目录
前言
使用代理IP,这是爬虫/反爬虫的利器,通常也是最好用的。
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
扫描二维码关注公众号,回复:
3414579 查看本文章

所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
获取IP
本次主要爬取普通IP,感谢西刺网
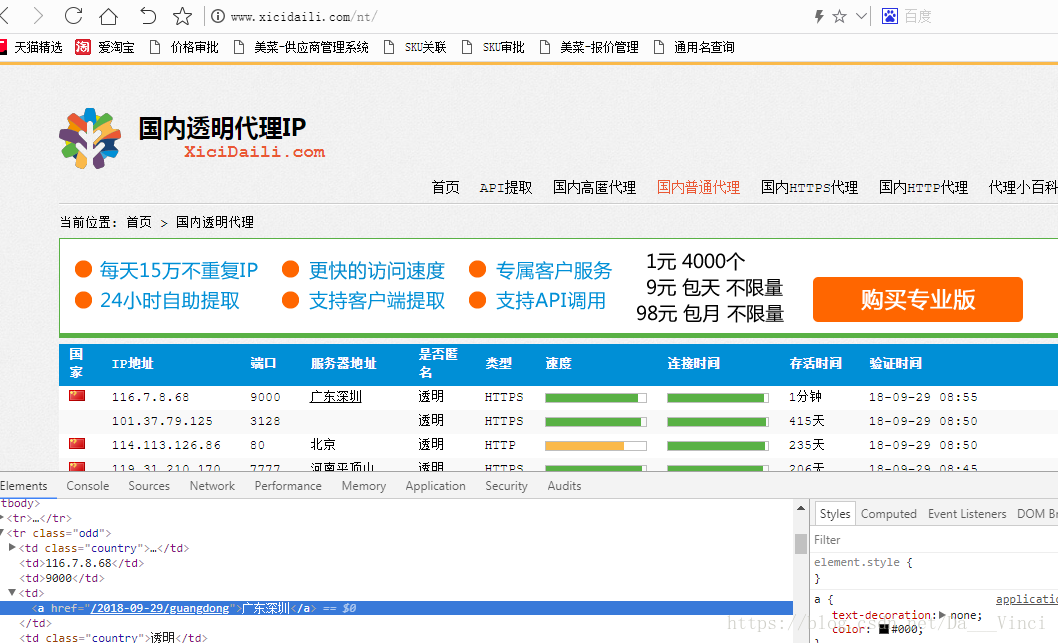
下面是完整获取代码,请求头如果想用自己的,就找到网页体文件,更换对应header即可
项目文件
西刺并没有反爬虫,只要不大量索取就不会被Ban,这里我们也只抓了3页的IP,后面对抓到的IP进行了筛选,去掉了存活时间小于
1天和延迟过高的IP.
# -*- coding:UTF-8 -*-
import requests
from bs4 import BeautifulSoup
from lxml import etree
import re
import string
import json
#从西刺网爬取id
def ipCrawl(page):
#requests的Session可以自动保持cookie,不需要自己维护cookie内容
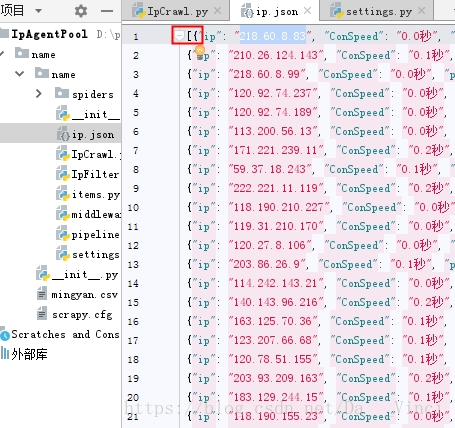
filename = 'D:\python\IpAgentPool\\name\\name\ip.json' # 储存位置
count = 0
for i in range(1,page+1):
reqSession = requests.Session()
url = 'http://www.xicidaili.com/nt/%d' % i # 普通ip
headers = {'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'http://www.xicidaili.com/nn/',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
response_text = reqSession.get(url = url, headers = headers)
response_text.encoding = 'utf-8'
rephtml = response_text.text
mainForm = BeautifulSoup(rephtml, 'lxml')
tableForm = BeautifulSoup(str(mainForm.find_all(id='ip_list')), 'lxml')
List_ip = tableForm.table.contents
pattern1 = re.compile(r'\d.\d')
pattern2 = re.compile(r'u.*')
pattern3 = re.compile(r'\d+')
_json = dict()
for index in range(len(List_ip)):
if index % 2 == 1 and index != 1:
dom = etree.HTML(str(List_ip[index]))
LiveTime = dom.xpath('//td[9]')[0].text
LiveTime1 = pattern2.search(LiveTime).group()
ConSpeed = dom.xpath('//td[7]/div/@title')[0]
ConSpeed1 = pattern1.search(ConSpeed).group()
if LiveTime1 == "u5929" :
if string.atof(ConSpeed1) <0.3: #取掉生存天数过小和响应时间过长的ip
count = count+1
_json["ip"] = dom.xpath('//td[2]')[0].text
_json["port"] = dom.xpath('//td[3]')[0].text
_json["protocol"] = dom.xpath('//td[6]')[0].text
_json["LiveTime"] = pattern3.search(LiveTime).group()+'天'
_json["ConSpeed"] = ConSpeed1+'秒'
with open(filename, 'a') as outfile: # 追加模式
json.dump(_json, outfile, ensure_ascii=False)
with open(filename, 'a') as outfile:
outfile.write(',\n')
print "第%d页爬取完成,该页%d条ip" %(i,count)
if __name__ == '__main__':
ipCrawl(3)红框的[]是手动加的,主要是为了读取方便。
其他代理网站
IP验证
在网上搜集了几种方法。
1.放到专门网站查询。


2.使用该IP访问制定网站,如果返回状态为200,表示这个代理是可以使用的。详见https://www.jianshu.com/p/588241a313e7
3.网友提供,查看IP是否可以PING通,还可以看丢包率。觉的还不错,就写了下来。
# -*- coding:UTF-8 -*-
import subprocess as sp
from lxml import etree
import requests
import random
import re
import random
import json
class IpFilter():
def __init__(self):
self.ip = ''
def check_ip(self):
cmd = "ping -n 3 -w 3 %s" # 命令 -n 要发送的回显请求数 -w 等待每次回复的超时时间(毫秒)
p = sp.Popen(cmd %self.ip, stdin=sp.PIPE, stdout=sp.PIPE, stderr=sp.PIPE, shell=True) # 执行命令
lose_time = re.compile(u"丢失 = (\d+)", re.IGNORECASE)
out = p.stdout.read().decode("gbk") # 获得返回结果并解码
print (out)
lose_time = lose_time.findall(out) # 丢包数
# 当匹配到丢失包信息失败,默认为三次请求全部丢包,丢包数lose赋值为3
if len(lose_time) == 0:
print "----------------LOST IP PACKET---------------------"
return False
else:
lose = int(lose_time[0])
if lose > 1:
return False
else:
return True
def getAndUpdateIp(self):
file1 = open('D:\python\IpAgentPool\\name\\name\ip.json', 'r') # 打开文件
jsonDict = json.load(file1) # 加载json
file1.close() # 关闭连接
index = random.randint(0, len(jsonDict)) # 随机下角标
ipRandom = jsonDict[index]["ip"] # 随机IP
print '----random IP IS----------:%s' % str(ipRandom)
# 测试ip
self.ip = ipRandom
if self.check_ip():
print '-----------------Good IP--------------'
return jsonDict[index]["protocol"]+'://'+jsonDict[index]["ip"]+':'+jsonDict[index]["port"]
else:
print '-----------------Bad IP----------------'
return False
if __name__ == '__main__':
ipf = ipFilter()
print ipf.getAndUpdateIp()

urllib2配置IP
当代理IP足够多,就可以像随机获取User-Agent一样,随机选择一个代理去访问网站。
import urllib2
import random
proxy_list = [
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"},
{"http" : "124.88.67.81:80"}
]
# 随机选择一个代理
proxy = random.choice(proxy_list)# 使用选择的代理构建代理处理器对象
httpproxy_handler = urllib2.ProxyHandler(proxy)
opener = urllib2.build_opener(httpproxy_handler)
request = urllib2.Request("http://www.baidu.com/")
response = opener.open(request)print response.read()Scrapy配置IP
常规方法:
settings.py 将大量IP添加到配置文件集合中。
IPPOOL=[
{"ipaddr":"218.82.33.225:53853"},
{"ipaddr":"218.82.33.225:53853"},
{"ipaddr":"218.82.33.225:53853"},
{"ipaddr":"218.82.33.225:53853"}
]这里把默认header和IP都设为None,因为要用自己的。中间那条是自己写的类,文件夹名+middlerwares+类名,后面数字是执行循序,有兴趣的可以去看scrapy中文文档。
DOWNLOADER_MIDDLEWARES = {
# 'myproxies.middlewares.MyCustomDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':None,
'name.middlewares.ProxyMiddleWare':125,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware':None
}middlewares.py 从配置文件随机读取,请为request对象设置参数
# -*- coding: utf-8 -*-
import random
from scrapy import signals
from myproxies.settings import IPPOOL
class MyproxiesSpiderMiddleware(object):
def __init__(self,ip=''):
self.ip=ip
def process_request(self, request, spider):
thisip=random.choice(IPPOOL)
print("this is ip:"+thisip["ipaddr"])
request.meta["proxy"]="http://"+thisip["ipaddr"]编写spider运行即可。
我的写法:
middlewares.py 从IpFilter获取的IP,如果响应不是200,继续随机获取
# -*- coding: utf-8 -*-
from IpFilter import *
from scrapy import signals
import scrapy
from scrapy import log
class ProxyMiddleWare(object):
def process_request(self, request, spider):
ipf = IpFilter().getAndUpdateIp()
request.meta['proxy'] = ipf
def process_response(self, request, response, spider):
'''对返回的response处理'''
# 如果返回的response状态不是200,重新生成当前request对象
ipf = IpFilter().getAndUpdateIp()
if response.status != 200:
proxy = ipf
print("this is response ip:" + proxy)
# 对当前reque加上代理
request.meta['proxy'] = proxy
return request
return response
spider.py
# -*- coding: utf-8 -*-
import scrapy
class mingyanSpider(scrapy.Spider):
name = "te"
start_urls = [
'http://lab.scrapyd.cn/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'内容': quote.css('span.text::text').extract_first(),
'作者': quote.xpath('span/small/text()').extract_first(),
}
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
yield scrapy.Request(next_page, self.parse)
结果: