一、基本介绍
rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值
3代表每次分完组之后的每个组的初始值。
seqFunc代表combine的聚合逻辑
每一个mapTask的结果的聚合成为combine
combFunc reduce端大聚合的逻辑
ps:aggregateByKey默认分组
二、源码
三、代码
from pyspark import SparkConf,SparkContext
from __builtin__ import str
conf = SparkConf().setMaster("local").setAppName("AggregateByKey")
sc = SparkContext(conf = conf)
rdd = sc.parallelize([(1,1),(1,2),(2,1),(2,3),(2,4),(1,7)],2)
def f(index,items):
print "partitionId:%d" %index
for val in items:
print val
return items
rdd.mapPartitionsWithIndex(f, False).count()
def seqFunc(a,b):
print "seqFunc:%s,%s" %(a,b)
return max(a,b) #取最大值
def combFunc(a,b):
print "combFunc:%s,%s" %(a ,b)
return a + b #累加起来
'''
aggregateByKey这个算子内部肯定有分组
'''
aggregateRDD = rdd.aggregateByKey(3, seqFunc, combFunc)
rest = aggregateRDD.collectAsMap()
for k,v in rest.items():
print k,v
sc.stop()
四、详细逻辑
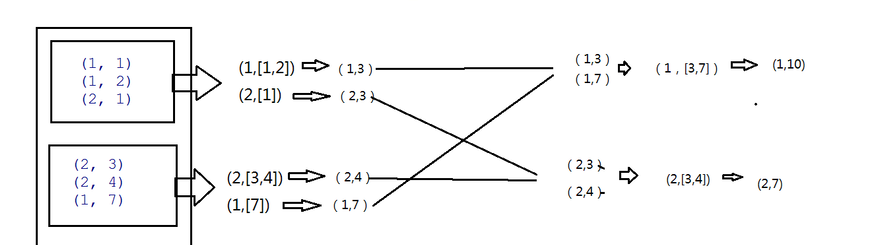
PS:seqFunc函数 combine篇。
3是每个分组的最大值,所以把3传进来,在combine函数中也就是seqFunc中第一次调用 3代表a,b即1,max(a,b)即3 第二次再调用则max(3.1)中的最大值3即输入值,2即b值 所以结果则为(1,3)
底下类似。combine函数调用的次数与分组内的数据个数一致。
combFunc函数 reduce聚合
在reduce端大聚合,拉完数据后也是先分组,然后再调用combFunc函数
五、结果
