spark-wordcount详解、数据流向:

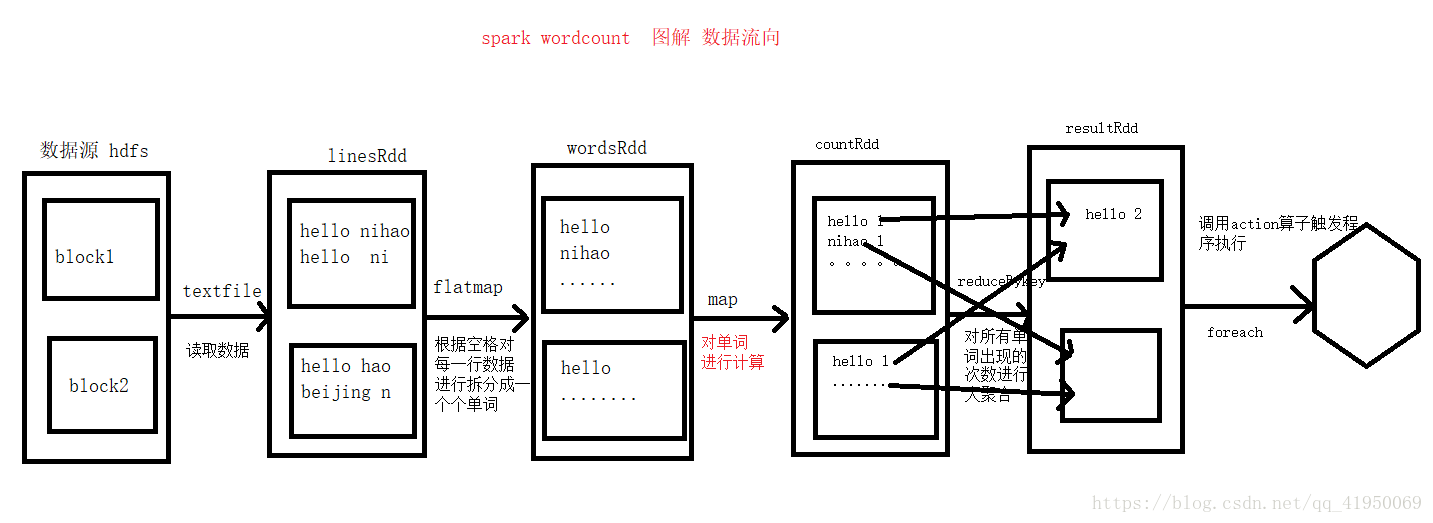
单个maptask:首先通过sc.textfile()将数据读取出来放在linesRdd里,然后通过flatMap算子进行拆分到wordsRdd中,然后通过map算子对单词进行计数到countRdd中,然后通过reduceBykey对所有countRdd中单词出现的次数进行大聚合到resultRdd中,最后调用action算子触发程序执行。
spark-map系列算子:
mappartitions:分区处理,以一个分区为单位
mappartitionwithIndex:
补充:collect算子:action算子也就是执行算子,是将所有rdd计算的结果收集起来