- pytorch实现yolo-v3 (源码阅读和复现) – 001
- pytorch实现yolo-v3 (源码阅读和复现) – 002
- pytorch实现yolo-v3 (源码阅读和复现) – 003算法分析
- pytorch实现yolo-v3 (源码阅读和复现) – 004算法分析
- pytorch实现yolo-v3 (源码阅读和复现) – 005
参考:
https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
https://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch-part-2/
https://juejin.im/post/5b66a2d751882536054a74e8
运行环境:
Pytorch=0.4
Python=3.6
为了更好的理解代码, 需要读者熟悉Python以及有一定Pytorch基础,否则阅读起来会比较费力
在开始编程之前,需要先介绍一下yolov3的网络结构, 简图如下
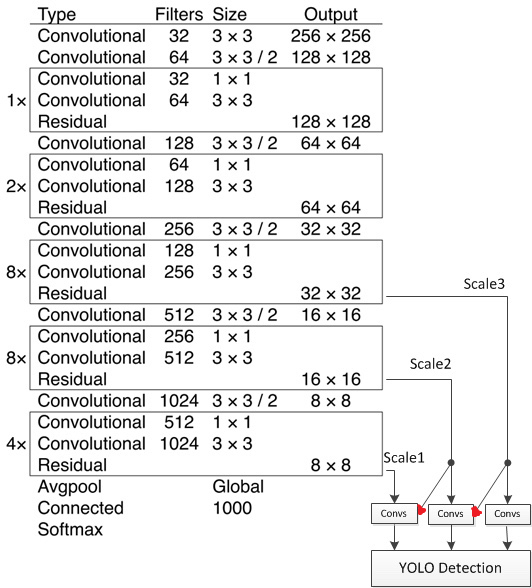
yolo v3所使用的Darknet版本是Darknet53。那么,为什么是Darknet53呢?因为Darknet53是53个卷积层和池化层的组合,与Darknet简化图一一对应,即:
53 = 2 + 1*2 + 1 + 2*2 + 1 + 8*2 + 1 + 8*2 + 1 + 4*2 + 1最后的1代表途中Avgpool层,打印具体每一层输出如下(输入是416*416大小, 分类80,每一个yolo层不同尺度锚点3组)
input= torch.Size([1, 3, 416, 416])
---2---
convolutional filters= (32, 3, 3, 3) innput= torch.Size([1, 3, 416, 416]) output= torch.Size([1, 32, 416, 416])
convolutional filters= (64, 3, 3, 3) innput= torch.Size([1, 32, 416, 416]) output= torch.Size([1, 64, 208, 208])
---1*2---
convolutional filters= (32, 3, 3, 3) innput= torch.Size([1, 64, 208, 208]) output= torch.Size([1, 32, 208, 208])
convolutional filters= (64, 3, 3, 3) innput= torch.Size([1, 32, 208, 208]) output= torch.Size([1, 64, 208, 208])
* shortcut innput= torch.Size([1, 64, 208, 208]) output= torch.Size([1, 64, 208, 208])
---1---
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 64, 208, 208]) output= torch.Size([1, 128, 104, 104])
---2*2---
convolutional filters= (64, 3, 3, 3) innput= torch.Size([1, 128, 104, 104]) output= torch.Size([1, 64, 104, 104])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 64, 104, 104]) output= torch.Size([1, 128, 104, 104])
* shortcut innput= torch.Size([1, 128, 104, 104]) output= torch.Size([1, 128, 104, 104])
convolutional filters= (64, 3, 3, 3) innput= torch.Size([1, 128, 104, 104]) output= torch.Size([1, 64, 104, 104])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 64, 104, 104]) output= torch.Size([1, 128, 104, 104])
* shortcut innput= torch.Size([1, 128, 104, 104]) output= torch.Size([1, 128, 104, 104])
---1---
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 104, 104]) output= torch.Size([1, 256, 52, 52])
---8*2---
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
* shortcut innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
* shortcut innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
* shortcut innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
* shortcut innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
* shortcut innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
* shortcut innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
* shortcut innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
* shortcut innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 256, 52, 52])
---1---
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 512, 26, 26])
---8*2---
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
* shortcut innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
* shortcut innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
* shortcut innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
* shortcut innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
* shortcut innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
* shortcut innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
* shortcut innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
* shortcut innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 512, 26, 26])
---1---
convolutional filters= (1024, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 1024, 13, 13])
---4*2---
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 512, 13, 13])
convolutional filters= (1024, 3, 3, 3) innput= torch.Size([1, 512, 13, 13]) output= torch.Size([1, 1024, 13, 13])
* shortcut innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 1024, 13, 13])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 512, 13, 13])
convolutional filters= (1024, 3, 3, 3) innput= torch.Size([1, 512, 13, 13]) output= torch.Size([1, 1024, 13, 13])
* shortcut innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 1024, 13, 13])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 512, 13, 13])
convolutional filters= (1024, 3, 3, 3) innput= torch.Size([1, 512, 13, 13]) output= torch.Size([1, 1024, 13, 13])
* shortcut innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 1024, 13, 13])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 512, 13, 13])
convolutional filters= (1024, 3, 3, 3) innput= torch.Size([1, 512, 13, 13]) output= torch.Size([1, 1024, 13, 13])
* shortcut innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 1024, 13, 13])
---1---
??????
********************************************************detetc1*************************************************
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 512, 13, 13])
convolutional filters= (1024, 3, 3, 3) innput= torch.Size([1, 512, 13, 13]) output= torch.Size([1, 1024, 13, 13])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 512, 13, 13])
convolutional filters= (1024, 3, 3, 3) innput= torch.Size([1, 512, 13, 13]) output= torch.Size([1, 1024, 13, 13])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 512, 13, 13])
convolutional filters= (1024, 3, 3, 3) innput= torch.Size([1, 512, 13, 13]) output= torch.Size([1, 1024, 13, 13])
convolutional filters= (255, 3, 3, 3) innput= torch.Size([1, 1024, 13, 13]) output= torch.Size([1, 255, 13, 13])
*** yolo innput= torch.Size([1, 255, 13, 13]) output= torch.Size([1, 507, 85])
**********************************************************detetc2**********************************************
route innput= torch.Size([1, 507, 85]) output= torch.Size([1, 512, 13, 13])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 13, 13]) output= torch.Size([1, 256, 13, 13])
### upsample innput= torch.Size([1, 256, 13, 13]) output= torch.Size([1, 256, 26, 26])
route innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 768, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 768, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (512, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 512, 26, 26])
convolutional filters= (255, 3, 3, 3) innput= torch.Size([1, 512, 26, 26]) output= torch.Size([1, 255, 26, 26])
*** yolo innput= torch.Size([1, 255, 26, 26]) output= torch.Size([1, 2028, 85])
*********************************************************detetc3************************************************
route innput= torch.Size([1, 2028, 85]) output= torch.Size([1, 256, 26, 26])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 26, 26]) output= torch.Size([1, 128, 26, 26])
### upsample innput= torch.Size([1, 128, 26, 26]) output= torch.Size([1, 128, 52, 52])
route innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 384, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 384, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (128, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 128, 52, 52])
convolutional filters= (256, 3, 3, 3) innput= torch.Size([1, 128, 52, 52]) output= torch.Size([1, 256, 52, 52])
convolutional filters= (255, 3, 3, 3) innput= torch.Size([1, 256, 52, 52]) output= torch.Size([1, 255, 52, 52])
*** yolo innput= torch.Size([1, 255, 52, 52]) 1.4904072284698486 torch.Size([1, 8])
**************************************************************************************************************
关于Darknet网络配置的部分,我们使用的是开源的项目中的网络配置文件, 在cfg/yolov3.cfg
https://github.com/ayooshkathuria/YOLO_v3_tutorial_from_scratch
内容如下, 其中”#”开头部分是注释,”[]”表示block类型;下采样通过调整卷积步长实现, 残差层结构实现在shortcut层,from参数值-n表示接受的一个输入来自前n层, 另一个来自前一层,求和的方式通道方向合并结果: 上采样部分采用的是插值法实现
[net]
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=16
width= 320
height = 320
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
# Downsample
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
######################
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 61
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 36
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=255
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
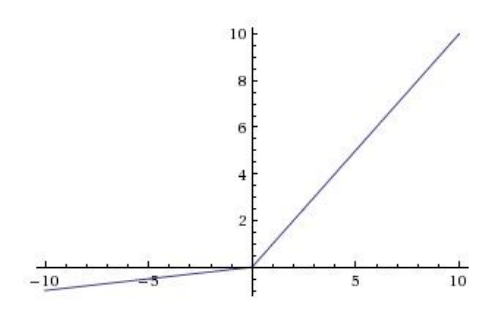
leakyRelu激活函数,图像如下,参数(负轴部分系数)negative_slope=0.1, 缺省值1e-2(pytorch)
下一篇来编程解析配置文件并搭建YOLOv3-416网络