Regression
就我现在学到的知识而言,我所目前知道的问题分两类,一类是回归分析,另一类是分类。
初学者水平较低,仅为个人学习笔记,如有纰漏,请大佬们指出~
今天所学的就是回归 Regression。1.搭建神经网络 2.定义损失函数 3.训练网络
先贴出代码
import torch
import torch.nn.functional as F #import activation fuctions(导入激活函数)
class Net(torch.nn.Module): # extends the module of torch(继承torch中的 Module 模块)
def __init__(self,n_input,n_hidden1,n_hidden2,n_output):
super(Net,self).__init__() # extends the init fuctions(继承初始化方法)
self.hidden1 = torch.nn.Linear(n_input,n_hidden1)# linear function (线性函数)
self.hidden2 = torch.nn.Linear(n_hidden1,n_hidden2)#linear function(线性函数)
self.output = torch.nn.Linear(n_hidden2,n_output)#linear function(线性函数)
def forward(self,x):# forward function (前向传播方法)
x = F.relu(self.hidden1(x))# use relu function to activate(采用 relu 激活函数)
x = F.relu(self.hidden2(x))# use relu function to activate(采用 relu 激活函数)
x = self.output(x) # output layer don't need to activate (输出层不需要激活)
return x
# now we finished the work that to make a neural network (现在就完成了神经网络的搭建)
net = Net(n_input = 1,n_hidden1 =10,n_hidden2 = 10,n_output = 1)
print(net)
# define the optimizer and loss function(定义优化器和损失函数)
optimizer = torch.optim.SGD(net.parameters(),lr = 0.2)#采用Stochastic gradient descent优化器
loss_fc = torch.nn.MSELoss() #采用均方误差损失函数
# we need to make some datas
x = torch.unsqueeze(torch.linspace(-1,1,100),dim = 1)
# linespace(start =-1,end = -1,step = 100,dtypde = float32)
# from start to end make 100 point of same interval type = dtype
y = x*x*x*3 + 0.2*torch.rand(x.size())
#x,y = Variable(x),Variable(y) if your torch version blow 0.4 you need to do this
# now we start to train our neural network
for i in range(130):
prediction = net(x)
loss = loss_fc(prediction,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 10 ==0:
print(loss)运行结果可以看到损失函数一直在减小
tensor(1.3570) tensor(0.4978) tensor(0.2996) tensor(0.1783) tensor(0.4922) tensor(0.2857) tensor(0.2148) tensor(0.1912) tensor(0.1606) tensor(0.1437) tensor(0.1419) tensor(0.1380) tensor(0.1188)
全连接网络:

如图,网络分为输入层、隐藏层,输出层,每一层都与前一层通过Weights链接。
激活函数:
In artificial neural networks, the activation function of a node defines the output of that node given an input or set of inputs. A standard computer chip circuit can be seen as a digital network of activation functions that can be "ON" (1) or "OFF" (0), depending on input. This is similar to the behavior of the linear perceptron in neural networks. However, only nonlinear activation functions allow such networks to compute nontrivial problems using only a small number of nodes. In artificial neural networks this function is also called the transfer function
个人理解:把神经网络的输出限制为一定的范围,比如logistic就把输出限定在了[ 0 ,1 ] ,tanh 限定输出在[ -1 , 1 ] , relu 是[ 0 ,+无穷]
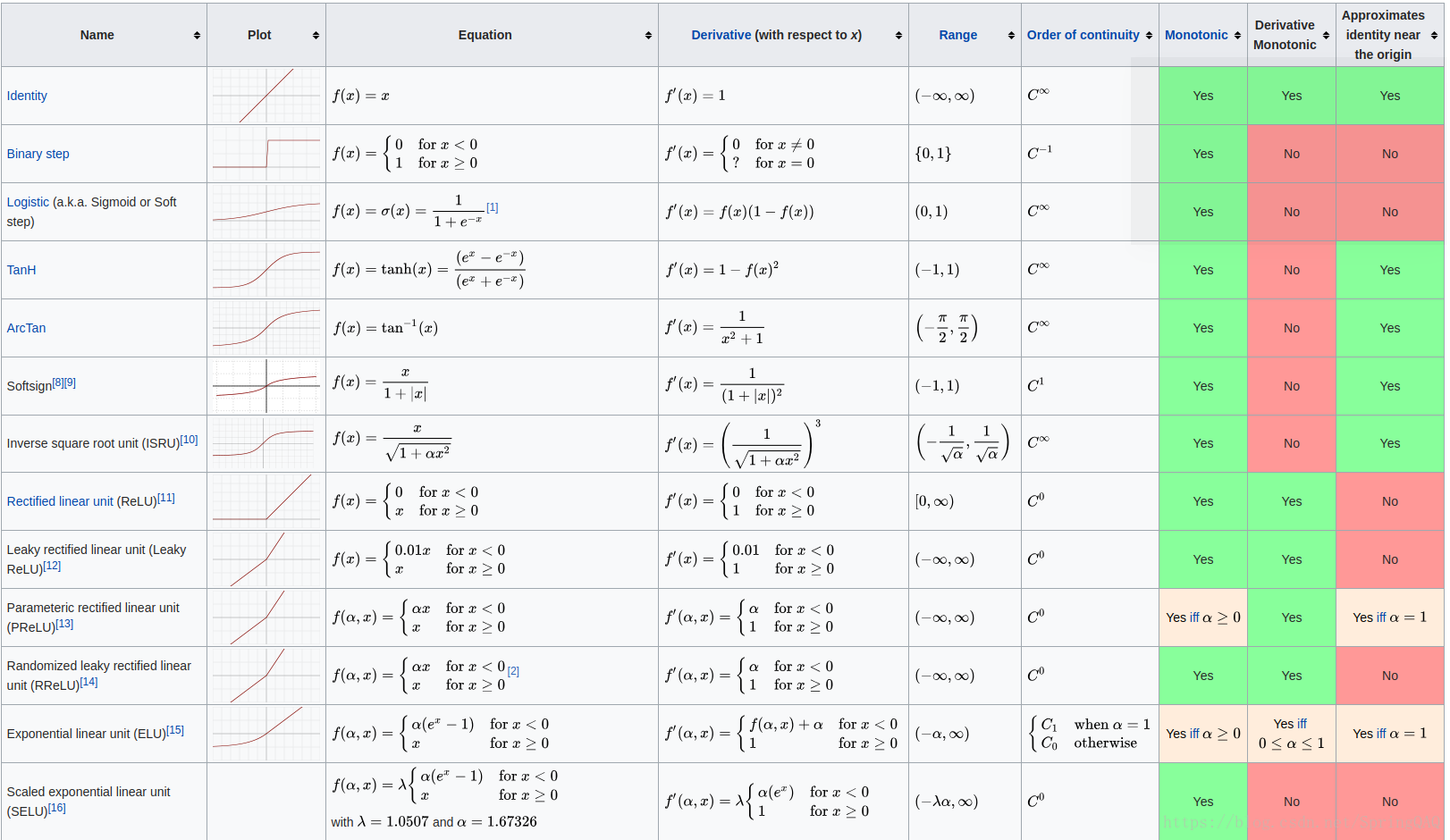
损失函数:印象中,学过的有均方误差,交叉熵,自定义
均方误差:

交叉熵:表示两个概率分布之间的距离。交叉熵越大,两个概率分布距离越远,两
个概率分布越相异;交叉熵越小,两个概率分布距离越近,两个概率分布越相似。
H(p , q) = −∑p∗ log(q)
eg: 比较点(0.9,0.1)和点(0.5,1)到点(1, 0)的距离
根据交叉熵的计算公式得:
H1((1,0),(0.9,0.1)) = -(1*log0.9 + 0*log0.1) ≈ 0.046
H2((1,0),(0.5,1)) = -(1*log0.5 + 0*log1) ≈0.301
看出H2 > H1 从数据中可以也可以看住(0.9,0.1)距离(1,0)更近
神经网络的层数 = 隐藏层+输出层
隐藏层的个数由什么决定? 如果隐藏层数太大会发生什么?1)增加隐藏层的数量可能会提高准确性,也可能不会,这实际上取决于您尝试解决的问题的复杂程度。
2)增加隐藏层的数量远远超过足够数量的层将导致测试集中的准确度降低,是的。这将导致您的网络过度适应训练集,也就是说,它将学习训练数据,但它无法推广到新的看不见的数据。增加隐藏层的数量可能会提高准确性,也可能不会,这实际上取决于您尝试解决的问题的复杂程度。
一直增加你的隐藏层会让你在训练数据上得到很小的loss,但是你无法预测未来的数据,也许问题本来适合你未增加时的层数,你增加了会是你的网络过度拟合 Overfiting 会使你的bias减小,但是var增大,而当你的隐藏层太少时,可能会使你的bias增大,var小一些。
可以看李宏毅宝可梦的例子~