优化指的是改变 以最大化或最小化某个函数 的任务.我们通常以最小化 指代大多数的最优化问题,最大化可以通过最小化 来实现。
- 我们通常把要最大化或者最小化的函数称为
目标函数(objective function)或者准则(criterion)。 - 我们通常使用一个上标 表示最小化或最大化函数的 值,如
在机器学习领域众多优化算法中,基于梯度的优化算法,是比较常用的一类。
首先,回忆一下微积分中 导数,偏导数,方向导数与梯度的关系。
对于一个一元函数 , 梯度就是导数。
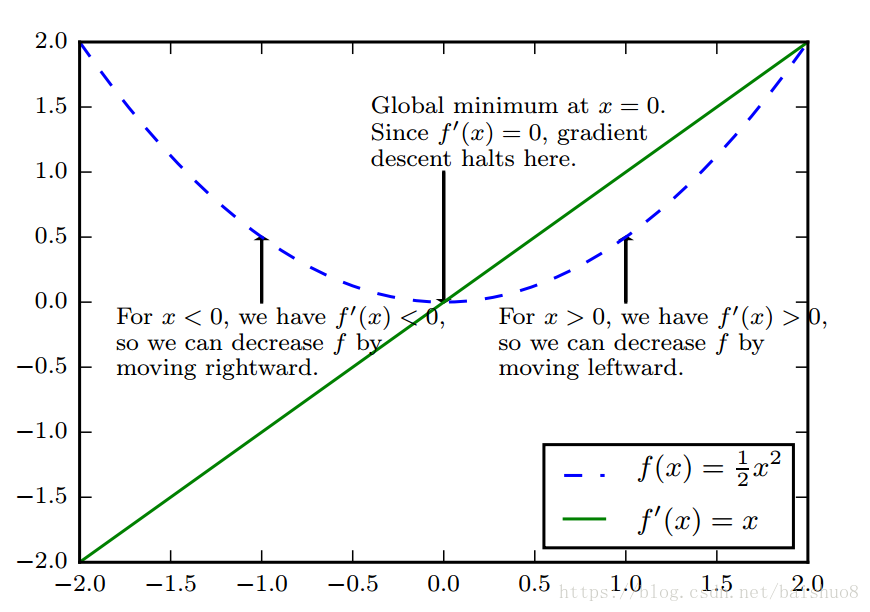
函数在某一点的导数
表示的是点
处的斜率,它表明了输入的微小变化如何影响输出的变化:
。导数对我们很有用,因为它可以告诉我们如何更改
来略微的改善
, 具体而言,我们想要找到
的最小值,沿着导数的负方向移动一个足够小的
, 得到的
肯定是比
要小的,我们就这样沿着导数的负方向一步一步挪来减小
, 去接近最低点。这种技术就是 梯度下降(gradient descent)。
当
时,导数无法提供往哪个方向移动的信息,这样的点被称为临界点(critical point) 或者驻点(stationary point)。一个临界点,可能是一个 局部极小点(local minimum), 也可能是一个 局部极大点(local maximum), 还有一类是既不极大也不极小,而是一边极大一边极小的鞍点(saddle point).
梯度下降法可以找到局部最小点,但我们的目标是找到函数定义域上的全局最小点(global minimum)。 函数本身可能有一个也可能有多个全局最小点,也有可能存在不是全局最优的全局极小点,更确切地说,在深度学习领域中,我们要优化的目标函数可能含有许多不是最优的全局极小点,或者还有很多处于非常平坦区域的鞍点。尤其是当输入是多维的情况下,所有这些情况会使得优化变得非常困难。我们通常寻找使得
非常小的点,不一定是那个精准的全局最小点,但是它足够小,已经满足我们的要求。
以上说了一维的情况了解概况,但是在实际中我们经常最小化的是具有多维输入的函数
. 为了使得最小化的概念有意义,我们必须保证输出是一个标量。
这时候我们就要用到 偏导数,方向导数和梯度的概念。之前我们已经知道,梯度向量指向上坡,负梯度方向指向下坡。我们在负梯度方向上移动
可以减小
.这被称为 最速下降法(method of steepest descent) 或 梯度下降(gradient descent) . 应用最速下降法,在
点处建议的下一个更新的点是
. 其中
是 学习率(learning rate), 是一个确定移动步长大小的正标量。
的选择是一个技术活儿,有几种不同的策略来找到最佳的
.
- 一种是直接设置为一个小常数。 – 这是普通青年的做法。
- 一种是通过计算,选择使得方向导数消失的步长。 – 这是解析青年的做法。
- 一种是根据几个 是试探计算 , 并选择其中能产生最小目标值函数值得 。 – 这是线搜索青年的做法。
最速下降法在梯度的每一个元素都为 的时候收敛(或者在实践中,很接近 时)。 在有些情况下,我们也许能够避免运行迭代求解,而是通过解方程 直接跳到临界点。
以上说的梯度下降法,都是针对连续空间中的优化问题,但是其背后的解决问题的思路 – 不断地向更好的情况移动一小步–可以拓展到离散空间。 例如,递增带有离散参数的目标函数被称作爬山算法(hill climbing).