1 梯度下降简单说明
想必大家对梯度下降或多或少有所了解,这里对他的原理就不再多说(其他教程说的比我好多了),只给出下列公式(按照吴恩达的深度学习课程中的公式):
上述公式中dW与db为权重W与偏置b的梯度方向,
为步长/学习速率,即一个超参。我们的任务就是通过大量数据的学习,来逼近真实的W和b。
1.1 随机梯度下降
该方法简写做SGD。通常,在数据集较少的情况下,我们一般使用批梯度下降,也就是用所有的数据集来进行求解。当数据量较多时,批梯度下降就不再适合,因为速度超级慢。所以我们在每次迭代时随机选取一个样本点来进行权重W、偏置b的更新。这样能保证权重随着迭代不断地逼近真实值。但要警惕,每次只是依靠当前一个数据集,容易陷入局部极小。
1.2 Mini-Batch梯度下降
此种方法可以看做批梯度下降与SGD的折中方法:在SGD中每次迭代时,不是选取1个样本点,而是选取M个样本点来进行梯度下降。此种方法的好处在于:若数据集中有一些噪音数据,可以有效的平均噪音数据的影响,一定程度上避免陷入局部极小值。据吴恩达深度学习课程介绍,M的选取也是有经验借鉴的。若数据集数量N<=2000,则M=1即可。若N很大,那么M的取值可以取2的K次方,即M={32,64,128,256,512}。
1.3 Momentum梯度下降
在说明此种方法之前,首先需要了解什么是指数加权平均。
假设有数据
,他们的平均数为:
则
若我们按照公式:
对第一式化简可得
通过(1.1)(1.2)之间的比较可以看到,(1.1)中每一项的权重都是一样的,也就是说每一项对平均值的贡献同样重要。而(1.2)中,每一项都不同,尤其是各数值的加权影响力随时间呈指数式递减,时间越靠近当前时刻的数据加权影响力越大。一般我们取
为0.9(详细的介绍请看下面参考文献)
把该思想应用到梯度下降中,就发明了动量梯度下降(Momentum),在每次迭代时需要先计算一下当前的动量梯度,然后用此动量梯度来进行更新权重。注意:我们需要设定初始的动量梯度
为0,此为冷启动问题,有时为了消除0的影响需要进行偏差修正:每次得到的
除以
,t为当前的迭代次数,当t较小时能赋予
较大权重,当t大时,该修正方法趋近于1,对动量结果影响微乎其微。下面是动量梯度更新的方法
吴恩达在这里说此处不需要设置偏差修正
至于为什么Momentum比传统的梯度下降快,可以参考吴恩达的深度学习教程。我个人理解是 当前的梯度下降方向参考了此前已经走过的梯度方向,受到了他们的影响,所以会比传统的梯度下降更快地逼近正确的方向。
1.4 RMSProp
全称为root mean square prop,均方根。我个人理解,此方法的目的是在参数值波动较大的方向上减少学习速率,在参数值波动较小的方向上加快学习速率,这样能更快地逼近极值点。此方法构造了一些式子来完成这个目标。
当dW小时,
同样会小,此时
变大,变相的增大了
,所以就会加速。反之,会减速。
通常取
,此为一个防止除法无意义的常量。
1.5 Adam优化算法
这个方法结合了Moment和RMSProp,Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳(参考文献[2])
废话不多说直接上公式
据吴恩达所述,一般
且不常修改。
与RMSProp一致。
2 Python代码及结果
#!/usr/bin/python
# -*- coding:utf-8 -*-
"""
Python 3.6
Author LiHao
Time 2018/10/12 10:28
"""
import numpy as np
import random
from math import sqrt
"""
验证梯度下降程序
"""
def random_num():
#读取随机数据 50个
data = []
func = lambda x:x**2+2*x+1+random.uniform(-0.3,0.3)
for i in np.arange(-5,5,0.2):
data.append([i,func(i)])
return data
class Gradient(object):
"""
利用数据求解 求解一元二次方程 x**2 + 2*x + 1的系数
分别利用
梯度下降法/Mini-Batch梯度下降法
动量梯度下降法
RMSProp
Adam
"""
def __init__(self,alpha = 0.001, error = 1e-03,A=0.1,B=0.1,C=0.1,data_num=100,max_iter=30000):
"""
:param alpha: 步长
:param error: 误差
:param maxcount: 最大迭代次数
"""
self._alpha = alpha
self._error = error
#读入数据并初始化各个系数
self.data_num = data_num
self._data = self.inputs()
#这里固定了为一元二次方程 x**2+2*x+1 _A _B _C 为真实系数
self.A = A
self._A = 1
self.B = B
self._B = 2
self.C = C
self._C = 1
self._max_iter = max_iter
def inputs(self):
datas = []
for i in range(self.data_num):
datas.extend(random_num())
#print("LH -*- 得到的数据个数:",len(datas))
return datas
def get_y_hat(self,mini_data):
"""
获取预测值 y^
:param mini_data:
:return:
"""
y_hat = self.A * np.power(mini_data[:,0],2) + self.B * mini_data[:, 0] + self.C
return y_hat
def gradient(self,mini_data,y_hat,m):
self.A = self.A - self._alpha * np.sum((y_hat-mini_data[:,1])*np.power(mini_data[:,0],2))/m
self.B = self.B - self._alpha * np.sum((y_hat-mini_data[:,1])*mini_data[:,0])/m
self.C = self.C - self._alpha * np.sum(y_hat-mini_data[:,1])/m
def minibatch_gradient_train(self,m=2,error=1e-02):
"""
minibatch-梯度下降
:param m:
:param error:
:return:
"""
self._error = error
all_lens = len(self._data)
if all_lens % m ==0:
epoch = int(all_lens/m)
else:
epoch = int(all_lens/m) + 1
Error = 1.0
count = 1
while(Error>self._error and count < self._max_iter):
#分批次求解 随机在数据集中选取一个epoch,里面含有m个数据,不满m的取剩余的数据
ie = random.randint(0,epoch-1)
mini_data = np.array(self._data[ie*m:(ie+1)*m],dtype=np.float32)
current_m = mini_data.shape[0]
y_hat = self.get_y_hat(mini_data)
Error = (abs(self.A - self._A) + abs(self.B - self._B) + abs(self.C - self._C)) / 3
#print("LH -*- epoch: ",ie,"\tloss : ",Error," A,B,C:",self.A,self.B,self.C)
self.gradient(mini_data,y_hat,current_m)
count += 1
print("LH -*- Minibatch -*-Final A,B,C,iter:",self.A,self.B,self.C,count," error:",Error)
def momentum_gradient(self,mini_data,y_hat,m,pre_va,pre_vb,pre_vc,beta):
“”“
动量梯度求解具体过程
”“”
da = np.sum((y_hat - mini_data[:, 1]) * np.power(mini_data[:, 0], 2)) / m
db = np.sum((y_hat - mini_data[:, 1]) * mini_data[:, 0]) / m
dc = np.sum(y_hat - mini_data[:, 1]) / m
va = da * (1 - beta) + beta * pre_va
vb = db * (1 - beta) + beta * pre_vb
vc = dc * (1 - beta) + beta * pre_vc
self.A = self.A - self._alpha * va
self.B = self.B - self._alpha * vb
self.C = self.C - self._alpha * vc
return va,vb,vc
def momentum_gradient_train(self,m=2,beta=0.9,error=1e-02):
"""
动量梯度下降
较之梯度下降更加快速
当前步的梯度与历史的梯度方向有关
:param m:
:param beta:
:param error:
:return:
"""
self._error = error
all_lens = len(self._data)
if all_lens % m == 0:
epoch = int(all_lens / m)
else:
epoch = int(all_lens / m) + 1
Error = 1.0
count = 1
pre_va = 0.0
pre_vb = 0.0
pre_vc = 0.0
while (Error >= self._error and count < self._max_iter):
ie = random.randint(0,epoch-1)
mini_data = np.array(self._data[ie * m:(ie + 1) * m], dtype=np.float32)
current_m = mini_data.shape[0]
y_hat = self.get_y_hat(mini_data)
Error =(abs(self.A-self._A)+abs(self.B-self._B)+abs(self.C-self._C))/3
#print("LH -*- epoch: ", ie, "\terror : ", Error, " A,B,C:", self.A, self.B, self.C)
pre_va,pre_vb,pre_vc = self.momentum_gradient(mini_data, y_hat, current_m,pre_va,pre_vb,pre_vc,beta)
count += 1
print("LH -*- Momentum -*-Final A,B,C,iter:", self.A, self.B, self.C, count, " error:", Error)
def rmsprop_gradient(self,mini_data,y_hat,m,pre_sa,pre_sb,pre_sc,beta,eps=10e-8):
da = np.sum((y_hat - mini_data[:, 1]) * np.power(mini_data[:, 0], 2)) / m
db = np.sum((y_hat - mini_data[:, 1]) * mini_data[:, 0]) / m
dc = np.sum(y_hat - mini_data[:, 1]) / m
sa = da**2 * (1 - beta) + beta * pre_sa
sb = db**2 * (1 - beta) + beta * pre_sb
sc = dc**2 * (1 - beta) + beta * pre_sc
self.A = self.A - self._alpha * da / (sqrt(sa) + eps)
self.B = self.B - self._alpha * db / (sqrt(sb) + eps)
self.C = self.C - self._alpha * dc / (sqrt(sc) + eps)
return sa, sb, sc
def rmsprop_gradient_train(self,m=2,beta=0.9,error=1e-02):
"""
RMSProp梯度下降
自适应更新学习速率
:param m:minibatch
:param beta:超参数
:param error:误差
:return:
"""
self._error = error
all_lens = len(self._data)
if all_lens % m == 0:
epoch = int(all_lens / m)
else:
epoch = int(all_lens / m) + 1
# 进行分批次求解
Error = 1.0
count = 1
pre_sa = 0.0
pre_sb = 0.0
pre_sc = 0.0
while (Error >= self._error and count < self._max_iter):
ie = random.randint(0,epoch-1)
mini_data = np.array(self._data[ie * m:(ie + 1) * m], dtype=np.float32)
current_m = mini_data.shape[0]
y_hat = self.get_y_hat(mini_data)
Error = (abs(self.A - self._A) + abs(self.B - self._B) + abs(self.C - self._C)) / 3
# print("LH -*- epoch: ", ie, "\terror : ", Error, " A,B,C:", self.A, self.B, self.C)
pre_sa, pre_sb, pre_sc = self.rmsprop_gradient(mini_data, y_hat, current_m, pre_sa, pre_sb, pre_sc,
beta)
count += 1
print("LH -*- RMSProp -*- Final A,B,C,iter:", self.A, self.B, self.C, count, " error:", Error)
def adam_gradient(self,mini_data,y_hat,m,pre_sa,pre_sb,pre_sc,pre_va,pre_vb,pre_vc,beta_1,beta_2,count,eps=10e-8):
#correct值归一化分母
norm_value_1 = 1-pow(beta_1,count)
norm_value_2 = 1-pow(beta_2,count)
#求da db dc
da = np.sum((y_hat - mini_data[:, 1]) * np.power(mini_data[:, 0], 2)) / m
db = np.sum((y_hat - mini_data[:, 1]) * mini_data[:, 0]) / m
dc = np.sum(y_hat - mini_data[:, 1]) / m
#求va vb vc
va = da * (1 - beta_1) + beta_1 * pre_va
vb = db * (1 - beta_1) + beta_1 * pre_vb
vc = dc * (1 - beta_1) + beta_1 * pre_vc
va_correct = va / norm_value_1
vb_correct = vb / norm_value_1
vc_correct = vc / norm_value_1
#求sa sb sc
sa = da ** 2 * (1 - beta_2) + beta_2 * pre_sa
sb = db ** 2 * (1 - beta_2) + beta_2 * pre_sb
sc = dc ** 2 * (1 - beta_2) + beta_2 * pre_sc
sa_correct = sa / norm_value_2
sb_correct = sb / norm_value_2
sc_correct = sc / norm_value_2
self.A = self.A - self._alpha * va_correct / (sqrt(sa_correct) + eps)
self.B = self.B - self._alpha * vb_correct / (sqrt(sb_correct) + eps)
self.C = self.C - self._alpha * vc_correct / (sqrt(sc_correct) + eps)
return va,vb,vc,sa,sb,sc
def adam_gradient_train(self,m=2,beta_1=0.9,beta_2=0.999,error=1e-02):
"""
adam优化算法
结合动量及RMSProp
:param m:minibatch
:param error:误差
:return:
"""
self._error = error
all_lens = len(self._data)
if all_lens % m == 0:
epoch = int(all_lens / m)
else:
epoch = int(all_lens / m) + 1
Error = 1.0
count = 1
pre_sa = 0.0
pre_sb = 0.0
pre_sc = 0.0
pre_va = 0.0
pre_vb = 0.0
pre_vc = 0.0
while (Error >= self._error and count < self._max_iter):
ie = random.randint(0, epoch-1)
mini_data = np.array(self._data[ie * m:(ie + 1) * m], dtype=np.float32)
current_m = mini_data.shape[0]
y_hat = self.get_y_hat(mini_data)
Error = (abs(self.A - self._A) + abs(self.B - self._B) + abs(self.C - self._C)) / 3
# print("LH -*- epoch: ", ie, "\terror : ", Error, " A,B,C:", self.A, self.B, self.C)
pre_va,pre_vb,pre_vc,pre_sa, pre_sb, pre_sc = self.adam_gradient(mini_data, y_hat,current_m, pre_sa, pre_sb,pre_sc,pre_va,pre_vb,pre_vc,beta_1,beta_2,count)
count += 1
print("LH -*- Adam -*- Final A,B,C,iter:", self.A, self.B, self.C, count, " error:", Error)
if __name__ == '__main__':
g = Gradient()
#分别测试不同的方法观察结果
#g.minibatch_gradient_train(m=64,error=0.002)
#g.momentum_gradient_train(m=64,error=0.002,beta=0.9)
g.rmsprop_gradient_train(m=64,error=0.002,beta=0.9)
#g.adam_gradient_train(m=64,error=0.002)
LH -*- Minibatch -*-Final A,B,C,iter: 0.9998391374256507 2.000062286798814 0.994375273081942 15357 error: 0.0019482761020684913
LH -*- Momentum -*-Final A,B,C,iter: 1.000219900542389 2.000187069910188 0.9944682440600149 10864 error: 0.0019906410380585346
LH -*- RMSProp -*- Final A,B,C,iter: 1.000128957762776 2.000499604490694 1.0035405980946732 2109 error: 0.0017750440141715007
LH -*- Adam -*- Final A,B,C,iter: 1.000215617975376 2.0007904489544006 1.004995565781187 5911 error: 0.0019990631734925213
观察结果发现RMSProp最快,其次是Adam,然后是Momentum,最后是一般的梯度下降。
据吴恩达所说,目前最广泛使用的优化算法Adam,也是最稳定的一种。
下面从参考文献[3]中截取了两个动图,形象的说明了各个算法的速度
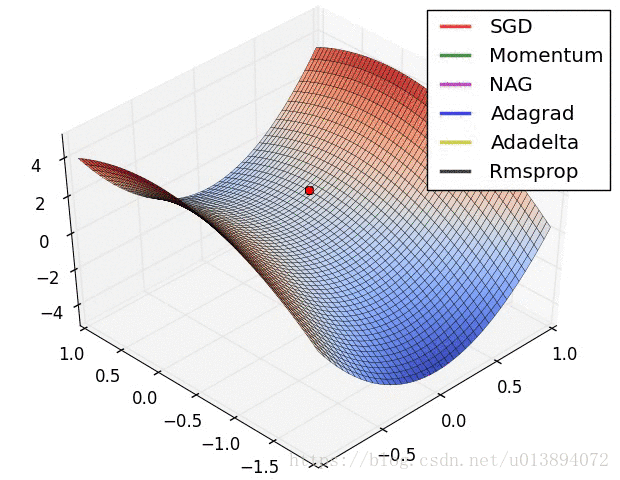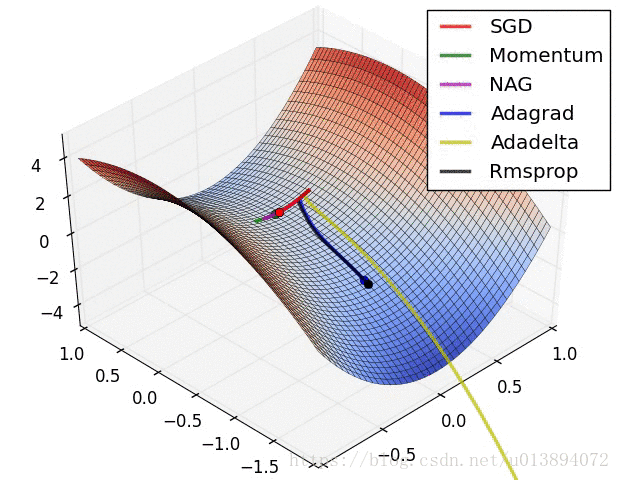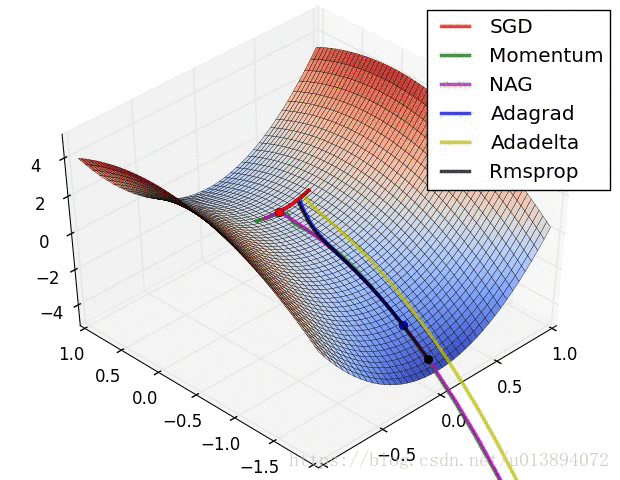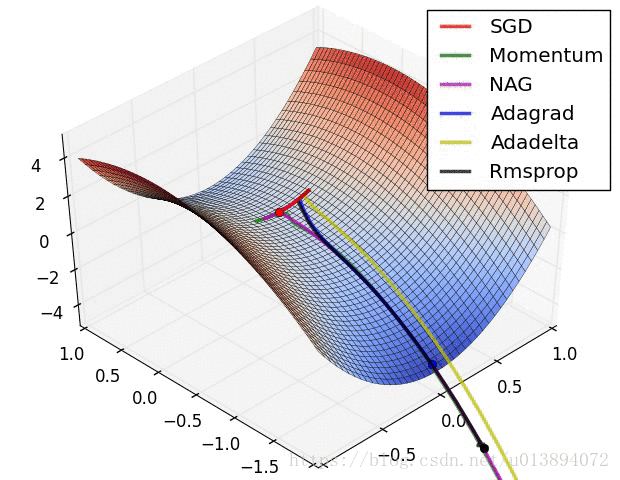
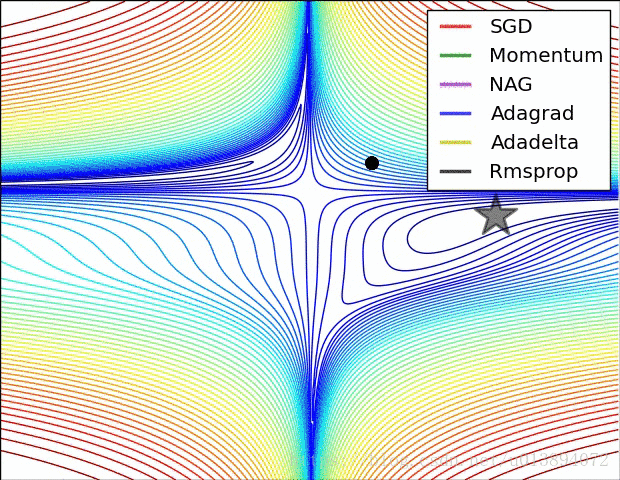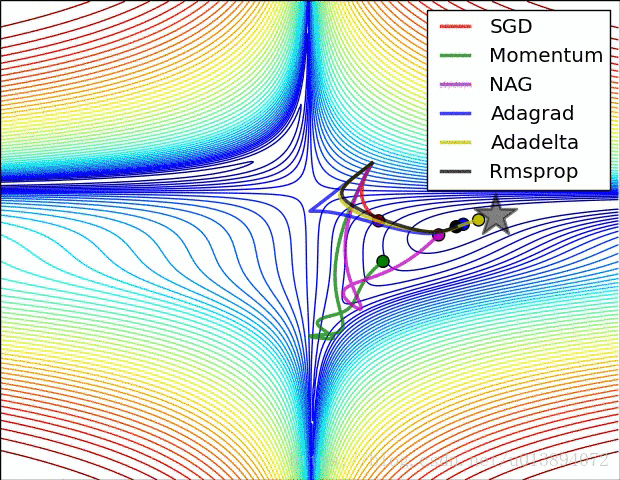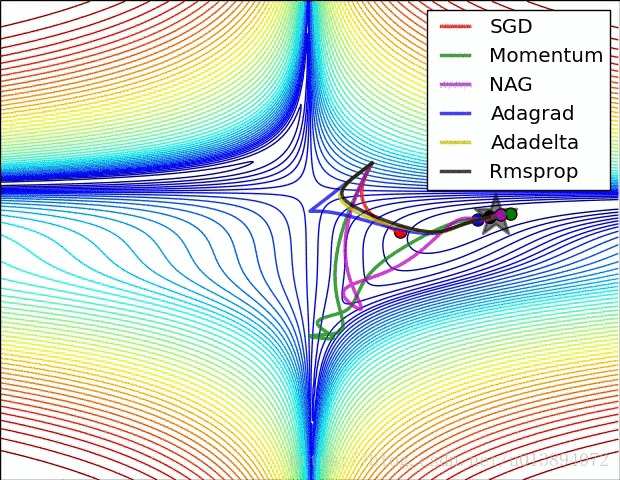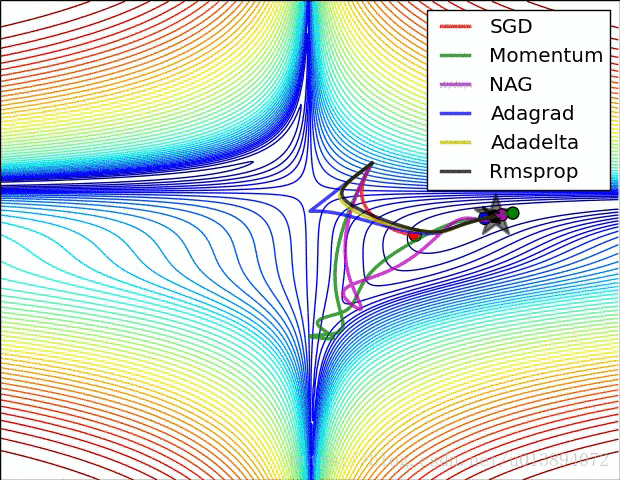
参考文献:
1.吴恩达.深度学习课程笔记v5.54.pdf(黄海广整理)
2.https://blog.csdn.net/u014595019/article/details/52989301
3.http://cs231n.github.io/neural-networks-3/