根目录下短暂节点已经删除 ls /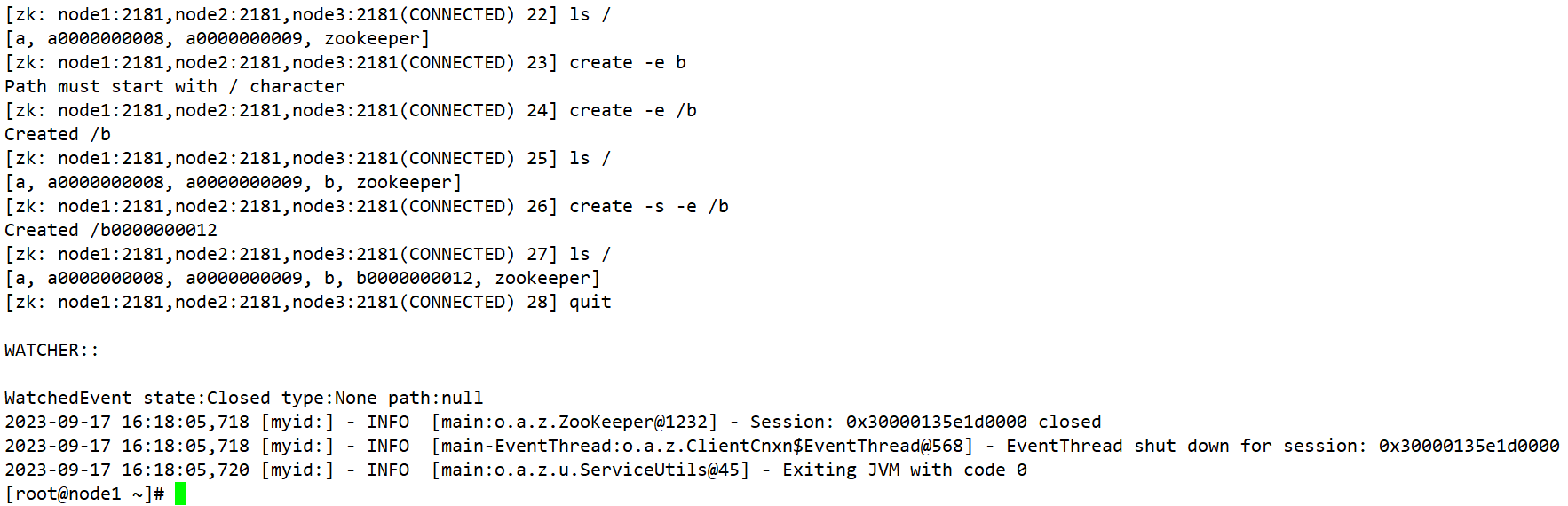
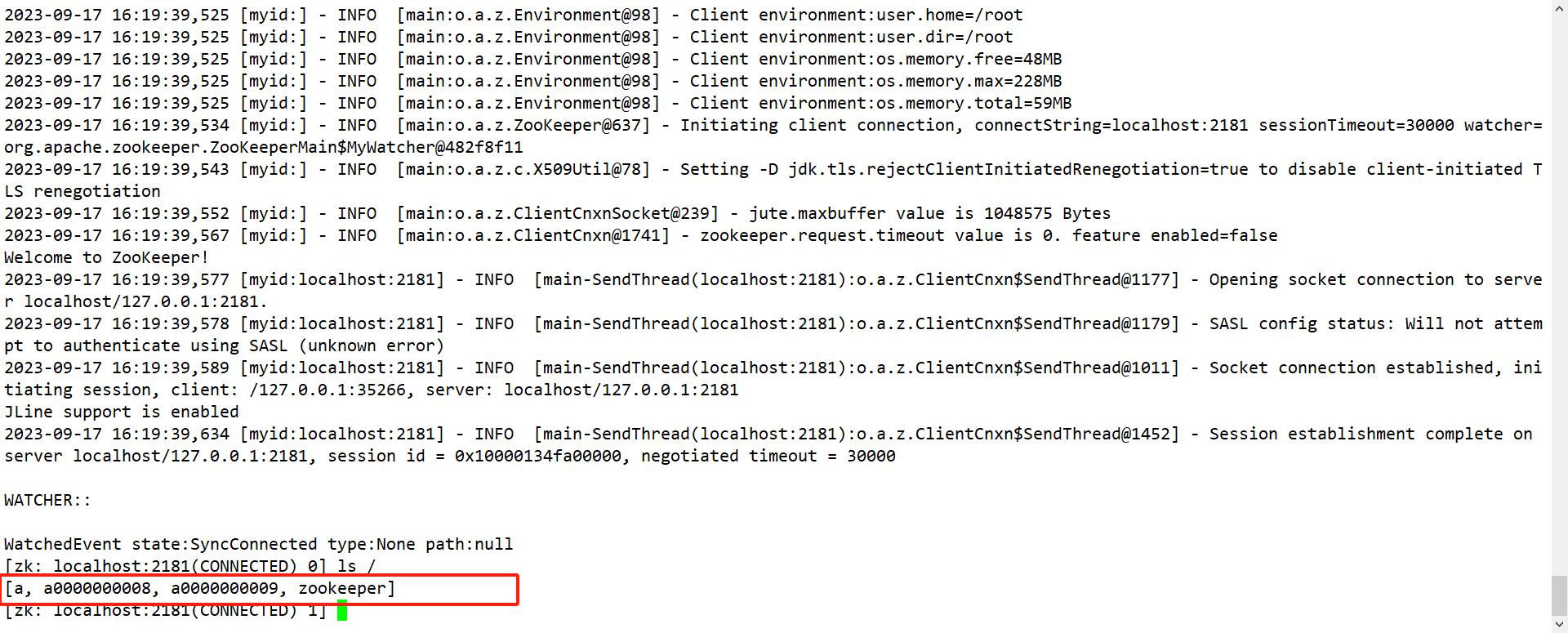
-
修改节点数据值
[zk: node1:2181(CONNECTED) 6] set /sanguo/weiguo "simayi" -
删除节点
delete /test -
递归删除节点
deleteall /test
-
查看节点状态
stat /sanguo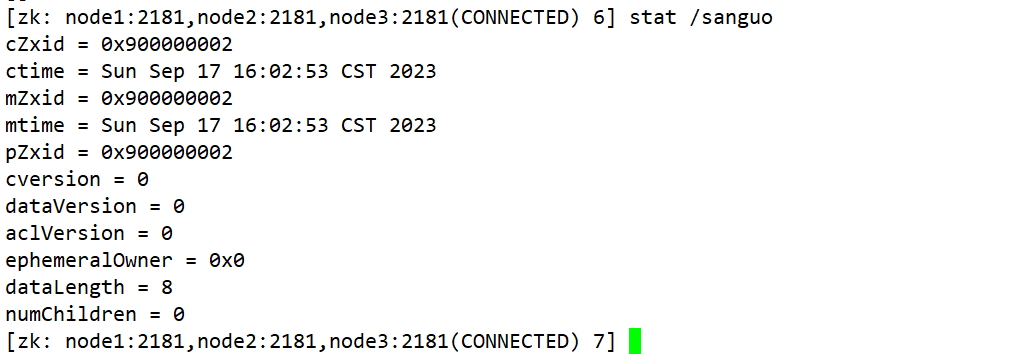
13.监听节点的数据变化
get -w /sanguo
14.监听节点的子节点变化
ls -w /sanguo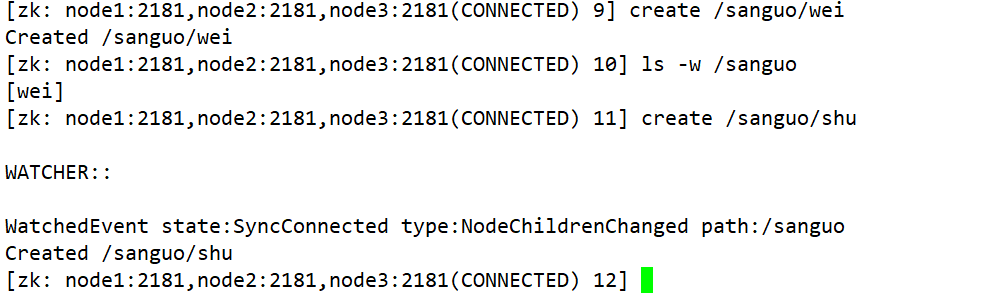
五、高可用HA-Hadoop集群的搭建
1、高可用HA概述
- 所谓HA(high available),即高可用(7*24小时不中断服务)。
- 实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
- Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
- NameNode主要在以下两个方面影响HDFS集群:
- NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启。
- NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用。
- HDFS HA功能通过配置Active/Standby两个nameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
2、HDFS-HA工作机制:通过双namenode消除单点故障
-
HDFS-HA工作要点
-
元数据管理方式需要改变(不需要SecondaryNameNode)
内存中各自保存一份元数据; Edits日志只有Active状态的namenode节点可以做写操作; 两个namenode都可以读取edits; 共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现); -
需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在namenode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。 -
必须保证两个NameNode之间能够ssh无密码登录。
-
隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务。
-
3、HDFS-HA集群配置
-
环境准备:
-
修改IP
-
修改主机名及主机名和IP地址的映射
-
关闭防火墙
-
ssh免密登录
-
安装JDK,配置环境变量等
-
-
规划集群
| node1 | node2 | node3 |
|---|---|---|
| NameNode | NameNode | - |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| ResourceManager | ||
| NodeManager | NodeManager | NodeManager |
-
配置Zookeeper集群:在上面的笔记中已经记录过!
-
配置HDFS-HA集群:
-
配置hadoop-env.sh
export JAVA_HOME=/opt/app/jdk -
配置core-site.xml
<configuration> <!-- 把两个NameNode的地址组装成一个集群HadoopCluster --> <property> <name>fs.defaultFS</name> <value>hdfs://HC</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/app/hadoop-3.1.4/metaData</value> </property> <!--配置连接的zookeeper的地址--> <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> </configuration>

-
配置hdfs-site.xml
<configuration> <!-- 完全分布式集群名称 --> <property> <name>dfs.nameservices</name> <value>HC</value> </property> <!-- 集群中NameNode节点都有哪些 --> <property> <name>dfs.ha.namenodes.HC</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.HC.nn1</name> <value>node1:9000</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.HC.nn2</name> <value>node2:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.HC.nn1</name> <value>node1:9870</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.HC.nn2</name> <value>node2:9870</value> </property> <!-- 指定NameNode元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1:8485;node2:8485;node3:8485/HadoopCluster</value> </property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要ssh无秘钥登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 声明journalnode服务器存储目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/app/hadoop-3.1.4/journalnodeData</value> </property> <!-- 关闭权限检查--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property> <!-- 访问代理类:client,HadoopCluster,active配置失败自动切换实现方式--> <property> <name>dfs.client.failover.proxy.provider.HC</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>true</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration> -
拷贝配置好的hadoop环境到其他节点
scp /opt/app/hadoop-3.1.4/etc/hadoop/core-site.xml root@node2:/opt/app/hadoop-3.1.4/etc/hadoop/ scp /opt/app/hadoop-3.1.4/etc/hadoop/core-site.xml root@node3:/opt/app/hadoop-3.1.4/etc/hadoop/ scp /opt/app/hadoop-3.1.4/etc/hadoop/hdfs-site.xml root@node3:/opt/app/hadoop-3.1.4/etc/hadoop/ scp /opt/app/hadoop-3.1.4/etc/hadoop/hdfs-site.xml root@node2:/opt/app/hadoop-3.1.4/etc/hadoop/ -
-
启动HDFS-HA集群
- 安装psmisc软件
zkfc的自动故障转移需要借助psmisc软件完成,因此需要在三个节点上安装这个软件
yum install -y psmisc
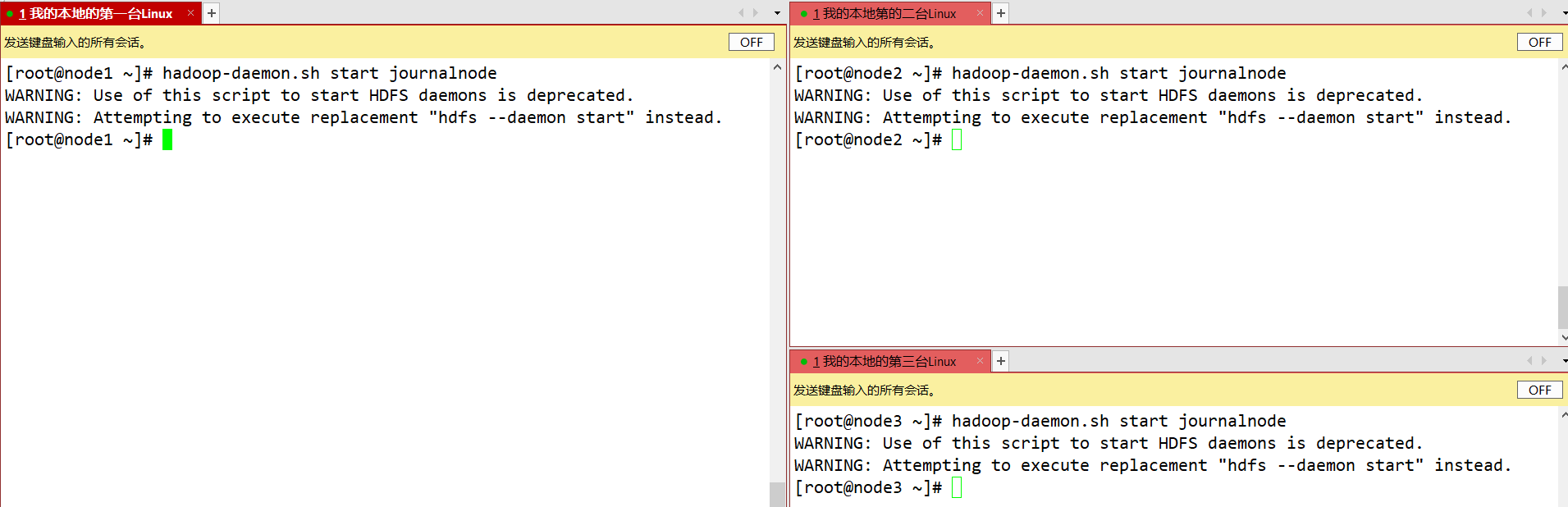
- 在各个JournalNode节点上,输入以下命令启动journalnode服务:
sbin/hadoop-daemon.sh start journalnode
- 在[nn1]上,对其进行格式化,并启动:
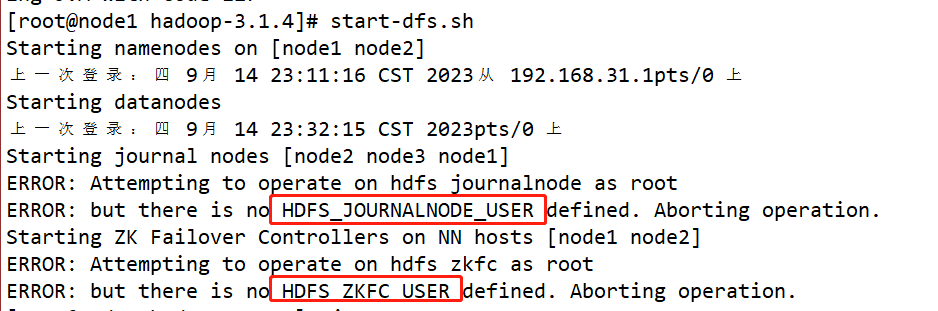
rm -rf metaData/ journalnodeData/ 删除三台节点 /opt/app/hadoop-3.1.4 hdfs namenode -format 只需要在第一台节点格式化 hadoop-daemon.sh start namenode 只需要执行一次即可,之后就不需要再执行-
遇到报错,如图
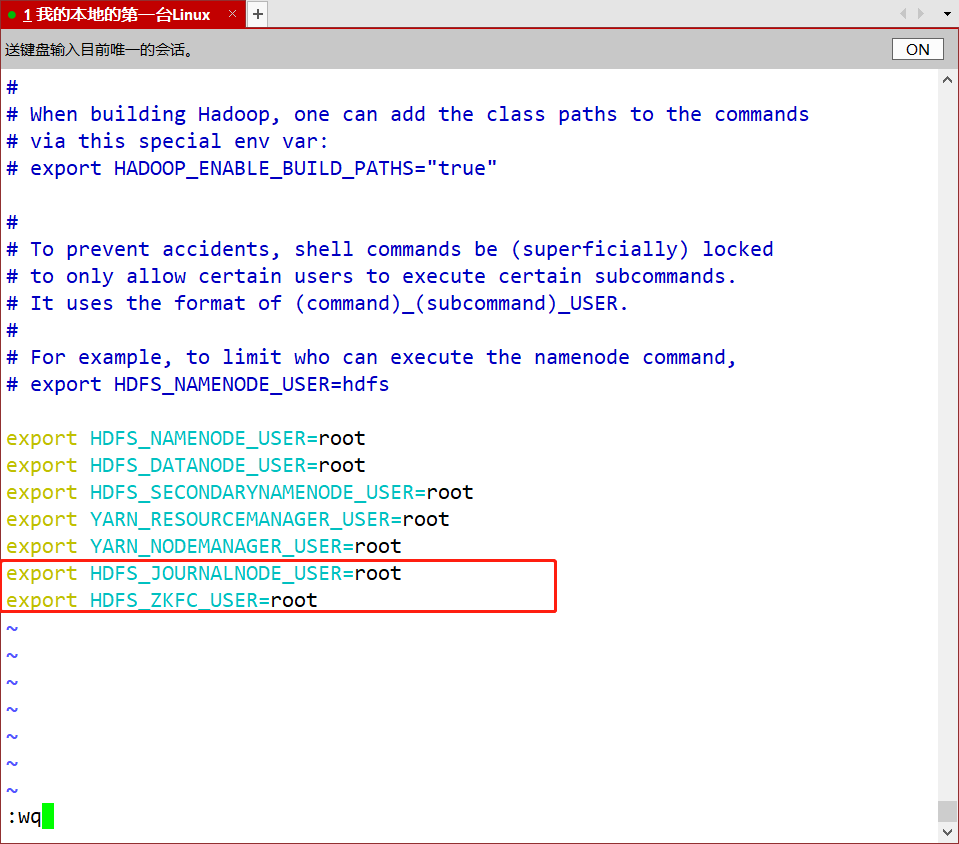
- vim /opt/app/hadoop-3.1.4/etc/hadoop/hadoop-env.sh
- scp /opt/app/hadoop-3.1.4/etc/hadoop/hadoop-env.sh root@node2:/opt/app/hadoop-3.1.4/etc/hadoop/
- scp /opt/app/hadoop-3.1.4/etc/hadoop/hadoop-env.sh root@node3:/opt/app/hadoop-3.1.4/etc/hadoop/

- 启动
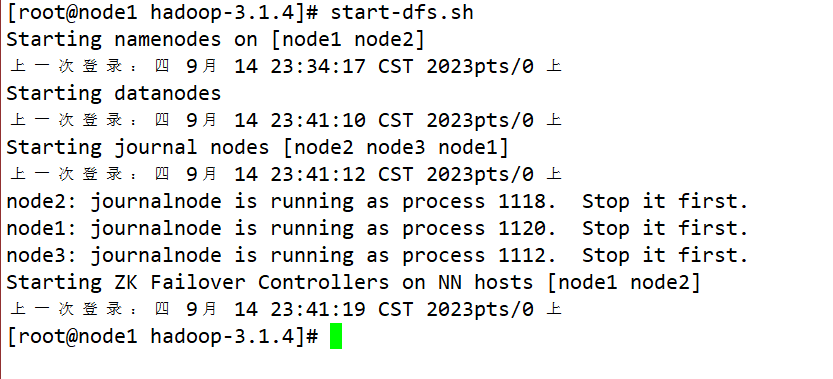
start-dfs.sh
-
在[nn2]上,同步nn1的元数据信息:
bin/hdfs namenode -bootstrapStandby只需要执行一次即可,之后就不需要再执行;hadoop-daemon.sh start namenode并在第二台节点上启动namenode -
在三台节点上启动datanode
hadoop-daemon.sh start datanode -
重新启动HDFS
- 关闭所有HDFS服务:sbin/stop-dfs.sh
- 启动Zookeeper集群:bin/zkServer.sh start
- 初始化HA在Zookeeper中状态:bin/hdfs zkfc -formatZK
- 启动HDFS服务:sbin/start-dfs.sh
- 在各个NameNode节点上启动DFSZK Failover Controller,先在哪台机器启动,哪个机器的NameNode就是Active NameNode:sbin/hadoop-daemin.sh start zkfc
-
验证
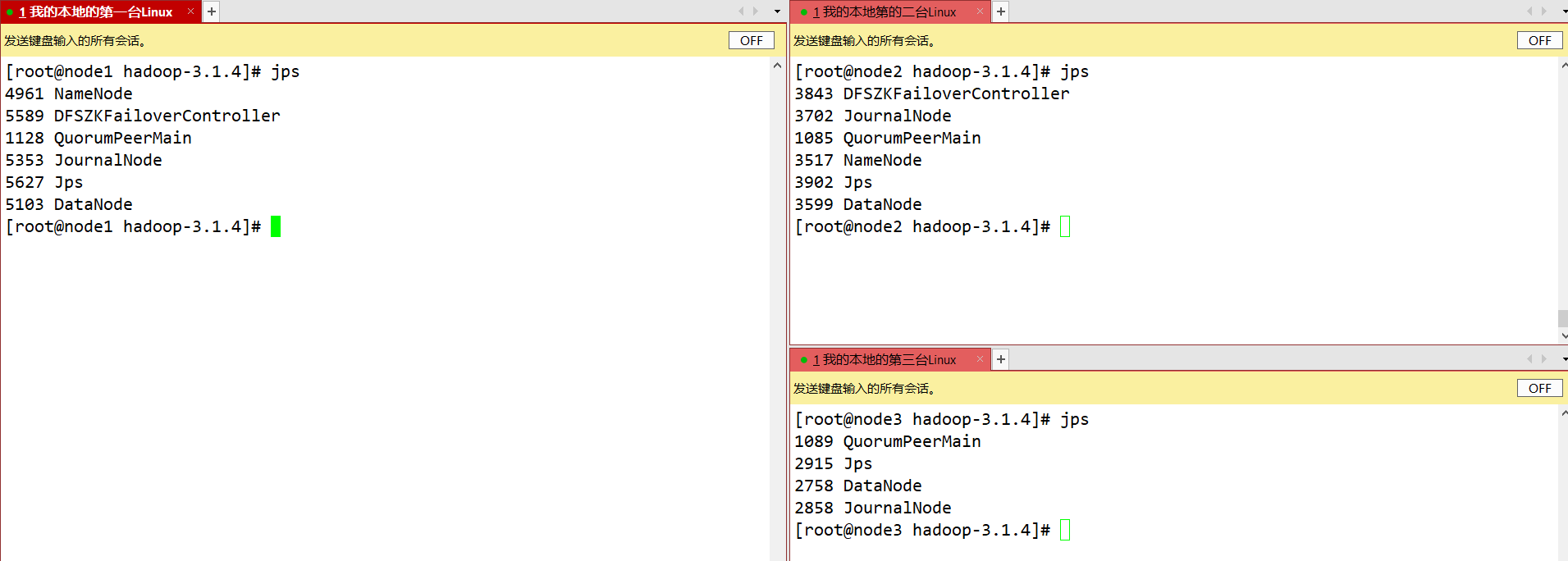
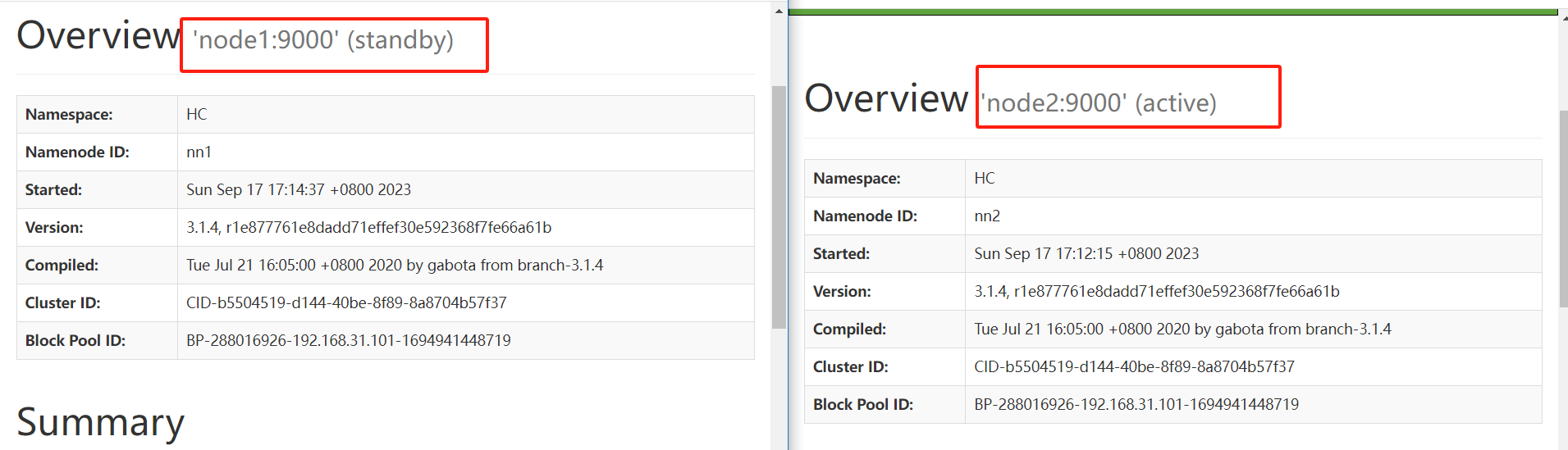
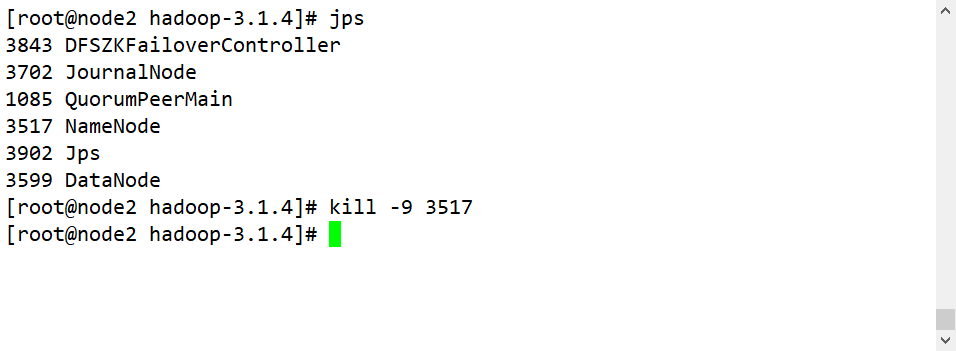
- 将Active NameNode进程kill:kill -9 namenode的进程id
- 将Active NameNode机器断开网络:service network stop
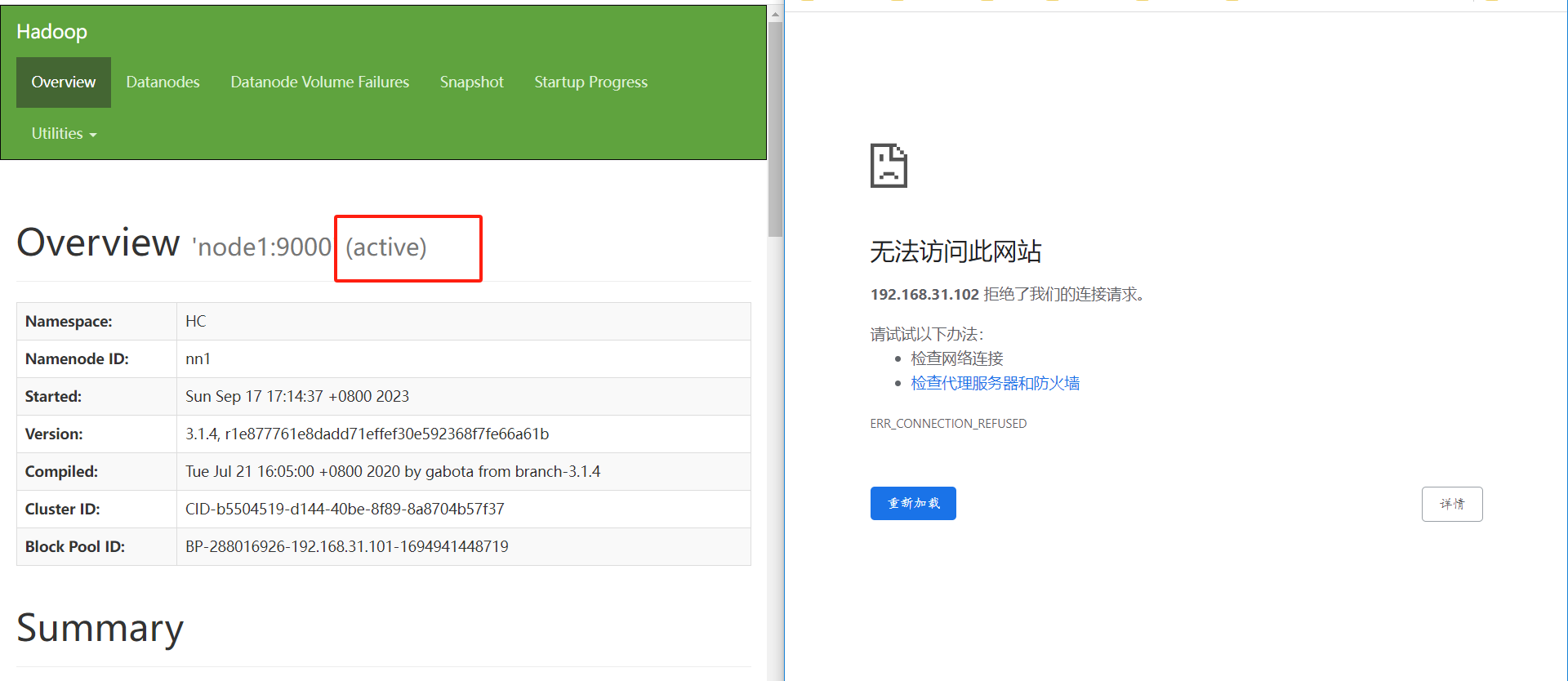
六、YARN-HA配置
配置YARN-HA集群
- 环境准备
- 修改IP
- 修改主机名及主机名和IP地址的映射
- 关闭防火墙
- ssh免密登录
- 安装JDK,配置环境变量等
- 配置Zookeeper集群
- 规划集群
| node1 | node2 | node3 |
|---|---|---|
| NameNode | NameNode | |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
-
具体配置 —— 在每个节点上进行配置
-
yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--启用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--声明两台resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node2</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的状态信息存储在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration> -
同步更新其他节点的配置信息
-
scp /opt/app/hadoop-3.1.4/etc/hadoop/yarn-site.xml root@node2:/opt/app/hadoop-3.1.4/etc/hadoop/ scp /opt/app/hadoop-3.1.4/etc/hadoop/yarn-site.xml root@node3:/opt/app/hadoop-3.1.4/etc/hadoop/
-
-
-
启动hdfs (本步骤可以不做,如果搭建过HA-Hadoop集群)
-
在各个JournalNode节点上,输入以下命令启动journalnode服务:sbin/hadoop-daemon.sh start journalnode
-
在[nn1]上,对其进行格式化,并启动:
bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode -
在[nn2]上,同步nn1的元数据信息:bin/hdfs namenode -bootstrapStandby
-
启动[nn2]:sbin/hadoop-daemon.sh start namenode
-
启动所有datanode:sbin/hadoop-daemons.sh start datanode
-
将[nn1]切换为Active:bin/hdfs haadmin -transitionToActive nn1
-
-
启动yarn
- 在node1中执行:sbin/start-yarn.sh
- 在node2中执行:sbin/yarn-daemon.sh start resourcemanager
- 查看服务状态:bin/yarn rmadmin -getServiceState rm1

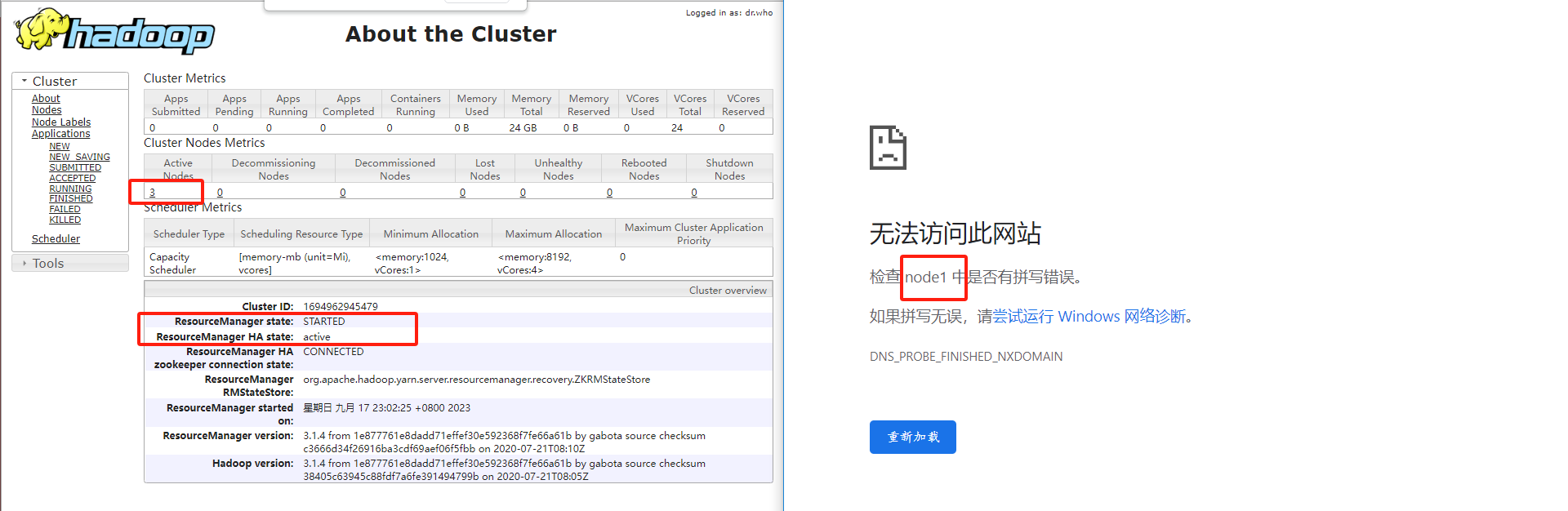
七、在高可用环境下如何用MR程序做单词计数
编辑一下wc.txt,上传到hdfs上

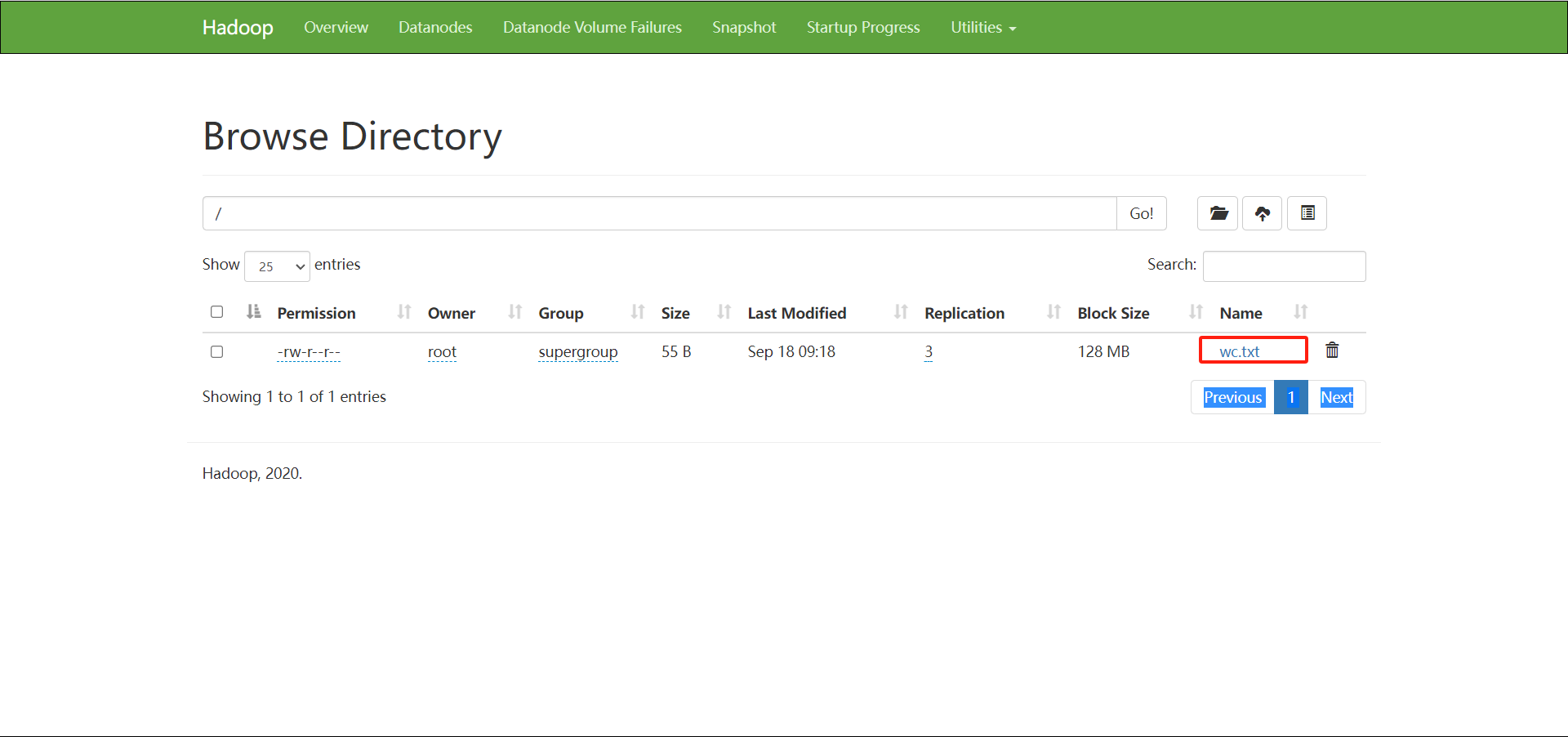
打开idea,创建一个maven项目,引入编程依赖于pom.xml中
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.kang</groupId>
<artifactId>ha-test</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>ha-test</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>
</project>
编写MapReduce代码
package com.kang;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WCMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
context.write(new Text(word),new LongWritable(1L));
}
}
}
package com.kang;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WCReduce extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0L;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key,new LongWritable(sum));
}
}
package com.kang;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import javax.xml.soap.Text;
import java.io.IOException;
public class WCDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://HC");
Job job = Job.getInstance(conf);
job.setJarByClass(WCDriver.class);
FileInputFormat.setInputPaths(job,new Path("/wc.txt"));
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setReducerClass(WCReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setNumReduceTasks(0);
FileOutputFormat.setOutputPath(job,new Path("/output"));
boolean flag = job.waitForCompletion(true);
System.exit(flag?0:1);
}
}
将hdfs-site.xml和core-site.xml从虚拟机上导出到Java项目目录下
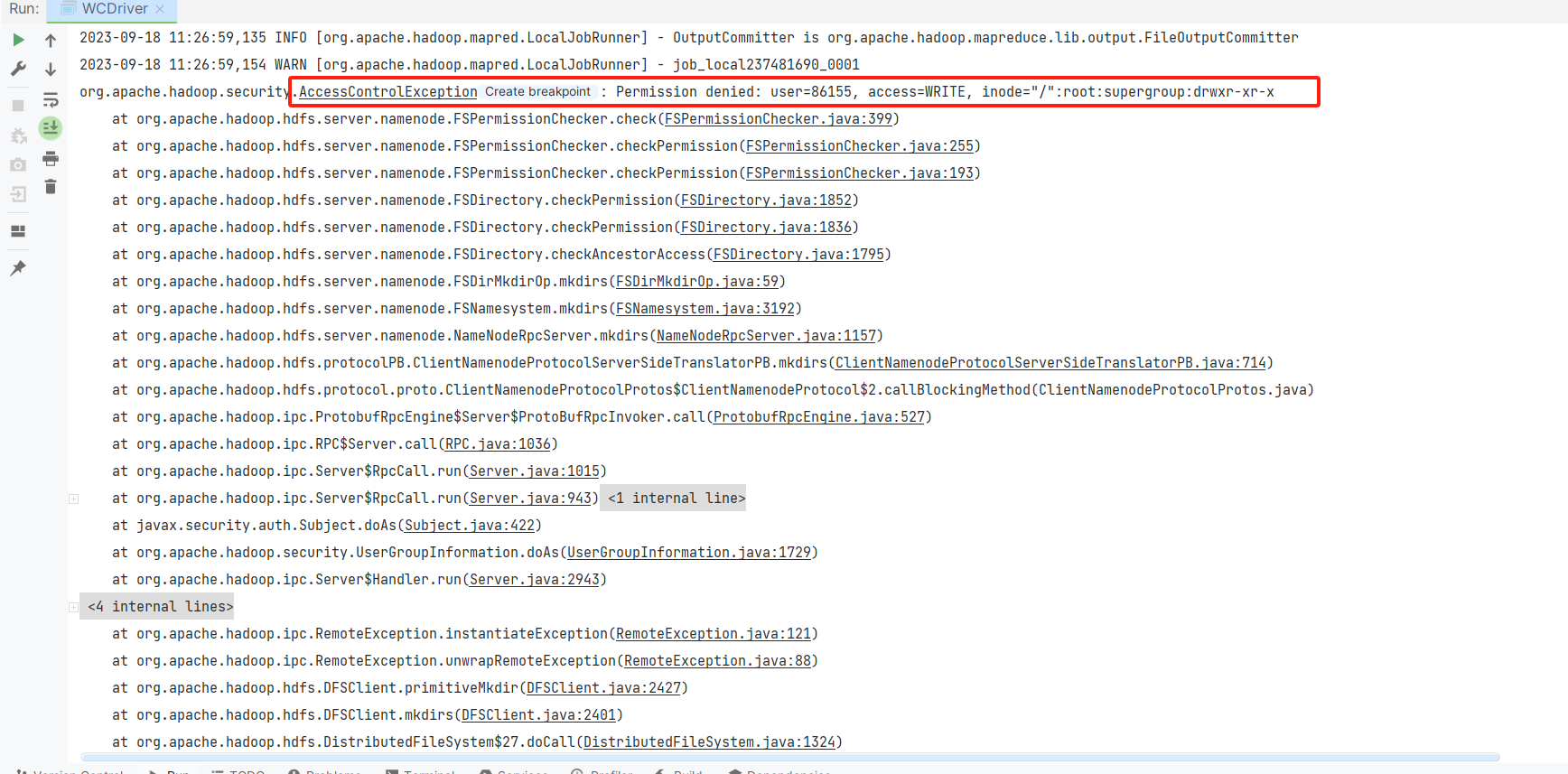
然后运行WCDriver,会收到报错信息,会显示权限不足,然后我们为了实现这一任务,我们将权限进行修改

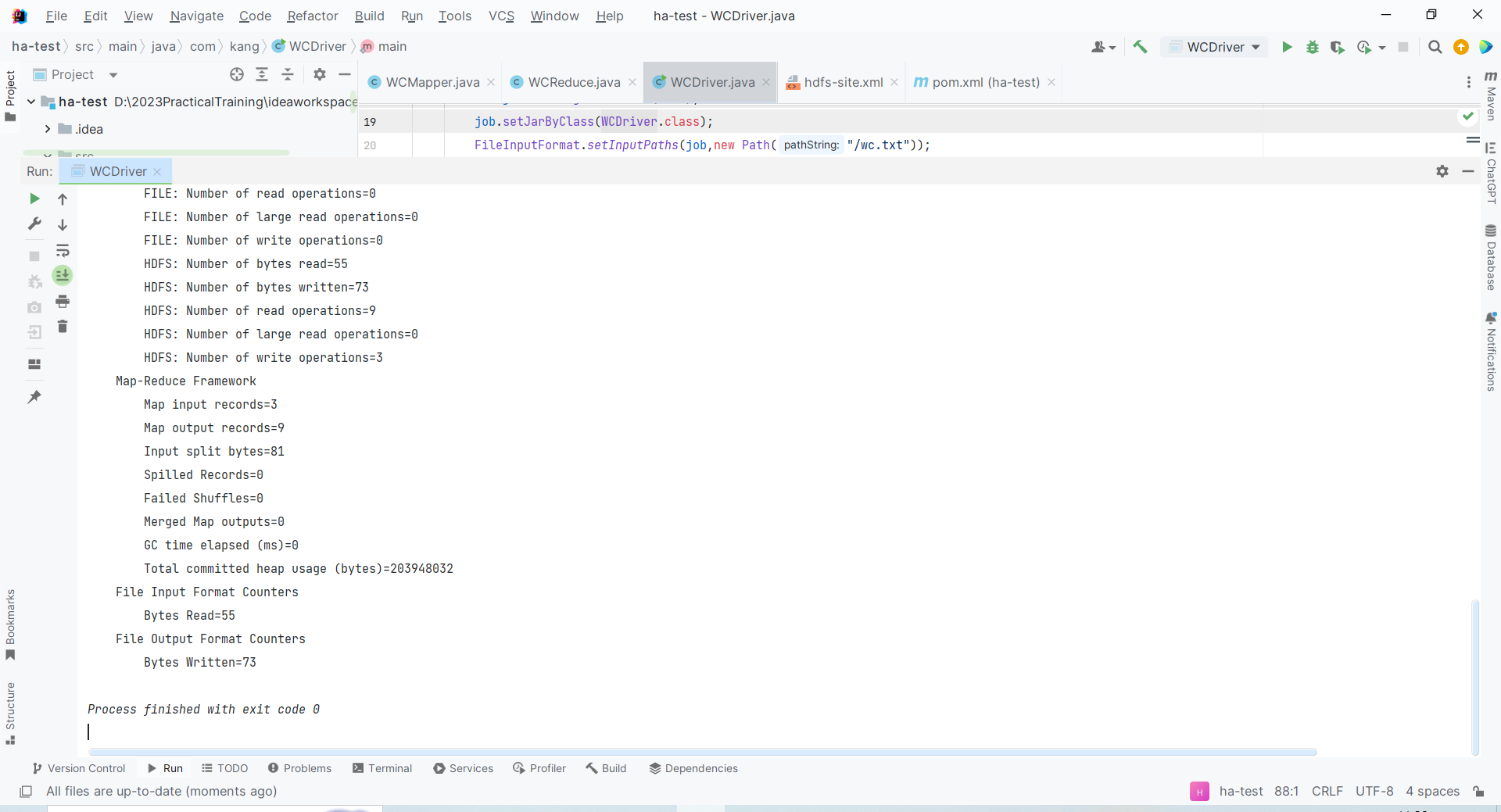
再次运行程序,返回代码0,即运行成功
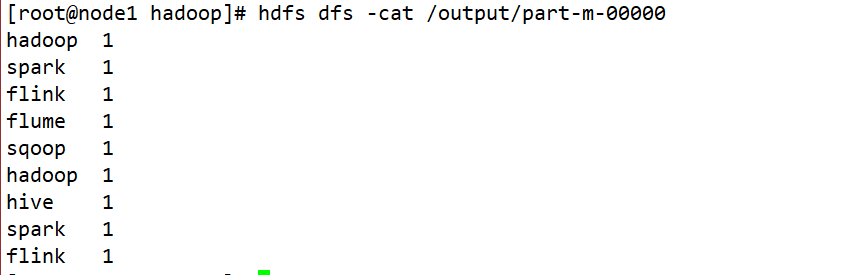
最后,我们将Hadoop分布式文件系统(HDFS)中文件和目录的默认权限恢复到默认权限类型
